


Algoritmi
Universit`a di Verona
Imbriani Paolo -VR500437
Professor Roberto Segala
July 22, 2025
1























































































Studia grazie alle numerose risorse presenti su Docsity

Guadagna punti aiutando altri studenti oppure acquistali con un piano Premium

Prepara i tuoi esami
Studia grazie alle numerose risorse presenti su Docsity
Prepara i tuoi esami con i documenti condivisi da studenti come te su Docsity
Trova i documenti specifici per gli esami della tua università
Preparati con lezioni e prove svolte basate sui programmi universitari!
Rispondi a reali domande d’esame e scopri la tua preparazione
Riassumi i tuoi documenti, fagli domande, convertili in quiz e mappe concettuali
Studia con prove svolte, tesine e consigli utili
Togliti ogni dubbio leggendo le risposte alle domande fatte da altri studenti come te
Esplora i documenti più scaricati per gli argomenti di studio più popolari
Ottieni i punti per scaricare
Guadagna punti aiutando altri studenti oppure acquistali con un piano Premium
Questo documento fornisce un'analisi approfondita degli algoritmi, coprendo vari tipi di algoritmi di ordinamento, strutture dati e tecniche di programmazione. Viene discusso il concetto di complessità computazionale e si presentano esempi pratici di applicazione degli algoritmi in contesti reali. Concetti chiave Algoritmi di Ordinamento: Tecniche per ordinare dati, come QuickSort e MergeSort. Complessità Computazionale: Studio del tempo e delle risorse necessarie per eseguire algoritmi. Strutture Dati: Organizzazione dei dati per un accesso e una manipolazione efficienti, come alberi e grafi. Programmazione Dinamica: Tecnica per risolvere problemi complessi suddividendoli in sottoproblemi più semplici. Grafi: Rappresentazione di relazioni tra oggetti, utilizzata in vari algoritmi per la ricerca di percorsi e flussi. Teorema di Master: Strumento per analizzare la complessità di algoritmi ricorsivi.
Tipologia: Dispense
1 / 102

Questa pagina non è visibile nell’anteprima
Non perderti parti importanti!
Ci sono diverse definizioni di ’algoritmo’ ma quella piu semplice per definirloe una sequenza di istruzioni volta a risolvere un problema. In maniera piu semplice, possiamo definirlo come una ricetta. Le ricette sono delle istruzioni per creare dei piatti: queste istruzioni sono precise tuttavia possono avere anche delle varianti. Il problema none trovare la ricetta, ma capire quale sia quella gisuta da utilizzare in base al problema posto.
In questo corso impararemo come decidere. Studiare i diversi approcci e il metodo migliore per affrontare un problema. Capiremo come confrontare gli algoritmi fra di loro.
Classifichiamo gli algoritmi in base alla loro complessita ovvero quanto tempo ci mettono per essere completati. Il nostro obiettivoe quello non di misurare il tempo in se (poich´e puo dipendere dal tipo di macchina che utilizziamo) che impiega un programma a finire ma piuttosto capire il numero di istruzioni elementari che vengono impiegate per risolvere il problema.
La complessita none un numero bensı una funzione, poich´e mappa la dimensione del problema in numero di istruzioni da eseguire. Per esempio, quando si parla di dimensione di una matrice ci si viene piu comodo vedere il numero di colonne e righe piuttosto che contare il numero di elementi all’interno della matrice. La dimensione del problema `e un insieme di oggetti, tipicamente un insieme di numeri che ci permette di avere un idea chiara di capire quanto sia grande il problema. Se riusciamo a misurarlo bene, potremmo facilitarci la vita nel risolvere il problema.
