Scarica Algoritmi: Definizione e Proprietà e più Appunti in PDF di Informatica gestionale solo su Docsity!
A L G O R I T M I
T E O R I A D E L L A C O M P U T A B I L I T À
I manuali accademici introducono spesso gli algoritmi a partire dalla teoria della
computabilità. Questo approccio ha le sue motivazioni storico-culturali legate, in gran
parte, al contributo fondamentale dato da Alan Turing alla genesi e allo sviluppo della
disciplina della Computer Science, ma comporta il rischio di una presentazione riduttiva
della ampiezza e varietà di compiti che vengono oggi affrontati ricorrendo alla progettazione
algoritmica. Vediamo la questione con maggior dettaglio.
Nel suo lavoro seminale del 1937, pubblicato con il titolo On computable numbers, with an
application to the Entscheidungsproblem [1], Alan Turing si pone l’obiettivo di definire un
criterio per stabilire se una funzione sia calcolabile in modo effettivo, ovvero attraverso un
procedimento meccanico (in altre parole, se sia possibile, per ogni valore atteso degli
argomenti, calcolare correttamente il risultato senza ricorrere a procedimenti non
meccanici). Turing affrontò il problema in modo molto diretto, senza ricorrere a nozioni
matematiche preesistenti. Il suo approccio parte dalla definizione di una classe di
macchine astratte , dette in seguito macchine di Turing (MT). Una funzione si dirà
calcolabile se esiste una MT in grado di computarla. Se il lettore ha notato una
circolarità nella definizione è perché esiste. Quella di Turing non è una dimostrazione
matematica (verrà infatti chiamata Tesi di Church-Turing in seguito alla dimostrazione di
equivalenza tra i risultati di Turing e quelli di Church riguardo alle funzioni ricorsive come
modello di computabilità effettiva) ma la sua tesi potrà essere smentita solo trovando una
funzione calcolabile non eseguibile attraverso una MT, e questo, per ora, non è avvenuto.
Un esempio di funzione calcolabile è una funzione per generare la sequenza dei numeri naturali oppure una
funzione che trova la lista dei fattori primi di un numero. Contrariamente a quanto potrebbe apparire in un primo
momento, alcuni numeri irrazionali possono essere ottenuti attraverso funzioni calcolabili. Sono ad esempio
calcolabili numeri irrazionali quali √2, π, e. Ricordiamo che un numero è detto irrazionale se non può essere
espresso come rapporto tra due numeri interi, ovvero se la sua espansione decimale non si ripete né termina.
L’intuizione di Turing si forma probabilmente nell’osservazione di questo fatto. Alcuni numeri sono detti calcolabili
anche se la serie di cifre che li descrive procede all’infinito perché conosciamo una procedura finita per generare
questa sequenza. Naturalmente tutte le procedure che generano sequenze infinite si considerano effettive dato
un certo livello di dettaglio, ovvero un numero massimo di elementi da generare, questo massimo non è tuttavia
determinato dalla procedura stessa, che potrebbe teoricamente essere eseguita all’infinito, ma dal tempo a
disposizione per il calcolo. Quindi per stabilire che una funzione è non calcolabile non è sufficiente verificare che
generi una sequenza infinita di elementi. Fornire esempi di funzioni non calcolabili non è semplice, proprio in
ragione del fatto che non conosciamo procedure effettive che le descrivono. In generale possiamo dire che le
funzioni non calcolabili sono tali in quanto dovrebbero generare numeri o strutture totalmente casuali e quindi non
riducibili ad una regolarità che possa essere catturata da una procedura. Esempi che si potrebbero approfondire
per migliorare la propria comprensione di questa nozione sono il problema dei tasselli di Wang, la dimostrabilità
delle proprietà semantiche di un algoritmo (Teorema di Rice) o la funzione dell'alacre castoro (busy beaver) che
quantifica il limite superiore di passi necessari a una MT di una data classe.
