Scarica Informatica 1: Introduzione, Algoritmi, Database e Linguaggi e più Appunti in PDF di Fondamenti di informatica solo su Docsity!
Indice:
- APPUNTI INFORMATICA
- Cenni Generali………………………………………………………………………………………..
- Algoritmi e Diagrammi di Flusso…………………………………………………………………….
- Strumenti di Analisi…………………………………………………………………………………...
- Database Relazionali…………………………………………………………………………………
- XML…………………………………………………………………………………………………...
- OLAP e Data Warehouse…………………………………………………………………………..
INFORMATICA 1 - Cenni Generali
Definizioni: L’informatica è una scienza che ha come oggetto l’informazione per quanto riguarda la sua: Acquisizione/Elaborazione/Memorizzazione/Trasmissione/Presentazione Memorizzazione di Informazioni di testo: Ogni informazione viene registrata come sequenza di termini binari (1, 0), una sequenza di n bit permette di mappare un insieme di 2^n elementi, esistono più convenzioni di mappatura ASCII/ASCII Esteso/Unicode UTF-8/UTF-16/UTF-32, ciascuno di questi associa la sequenza di bit (da 7 a 32) a un carattere specifico. Rappresentazione di Informazioni numeriche: 2 metodi: Non posizionali, Posizionali. Metodi non posizionali: la posizione dello stesso simbolo non indica un diverso valore (numeri romani) Metodi posizionali: la posizione di un simbolo comporta un diverso valore, minor numero di simboli per rappresentare cifre elevate e richiede la presenza del valore nullo Rappresentazione di decimali con segno: Standard dato dalla rappresentazione in virgola mobile (floating point), numero contenuto di bit per rappresentare numeri con molti decimali sia positivi che negativi, 𝑣𝑎𝑙𝑜𝑟𝑒 𝑑𝑒𝑐𝑖𝑚𝑎𝑙𝑒 = − 1 𝑆
- 𝑀𝑎𝑛𝑡𝑖𝑠𝑠𝑎 * 𝐵𝑎𝑠𝑒 𝐸𝑠𝑝𝑜𝑛𝑒𝑛𝑡𝑒 , 𝑠 = 1 (𝑆𝑒𝑔𝑛𝑜 𝑛𝑒𝑔𝑎𝑡𝑖𝑣𝑜), 𝑠 = 0 (𝑆𝑒𝑔𝑛𝑜 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑜) Necessario per salvare su disco, si possono scegliere inoltre due tipi di precisione, float o double. Precisione float: 32 bit, 1 bit = segno, 8 bit = esponente, 23 bit = mantissa, garantisce una precisione a 7 cifre decimali. Precisione double: 64 bit, 1 bit = segno, 11 bit = esponente, 52 bit = mantissa, garantisce una precisione a 15 cifre decimali. Algebra di Boole (operatori logici) 1854, ha come scopo la matematizzazione della logica umana, riscoperta con l’ascesa dei computer a rappresentazione binaria, ha come base una o più affermazione binarie (vere o false), le funzioni booleane sono necessarie per far svolgere al computer dei calcoli, funzioni implementate nei processori grazie ad una serie di porte logiche.