E doveroso stare attenti a cosa moltiplichiamo:^ se moltiplichiamo due vettori, il numero di operazioni da eseguiree esattamente n. Mentre se fossero orgnanizzate in matrici quadrate con lunghezza del lato √ n la sua complessit`a andrebbe ad aumentare a O ( n √ n ). Come si rappresentano le istruzioni di un programma? Se sono in serie:
I 1 c 1 ( n ) I 2 c 2 ( n ) .. . Il cl ( n )
Dove la complessita totale allora sara: ∑ l i =
ci ( n )
oppure all’interno di un costrutto if-else:
if cond c cond( n ) I 2 c 1 ( n ) else Il c 2 ( n )
In questo caso, come faccio a sapere la complessita totale di questi istruzioni? Per capirlo, studiamo il caso nel _worst case scenario_ ovvero nel caso peggiore. A volte vengono mostrati anche i casi migliore ma di solito si calcola il tempo peggiore. Quindi ci interessa specialmente il _limite superiore_ dell’algoritmo, quindi piuttosto che dire che la complessita e esattamente **uguale** questo numero, invece noi diremo chee minore o uguale del numero calcolato.
C ( n ) = c cond( n ) + max ( c 1 ( n ) , c 2 ( n ))
Mentre per un while loop? while cond ccond ( n ) I c 0 ( n ) Sia m limite superiore numero di iterazioni che esegue l’algoritmo. La complessita di questo algoritmo quindi sara: C ( n ) = ccond ( n ) + m ( ccond ( n ) + c 0 ( n )) Proviamo ora a calcolare la molteplicazioni tra matrici. Siano due matrici A e B rispettivamente con dimensione n x m e m x l.
1 For i <- 1 to n 2 For j <- 1 to l 3 C [ i ][ j ] <- 0 4 For k <- 1 to m 5 C [ i ][ j ] += A [ i ][ j ] * B [ k ][ j ]
Avere un risultato del tipo 5 m + 1 (riguardo il for piu interno)e inutile perch´e non ci da in- formazioni realmente utili sulla complessit`a dell’algoritmo. Ad ogni modo contando tutti i for, avremo un risultato del tipo:
n (5 ml + 4 l + 2) + n + 1 = 5 nml + 4 nl + 3 n + 1 Ci sono alcuni elementi in questa operazioni che non influiscono realmente sul risultato finale. Indi per cui, possiamo anche ometterlo all’interno del calcolo della complessita di un algoritmo. In realta cio che ci interessa realmente nel risultato finalee:
5 nml + 4 nl + 3 n + 1
Infatti nml e capace di dirci tutto sulla complessita dell’algoritmo e da cosa dipende. Quando
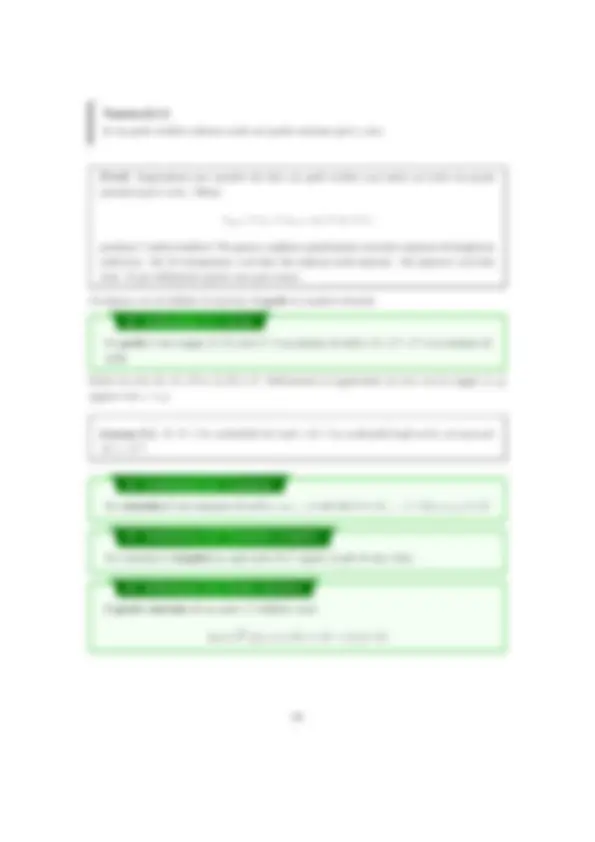
Definition 1.3. f ∈ Θ( g ) ⇐⇒ f ∈ O ( g ) ∧ f ∈ Ω( g )
Figure 3: f ∈ Θ( g )
n
x
c 1 g ( n ) , c 2 g ( n ) , f ( n )
Ò Esempio 1. Questa affermazione vale? n ∈ O (2 n )
S`ı, perch´e esiste un c che soddisfa n ≤ c 2 n.