In sostanza, una MT è un dispositivo che può leggere e scrivere un simbolo alla volta
scorrendo un nastro infinito (muovendosi o a destra o a sinistra) e seguendo un programma.
Un programma è una procedura data da un insieme di regole, o istruzioni, che determinano
quale operazioni la macchina debba eseguire in relazione ad uno stato interno, che può
essere aggiornato sulla base delle operazioni di lettura o scrittura prodotte, e al simbolo
correntemente letto dalla macchina. Un esempio di regola che potrebbe istruire una MT è la
seguente: se ti trovi nello stato 3 e leggi dal nastro il simbolo A, modifica il simbolo scrivendo sul nastro
B , in seguito spostati a sinistra e aggiorna lo stato a 2. Su Wikipedia è presente un efficace esempio
di MT.
Per mantenere conformità con la definizione di Turing molti manuali definiscono un
algoritmo attraverso le proprietà di una MT (per la verità utilizzando criteri stabiliti da
studiosi successivi a Turing). Questo è del tutto corretto se riteniamo che la nozione di
algoritmo coincida totalmente con la nozione di funzione calcolabile. Ma come notato da
Yuri Gurevich, nella pratica professionale dell’informatica si parla di algoritmi anche con
riferimento a procedure che non hanno l’obiettivo di interpretare delle funzioni
calcolabili (ma più semplicemente delle sequenze di istruzioni) o che potrebbero essere
rappresentate da una MT solo attraverso un’irragionevole sforzo di modellazione (ad
esempio nel caso del calcolo parallelo o di procedure indeterministiche). La tesi di Gurevich
è che il modello di Turing sia adatto alle funzioni calcolabili ma non agli algoritmi, intesi
come procedure specificate nella pratica dell’informatica [2]. Nella pratica della
modellazione un algoritmo non è dato unicamente dalla funzione che calcola ma da come
questa interagisce con altri algoritmi e sistemi. Per capire più concretamente
l’argomentazione di Gurevich proviamo a guardare nel dettaglio la definizione di algoritmo.
Consultando manuali diversi è facile riscontrare differenze nelle modalità con le quali è
definita o anche solo presentata la nozione di algoritmo. Ci si può rendere conto della
eterogeneità degli approcci anche solo consultando le definizioni proposte nei dizionari.
Alcuni pongono l’accento sulla relazione tra algoritmo e problema, altri sui vincoli che le
istruzioni dovranno rispettare.
casuali) o algoritmi che lavorano in sistemi distribuiti (in rete) che hanno output o
input non prevedibili.
- Infine, deve essere sempre chiaro se si è giunti o meno al termine del procedimento , e
se sono stati ottenuti i risultati desiderati.
Alcuni algoritmi, es. i sistemi operativi, sono progettati per non terminare.
La maggior parte degli studiosi di informatica ritiene che nessun modello computazionale possa essere più
completo della MT. Ad esempio, è ben noto che gli algoritmi non deterministici o gli algoritmi paralleli possono
essere ricondotti ad una MT, anche se con perdita di efficienza. Teoricamente sarebbe comunque possibile
definire un modello computazionale in grado di svolgere compiti non realizzabili da una MT. Si parla di super-
Turing computabilità per far riferimento a questo concetto. Per la maggior parte degli studiosi la super-Turing
computabilità potrebbe essere ottenuta solo violando le leggi della fisica, ad esempio ammettendo una MT in
grado di compiere infinite operazioni in un tempo finito.
D E F I N I Z I O N E D I A L G O R I T M O
Abbiamo quindi visto che il termine algoritmo può essere utilizzato con accezioni diverse. In
logica matematica fa riferimento alla nozione di funzione calcolabile, nella progettazione
informatica è usato in senso più ampio per indicare una procedura di risoluzione di un
problema.
È importante evidenziare che ogni procedura per essere eseguita richiede un interprete
in grado di recepire ed eseguire le istruzioni che compongono la procedura stessa.