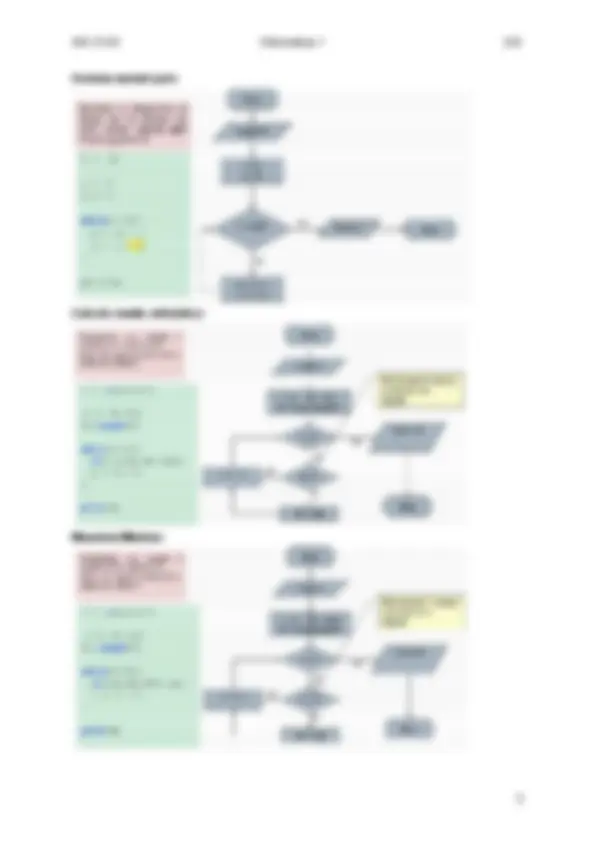
Somma numeri pari: Calcolo media aritmetica: Massimo/Minimo:
Calcolo imposta:
Classi di Linguaggi: ● Imperativi procedurali: codice suddiviso in blocchi, procedure e funzioni, centrale il concetto di variabile intesa come unità di memoria soggetta a sovrascrittura. ● Imperativi a oggetti: espandono la classe dei procedurali, l’utente in questo caso può anche definire delle classi (entità articolate che racchiudono al loro interno dei dati) che costituiscono un nuovo tipo di dato. Ogni istanza di classe viene definita oggetto, il programma è dunque costituito da una serie di oggetti fra loro interrelati. ● Funzionali: le funzioni svolgono un ruolo di primo piano, dati immutabili, le funzioni possono essere trattate come dati e possono dunque accettare/restituire un input/output non solo dati ma anche funzioni. R - Caratteristiche Fondamentali: ● Open source e disponibile per più piattaforme ● Materiale di apprendimento: ○ Manuali ufficiali gratuiti ○ Manuali contribuiti da utenti ○ Pubblicazioni dedicate esclusivamente ad R ● Utilizzabile in ambito statistico, economico, scienze sociali, scienze, economia e finanza, machine learning e natural language processing ● In grado di dialogare con strumenti esterni
INFORMATICA 1 - Database Relazionali
Introduzione: Il dato è l’elemento base in informatica ed è suscettibile di elaborazione allo scopo di ottenere un’informazione, la presenza di rilevanti moli di dati ne richiede una determinata organizzazione; l’informatico si occupa del mantenimento dei dati a differenza di statistici ed economisti che si occupano della loro elaborazione. Definizioni: ● Database: insieme organizzato di informazioni, rappresentanti un fatto o un processo, fisico/elettronico. ● Database elettronici: ○ OLTP (On Line Transaction Processing): informazioni aggiornate in tempo reale, DB gerarchici/reticolari/a oggetti ○ OLAP (On Line Analytical Processing): utilizzati per sintesi statistiche, aggiornamenti non in tempo reale ○ NoSQL: database senza una struttura rigida nell’organizzazione di dati RDBMS: Software per la gestione di DB relazionali, tutti i DBMS utilizzano sotto svariate forme il linguaggio SQL per le operazioni di Creazione di DB/Modifica di DB/Estrazione dati (query). Scomposizione delle informazioni: Al fine di evitare ripetizioni è necessario suddividere i dati fra più tabelle, delle relazioni si occupano dell’unitarietà delle informazioni fra le tabelle grazie all’aiuto di chiavi di congiunzione presenti su ogni tabella. PRINCIPIO GUIDA DEL MODELLO RELAZIONALE Fasi di sviluppo:
- Progettazione concetuale attraverso il modello “Entità-Relazione”, creazione tabelle
- Immisione di dati nelle tabelle da parte dell’utente
- Progettazione di queries e successivo utilizzo Modello Relazionale (DBr): Regole per tabelle:
- Ogni colonna deve avere un nome univoco
- I dati contenuti in un campo (colonna) non devono essere scomponibili
- Nello stesso campo vanno valori dello stesso tipo (numeri, testo, etc…)
- Ogni record (riga) è univoca
SQL (DDL) Comando Generale: DDL, Esempio (SQLite): DDL, Esempio (MS Access):
Relazioni: Si instaurano fra una chiave primaria ed una esterna, una chiave primaria è per propria natura unica mentre quella esterna può avere anche delle ripetizioni. Relazioni “Uno a Uno”: Quando la chiave è esterna allora fra le tabelle si instaura una relazione “Uno a Uno”. Relazioni “Uno a Molti”: Quando la chiave esterna non è “unica” si hanno dunque delle relazioni “Uno a Molti”. Relazioni “Molti a Molti”: Necessaria l'interposizione di una “tabella-fonte” fra due tabelle, ciò permette che vi siano due campi “non unici”.