Quest’altra affermazione vale? 2 n ∈ O ( n )
S`ı perch´e esiste un c che soddisfa 2 n ≤ 2 n.
Ò Esempio 1. Questa affermazione vale? f ∈ O ( g ) ⇐⇒ g ∈ Ω( g ) Proviamo a dimostrare. Sappiamo che esiste un c e n tale che ∀ n > n f ( n ) ≤ cg ( n ). Isoliamo la g: g ( n ) ≥ (^1) c f ( n )
Esiste quindi un c’ che soddisfa la disuguaglianza.
c ′^ =^1 c
Esempio 3
f 1 ∈ O ( g ) , f 2 ∈ O ( g ) =⇒ f 1 + f 2 ∈ O ( g ) Dobbiamo dimostrare che esiste c 1 e c 2 , n 1 e n 2 tali che:
∀ n > n 1 | f 1 ( n ) ≤ c 1 g ( n )
∀ n > n 2 | f 2 ( n ) ≤ c 2 g ( n ) Quindi n = max ( n 1 , n 2 )
f 1 ( n ) + f 2 ( n ) ≤ ( c 1 + c 2 ) g ( n )
Esempio 4
f 1 ∈ O ( g 1 ) , f 2 ∈ O ( g 2 ) | f 1 f 2 ∈ O ( g 1 g 2 ) Quindi esiste c 1 e c 2 , n 1 e n 2 tali che:
∀ n > n 1 | f 1 ( n ) ≤ c 1 g ( n )
∀ n > n 2 | f 2 ( n ) ≤ c 2 g ( n )
f 1 ( n ) f 2 ( n ) ≤ c 1 g 1 ( n ) c 2 g 2 ( n ) f 1 ( n ) f 2 ( n ) ≤ c 1 c 2 g 1 ( n ) g 2 ( n ) Quindi: c = c 1 c 2
n = max ( n 1 , n 2 )
L’algoritmo di ricerca A termina entro n. Immaginiamo che l’algoritmo A sia il seguente:
1 For i <- 0 to length ( a ) - 1 2 if a [ i ] = x 3 ret i
arrivare e un array ordinato al contrario con complessita uguale a:
1 + 2 + 3 + ... + n = n ( n^ 2 + 1) ∈ Θ( n^2 )
Questo algoritmo, quanto spazio di memoria usa in pi`u rispetto allo spazio occupato dai dati?
Lo spazio di memoria di questo algoritmo rimane costante a prescindere dalla dimensione del problema. Un algoritmo del genere si dice che ordina in loco se la quantita di memoria extrae costante. Si parla di stabilit`a di un algoritmo di ordinamento quando l’ordine relativo di elementi uguali non viene scambiato dall’algoritmo. Quindi:
Se ai = aj i < j, mantiene l’ordinamento
1 Fatt ( n ) 2 if n = 0 3 ret 1 4 else 5 ret n * fatt ( n - 1)
L’argomento della funzione ci fa capire la complessit`a dell’algoritmo:
T ( n ) =
1 se n = 0 T ( n − 1) + 1 se n > 0
Con problemi ricorsivi si avra una complessita con funzioni definite ricorsivamente. Questo si risolve induttivamente: T ( n ) = 1 + T ( n − 1) = 1 + 1 + T ( n − 2) = 1 + 1 + 1 + T ( n − 3) = 1 + 1 + ︸ ︷︷... + 1︸ i
La condizione di uscita `e: n − i = 0 n = i
= 1 + 1 + ︸ ︷︷... + 1︸ n
= n + 1 = Θ( n )
Questo si chiama passaggio iterativo.
Esempio 1
T ( n ) = 2 T
(⌊ (^) n 2
Questa funzione si pu`o riscrivere come:
T ( n ) =
Costante se n < a 2 T
(⌊ (^) n 2
Se la complessita fosse gia data bisognerebbe soltanto verificare se `e corretta. Usando il metodo di sostituzione: T ( n ) = cn log n
sostituiamo nella funzione di partenza:
T ( n ) = 2 T
(⌊ (^) n 2
(⌊ (^) n 2
log
⌊ (^) n 2
log n 2 + n = cn log n − cn log 2 + n ? ≤ cn log n se n − cn log 2 ≤ 0
c ≥ (^) n log 2 n = (^) log 2^1
Il metodo di sostituzione dice che quando si arriva ad avere una disequazione corrispon- dente all’ipotesi, allora la soluzione `e corretta se soddisfa una certa ipotesi.