Questo aspetto è particolarmente rilevante in informatica in quanto ogni procedura deve
esprimere le istruzioni in modo adatto all’interprete che dovrà eseguirle. Calcolatori con
architetture diverse implicano tipologie diverse di istruzioni: un calcolatore meccanico sarà
diverso da un calcolatore digitale o da un calcolatore quantistico e calcolatori digitali con
diversa CPU (unità di calcolo) saranno tra loro diversi in quanto le istruzioni inserite nei
programmi da eseguire risulteranno in un diverso insieme di operazioni a livello macchina.
La nozione di algoritmo è tuttavia più generale di quella di programma : lo stesso
algoritmo, la stessa procedura, può essere eseguita da due programmi diversi, scritti con
diversi linguaggi di programmazione.
In effetti, un algoritmo può essere specificato a diversi livelli di astrazione. Esistono
strumenti per la specificazione di algoritmi che assumono punti di vista diversi.
- Diagramma di flusso (flow chart): è utilizzato come documentazione per progettisti e
programmatori, prescinde dai dettagli implementativi dei linguaggi di programmazione ed
esprime le istruzioni utilizzando il linguaggio naturale ma ha l’obiettivo di eliminare le
ambiguità relative al flusso di esecuzione.
- Pseudo-codice : esprime le istruzioni utilizzando un linguaggio più formale e riducendo
quindi gli spazi di ambiguità che possono essere contenuti nel linguaggio naturale ma
senza entrare nel dettaglio richiesto da uno specifico linguaggio di programmazione.
- Linguaggio di programmazione : esprime le istruzioni rispettando la sintassi di un
particolare linguaggio di programmazione. Il codice così espresso può essere quindi
eseguito da un programma che si occupa della compilazione o dell’interpretazione di
codice.
La definizione della sequenza di istruzioni è quindi un aspetto necessario alla definizione di
un algoritmo mentre la modalità con la quale le istruzioni vengono interpretare è un aspetto
dal quale si può prescindere.
Un altro aspetto che non può mancare nella definizione di un algoritmo è il suo livello di
generalità , ovvero il dominio di applicazione che caratterizza l’algoritmo. Un algoritmo è
infatti pensato per risolvere un problema specifico e per assolvere al suo compito deve
essere in grado di risolvere correttamente il problema per tutte le sue istanze del problema,
per tutti gli esempi coerenti con la definizione che si è data del problema. Un semplice
problema potrebbe essere: calcolare l’area di un poligono. Un tentativo di risoluzione di questo
problema potrebbe essere il seguente insieme di istruzioni: area è uguale a base moltiplicata per
altezza. Un’istanza del problema è rappresentata dai dati che assegnamo all’algoritmo: base =
5, altezza = 8. Con istanze di questo tipo, ovvero con poligoni che siano rettangoli, la
soluzione funziona. Ma come ci potremmo comportare con un’istanza che ha più di due lati
di lunghezza diversa, oppure con un poligono che non presenta angoli retti? Nel momento
in cui si trova un esempio coerente con la definizione del problema non risolvibile
dall’algoritmo, si deve rivedere il suo livello di generalità, ridefinire il problema in senso più
restrittivo. In alternativa si può, naturalmente, anche rivedere l’algoritmo. La soluzione
proposta sopra non raggiunge, in effetti, il livello di generalità richiesto dal problema,
mentre esistono formulazioni più generali del problema in grado di farlo, come ad esempio
la formula dell'area di Gauss. Abbiamo quindi visto che un algoritmo è definito dal
problema di cui si cerca la soluzione, da una formulazione o implementazione che ha
l’obiettivo di risolvere il problema e dal dominio di istanze per cui l’algoritmo risulta
valido.
Un modo per definire il problema è definire il dominio e il codominio dell’algoritmo. Il
dominio indica l’insieme dei dati che l’algoritmo riceve in ingresso, il codominio l’insieme
Per presentare questo approccio utilizzeremo i diagrammi di flusso in modo da esprimere
le nostre istruzioni attraverso una notazione grafica, comprensibile in modo intuitivo. Il
livello di astrazione adottato è quello del linguaggio naturale; il destinatario di una
notazione di questo tipo è infatti il progettista o il programmatore. Nel definire una
istruzione potremo adottare livelli di dettaglio diversi a seconda delle finalità del
diagramma. In generale, se diamo per scontato che il nostro destinatario saprà come
realizzare l'istruzione in un linguaggio di programmazione, potremo fornire un minor livello
di dettaglio; se riteniamo necessario chiarire alcuni passaggi dovremo adottare un maggior
dettaglio. Un minor dettaglio rende il diagramma di più facile e rapida comprensione ma
può portare ambiguità nella definizione. All’opposto, un maggior dettaglio rende il
diagramma più complesso ma meno ambiguo. Come sempre nella comunicazione
dovremmo scegliere la strategia espressiva più conveniente al nostro destinatario.
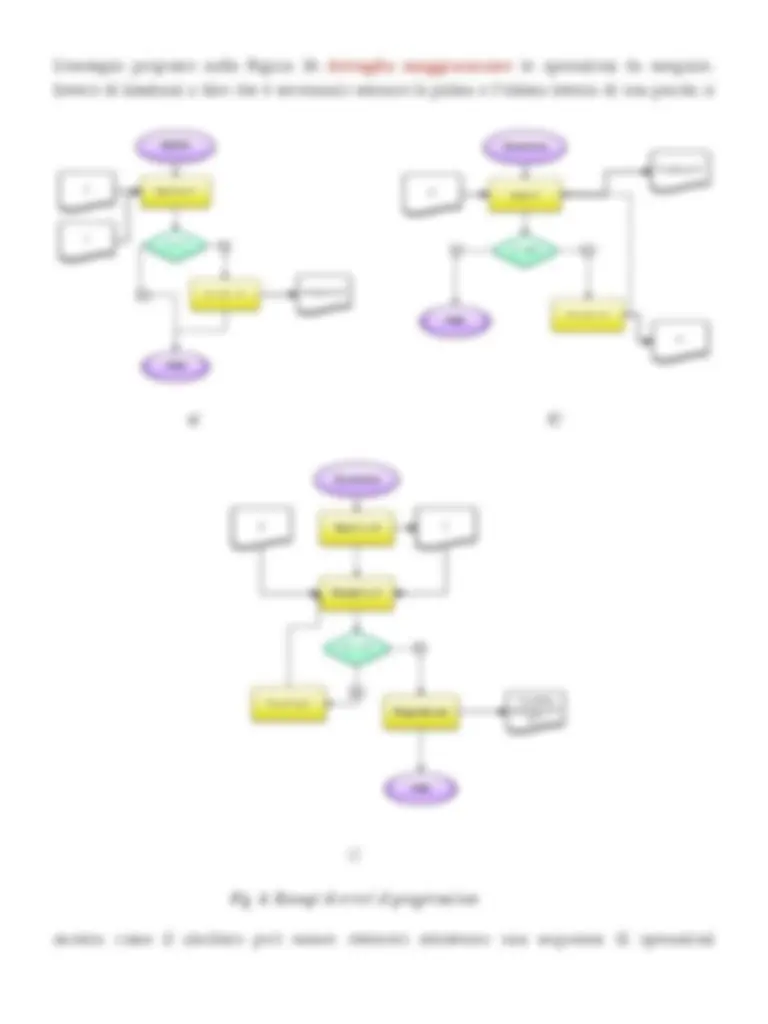
Presentiamo per prima cosa la notazione che utilizzeremo. Nella Figura 2 sono illustrati tre
diagrammi di flusso. Attraverso le ellissi indichiamo i punti di inizio e fine della procedura.