Esempio 2
T ( n ) = T
(⌊ (^) n 2
(⌈ (^) n 2
T ( n ) ≤ cn T ( n ) = T
(⌊ (^) n 2
(⌈ (^) n 2
≤ c
(⌊ (^) n 2
(⌈ (^) n 2
= c
(⌊ (^) n 2
⌈ (^) n 2
= cn + 1
? ≤ cn
Il metodo utilizzato non funziona perche rimane l’1 e non si puo togliere in alcun modo.
Si pu`o togliere l’approssimazione per difetto per ottenere un maggiorante:
≤ n
)log 4 n − 1 )
≤ n
i =
) i )
Per capire l’ordine di grandezza di 3log^4 n^ si pu`o scrivere come:
3 log^4 n^ = n (log n^^3 log^4 n ) = n log^4 n ·log n^^3 = n log^4
Quindi la complessitae: = O ( n ) + O ( n log^4 3 ) Si ha che una funzione e uguale al termine noto della funzione originale e l’altra chee uguale al logaritmo dei termini noti. Se usassimo delle variabili uscirebbe:
T ( n ) = aT
(⌊ (^) n b
Data una relazione di occorrenza di questa forma:
T ( n ) = aT
(⌊ (^) n b
f ( n ) ∈ O ( n log b^ a − ϵ ) =⇒ T ( n ) ∈ Θ( n log b^ a )
f ( n ) ∈ Θ( n log b^ a ) =⇒ T ( n ) ∈ Θ( f ( n ) log n )
f ( n ) ∈ Ω( n log b^ a + ϵ ) =⇒ T ( n ) ∈ Θ( f ( n ))
Esempio 1
T ( n ) = 9 T
( (^) n 3
Basta che trovo un ϵ che mi dia n.
n log b^ a^ = n log^3 9 = n^2 ∗ n −^12
In questo caso ϵ = n −^12 e ci troviamo nel PRIMO CASO e la soluzione `e T ( n ) ∈ Θ( n^2 ).
Esempio 2
T ( n ) = T
( (^2) n 3
a = 1 , b =^32 , f ( n ) = n^0
n log b^ a^ = n log^321 = n^0
Ci troviamo nel SECONDO CASO e la soluzione `e T ( n ) ∈ Θ(log n ))
Esempio 3
T ( n ) = 3 T
( (^) n 4
Ci troviamo nel TERZO CASO quindi basta qualsiasi valore di ϵ basta che sia contenuto tra log 3 4 ≤ ϵ ≤ 1. La soluzione `e T ( n ) ∈ Θ( n log n ).
Esempio 4
T ( n ) = 2 T
( (^) n 2
n log n ∈ Ω( n 1+
? ϵ )
log n ∈ Ω( nϵ ) NON VALE Poich´e un logaritmo e sempre piu piccolo di un polinomio. Questo `e un caso dove il teorema non si applica
Questo algoritmo di ordinamento ricorsivo utilizza il concetto di divide et impera. Concettualmente, un merge sort funziona come segue:
Propriet`a Heap:
∀ nodo, il contenuto `e ≥ del contenuto dei figli
La complessita dell’algoritmoe in base al numero di livelli dell’albero.
−→ albero con n livelli:
#Nodi = 2^0 + 2^1 + 2^2 + ... + 2 n −^1 =^1 −^2
n 1 − 2 = 2
n (^) − 1
−→ albero con n nodi: #Livelli = log 2 n #Foglie = n 2
Le foglie di un albero sono la met`a dei nodi dell’albero. 1 extractMax ( H ) // O ( log n ) 2 h [1] <- H [ H. heap_size () ] 3 H. heap_size () -- 4 heapify (H , 1) 1 heapify (H , 1) // O ( log n ) 2 l <- left [ i ] // 3 r <- right [ i ] 4 if ( l < h. heap_size () AND H [ l ] > H [ i ] 5 largest <- l 6 else 7 largest <- i 8 if m <= h. heap_size () and H [ r ] > H [ largest ] 9 largest <- r 10 if largest! = i 11 swap ( H [ i ] , H [ largest ]) 12 heapify (H , largest )
Creare uno heap da un array: 1 buildHeap ( A )
2 A. heap_size () <- length [ A ] 3 for i <- length [ A ]/2 down to 1 4 heapify (A , i )
Immagino tutte le foglie come heap con un solo nodo. L’indice del primo nodo che non `e heap corrisponde a length 2 ( A )su questo allora chiamo heapify.