Attraverso le frecce indichiamo il flusso di esecuzione della procedura, attribuendo un
ordine alle istruzioni da eseguire. Attraverso i rettangoli indichiamo le operazioni o attività
che la procedura dovrà eseguire indipendentemente una dall’altra. Attraverso i rombi
indichiamo punti di decisione attraverso i quali viene valutata la realizzazione di particolari
condizioni. Se la condizione valutata risulta vera il flusso di esecuzione seguirà una
direzione, se risulta falsa il flusso di esecuzione ne seguirà un’altra. Attraverso i “ fogli ”
rappresentiamo file e dati che possono essere forniti ad una attività per essere elaborati, che
INIZIO
FINE
PRIMA
ATTIVITA'
SECONDA
ATTIVITA'
TERZA
ATTIVITA'
INIZIO
FINE
PRIMA
ATTIVITA'
TERZA
ATTIVITA'
DECISIONE
SECONDA
ATTIVITA'
No Si
DATI
DATI
INIZIO
FINE
PRIMA
ATTIVITA'
DECISIONE
Si
No
Fig. 2. Esempi di diagrammi di flusso
possono essere prodotti come risultato di una elaborazione oppure che vengono valutati
all'interno di un punto di decisione.
Nel 1966 Corrado Bohm e Giuseppe Jacopini dimostrano un importante teorema, detto
teorema della programmazione strutturata. Il teorema afferma che qualunque algoritmo può
essere implementato in fase di programmazione componendo istruzioni elementari
attraverso tre sole strutture di controllo: la sequenza , la selezione e l’ iterazione. I tre
esempi della Figura 2 illustrano proprio le tre strutture fondamentali di un algoritmo. Con la
Palindromo
FINE
Estrai prima e
ultima lettera
PAROLA
"PAROLA non
è palindroma"
X, Y
La parola non è
palindroma
X = Y?
La parola è
palindroma
No
ci sono altre
lettere?
Prova con
lettere
successive
Si
No
Si
"PAROLA è
palindroma"
Palindromo
FINE
Estrai lettera
LUNG - DIFF
PAROLA
"PAROLA non
è palindroma"
X
La parola non è
palindroma
X = Y?
La parola è
palindroma
No
LUNG - DIFF
= DIFF +
DIFF = DIFF -
Si
Si
No
"PAROLA è
palindroma"
Estrai unghezza
PAROLA
LUNG
Estrai lettera
DIFF +
Y
DIFF
Ottieni
DIFF = LUNG-
DIFF
Fig. 3. Riconoscere una parola palindroma
a)
b)
L’esempio proposto nella Figura 3b dettaglia maggiormente le operazioni da eseguire.
Invece di limitarsi a dire che è necessario estrarre la prima e l’ultima lettera di una parola ci
mostra come il risultato può essere ottenuto attraverso una sequenza di operazioni
INIZIO
FINE
X
X > Y?
C = X - Y
Si
Dati X e Y
"Il valore è C"
No
Y
Enumera
FINE
X
X = 100?
X = X + 1
No
"Il valore è X"
Dato X
X
Si
Enumera
FINE
X
Y^2 = X?
Rispondi con
Si
Y
Poni Y = 0
"La radice
quadrata di X
è Y"
No
Y = Y + 1
Prendi X e Y
a) b)
c)
Fig. 4. Esempi di errori di progettazione
elementari. In particolare l’algoritmo inizia ad analizzare la parola e ne ottiene la sua
lunghezza; questo dato è salvato nella variabile LUNG. Il valore di LUNG -1 darà la distanza
tra la prima e l’ultima lettera della parola; salviamo questo valore nella variabile DIFF. Per
indicare che DIFF assume il valore di LUNG -1 utilizziamo un’eguaglianza intendendo che
DIFF assume il valore che rende vera l’uguaglianza. A questo punto attraverso LUNG - DIFF
possiamo ottenere la posizione della prima lettera della parola, estraiamo il suo valore e lo
salviamo nella variabile X. Attraverso DIFF +1 possiamo ottenere la posizione dell’ultima
lettera della parola, estraiamo il suo valore e lo salviamo nella variabile Y. Confrontiamo X e
Y: se le lettere salvate nelle due variabili sono diverse la parola non è palindroma e
concludiamo l’algoritmo con questo risultato. Se le lettere salvate nelle due variabili sono
uguali riduciamo di 1 il valore di DIFF. In questo modo, iterando il flusso eseguito a partire
dall’estrazione delle lettere, potremo verificare se la seconda e la penultima lettera sono
uguali, così fino a quando non avremo esaurito l’intera lunghezza della parola. Se tutte le
lettere confrontate risultano uguali possiamo concludere che la parola è palindroma e
terminare l’algoritmo. Il lettore attento avrà notato che questa nuova specifica funziona per
le parole di lunghezza pari o dispari senza rischio di ambiguità.
A N A L I S I D E G L I A L G O R I T M I
Quando definiamo una procedura di calcolo dobbiamo verificare che garantisca risultati
corretti. Una procedura è descritta da un insieme finito di istruzioni che possono descrivere
un insieme molto ampio di casi di esecuzione, anche infinito. Non è sempre immediato
cogliere tutte le implicazioni derivanti dalla specificazione di una procedura. Una procedura
può disattendere le nostre aspettative per una carenza di progettazione (mancano alcune
istruzioni), oppure perché non abbiamo valutato il suo comportamento con tutti i dati del
dominio in cui lavora. L’errore di progettazione può produrre risultati scorretti oppure
l’incapacità dell’algoritmo di giungere ad una terminazione. Naturalmente, come dimostrato
da Turing, esistono problemi per i quali non si possono dare soluzioni algoritmiche.
L’algoritmo della Figura 4a giunge sempre a terminazione ma, a causa di una carenza di
progettazione, in alcuni casi può non produrre alcun risultato. Alcuni algoritmi possono non
terminare mai. Questo succede quando le condizioni di controllo non hanno previsto alcuni
possibili dati in ingresso. La Figura 4b mostra una caso abbastanza evidente: se il numero è
superiore a 100 oppure se non è un intero, la condizione di controllo non sarà mai vera. La
Figura 4c illustra un caso meno evidente: se il valore in ingresso non è un quadrato perfetto
l’algoritmo continua a lavorare all’infinito.
degli utenti simili a U avranno elevata probabilità di essere di interesse per U e dovranno
quindi essere suggeriti in ordine decrescente di probabilità.
Come detto, l’obiettivo di questo algoritmo è fornire un elenco di articoli, in ordine
decrescente di probabilità, di interesse per un utente dato. Utilizzando un metodo formale
potremo dimostrare che l’algoritmo effettivamente produce una lista di elementi ordinati in
modo decrescente, sulla base del valore di probabilità calcolato. Utilizzando un metodo
formale, tuttavia, non potremo mai dimostrare la validità del criterio di calcolo di questa
probabilità. L’obiettivo dell’algoritmo in questo caso non può essere definito formalmente e
quindi non sarà possibile nessuna prova formale di correttezza. Una valutazione delle
validità del criterio adottato per definire la probabilità calcolata può essere ottenuta solo
attraverso l’applicazione del metodo sperimentale. Dovremo quindi confrontare due gruppi
di utenti: al primo gruppo forniremo suggerimenti generati casualmente, al secondo
suggerimenti generati utilizzando il nostro criterio e dovremo valutare quante volte nei due
casi l’utente sia rimasto soddisfatto del suggerimento, se esista una differenza
statisticamente significativa tra i due gruppi ed eventualmente qualificare l’ampiezza di
questo effetto.
R I F E R I M E N T I B I B L I O G R A F I C I
[1] Turing, A. M. (1937). On computable numbers, with an application to the Entscheidungsproblem. Proceedings
of the London mathematical society, 2(1), 230-265. https://londmathsoc.onlinelibrary.wiley.com/doi/pdf/10.1112/
plms/s2-42.1.
[2] Gurevich, Yuri. "Sequential abstract-state machines capture sequential algorithms." ACM Transactions on
Computational Logic (TOCL) 1, no. 1 (2000): 77-111.
[3] Blass, Andreas, and Yuri Gurevich. "Algorithms: A quest for absolute definitions." Church’s Thesis After 70
(2009): 24-57.