Scegliamo un elemento a caso in base a quello comparato rispetto all’elemento perno tale che:
sx ≤ perno ≤ dx
Questo algoritmo non e **stabile** ma lavora **in loco**. La sua complessita?
T ( n ) = T (partition) + T ( q ) + T ( n − q )
Se il quicksort e perfettamente diviso in due, allora la sua complessita e _O_ ( _n_ log _n_ ). Se invece l’arraye gia ordinato la sua equazione di ricorrenza sara:
= n + T (1) + T ( n − 1) = Θ( n^2 )
Tuttavia non ci aspettiamo che questo caso sia frequente e quindin nella stra grande maggioranza dei casi allora: T ( n ) = n + T ( cn ) + T ((1 − c ) n )
Un equazione di questo tipo sappiamo che ha come complessit`a Θ( n log n ).
1 rand_Partition (A , p , r ) 2 i <- rand ( p .. r ) // Ora l ' elemento perno e ' un elemento a caso 3 scambio ( A [ p ] , A [ i ] 4 ret partition (A , p , r )
T ( n ) = n + n^1 ( T (1) + T ( n − 1) +^1 n ( T (2) + ( T − 2)) +... + 1 n ( T^ ( n^ −^ 2) +^ T^ (2)) +
n ( T^ ( n^ −^ 1) +^ T^ (1) = = n + n^1
i
( T ( i ) + T ( n − i ))
= n + n^2
i
T ( i ) ∈ O ( n log n )
Qualsiasi algoritmo che lavora per confronti deve fare almeno O ( n log n ).
3.1.1 Counting Sort Tuttavia possiamo trovare algoritmi che come tempo di esecuzione hanno tempo lineare. Come? Non lavorando a confronti.
Come ordinare n numeri con valori da 1 a k? 1 countingSort (A , k ) 2 for i <- 1 to k 3 C [ i ] <- 0 4 for j <- 1 to len ( A ) 5 C [ A [ j ]]++ 6 for i <- 2 to k 7 C [ i ] <- C [i -1]+ C [ i ] 8 for j <- len ( A ) down to 1 9 B [ C [ A [ j ]]] <- a [ j ] 10 C [ A [ J ]] - -
La complessita di questo algoritmoe O ( n + k ) dove n `e la lunghezza dell’array e k e il range di valori.
3.1.2 Radix Sort Il radix sort e un algoritmo di ordinamento che ordina gli elementi confrontando i singoli bit. Quello che fae ordinare per la cifra meno significativa, poi per la seconda cifra meno significativa e cosı via. 1 radixSort (A , d ) // O ( d ( n + k ) ) 2 for i <- 1 to d 3 countingSort (A , n ) La complessita di questo algoritmo e Θ( _d_ ( _n_ + _k_ )) dove _d_e il numero di cifre e k e il range di valori. Se si vuole invece ordinare _n_ valori da 1 a _n_^2 −1, le costanti nascoste all’interno del Θ sono molto alte e quindi none un algoritmo efficiente. Tuttavia si posson rappresentare i numeri in base n e quindi ottenere un algoritmo lineare.
3.1.3 Bucket Sort Il Bucket Sort e un algoritmo di ordinamento applicabile quando la distribuzione dei datie nota. Quindi su un array di n elementi distribuiti uniformemente su [0 , 1), si puo dividere l’intervallo in _n_ sottointervalli con probabilita (^1) n e poi ordinare i singoli sottointervalli chia- mate anche ”Bucket”. Infatti se i dati sono distribuiti uniformemente allora la complessita dell’algoritmoe lineare: Θ( n ) Questo perch´e in ogni bucket ci si aspetta un valore costante e quindi indipendente dal valore di n.
Il caso pessimo peroe quando tutti gli elementi ricadono nello stesso bucket. La probabilit`a