INFORMATICA 1 - XML
Introduzione: I DB Relazioni sono deputati ad ospitare dati in modo organizzato e a rispondere a queries di estrazione di parte di essi, tipico problema è lo scambio di informazioni. Per scambio di informazioni si intende in generale: ● Condivisione fra applicativi differenti, ● Condivisione fra terminali differenti: ○ Tramite ausilio di Supporti Fisici, ○ Tramite ausilio di comunicazioni di rete. Formato Ideale di Interscambio: Il formato “testo” è il più adatto, e i linguaggi di tipo “markup” sono l’evoluzione del formato testo, sono ottimizzati per poter contenere basi di dati e per servire il maggior numero di necessità. Linguaggi Markup: ● Oggetto di Lavoro: documento di testo ● Scopo: dare senso a porzioni del documento ● Obbiettivo: identificare i marcatori, porzioni di testo 2 Tipi di Linguaggi Markup: ● Procedurali: indicano le procedure necessarie per ottenere la rappresentazione visiva del documento marcato, ne fanno parte linguaggi come TeX e LateX. ● Descrittivi: danno una struttura al documento di testo delegando la rappresentazione visiva ad un software esterno, protocolli principali (HTTP/HTML/XML/PNG/CSS/etc etc…) Vantaggi del formato testo: Il file di testo può essere visionato da chiunque possieda un editor di testi, accessibile a lungo nel tempo e infine leggibile anche da OS differenti. Il formato binario contiene dati, separati in sequenze di byte, non interpretabili direttamente: chi dovrà accedere al file sarà obbligato ad utilizzare degli interpreti, ci sarà inoltre un rischio di cessazione di sviluppo degli interpreti. HTML: Hyper Text Markup Language, linguaggio di tipo descrittivo costituito da un insieme predefinito di tag atti a descrivere la rappresentazione grafica del contenuto di un documento di testo. XML: Markup (meta) language, può essere inteso come base di dati di tipo gerarchico e si basa su dei tag definiti dall’utente, i tag possono inoltre essere degli attributi. Viene considerato un metalinguaggio in quanto permette di creare dei tag dedicati e permette inoltre di attribuire una semantica al testo. È nato per il contenimento e il trasporto dei dati, non si occupa della loro rappresentazione.
Utilizzi: Formato aperto che permette la comunicazione fra diversi applicativi, utilizzato per salvare files dalla suite Office, utilizzato come database in applicativi come iTunes. In ambito WEB XML è la base per definire linguaggi specializzati come: XHTML, MATHML, RSS. In ECONOMIA e FINANZA permette di definire standard di comunicazione per diversi campi, trasferimento di notizie = MDDL, descrizione prodotti finanziari = fpML, bilancio = XBRL. Regole per i Tag e Attributi: XML è case sensitive, la prima riga di codice indica la versione e la codifica ISO per la corretta interpretazione di dati, non sono consentiti errori di annidamento fra i tag e quest’ultimi non possono iniziare con numeri o caratteri speciali, è possibile definire tag vuoti o abbreviati e per utilizzare i caratteri speciali è necessario indicarli opportunamente. Il contenuto degli attributi deve invece essere racchiuso fra doppie apici “...”. Lettura XML/DOM/DTD: FARE RIFERIMENTO ALLE SLIDES!
Cubo OLAP: I dati per un certo problema vengono salvati in c.d. “cubi OLAP” tenendo conto della struttura a livello di dimensione/livelli/membri/misure Un cubo è una griglia, rappresentabile con facilità graficamente sino a 3 dimensioni •In due dimensioni è una tabella •In tre dimensioni è un cubo Finalità: OLAP è volto a consentire di individuare le relazioni che intercorrono fra le dimensioni e le misure INTERATTIVITÀ: Un DB OLAP crea e salva a intervalli prestabiliti delle soluzioni (processo di aggregazione) a possibili quesiti sui dati, in modo che siano velocemente accessibili. Quesiti differenti, tuttavia, potranno essere calcolati velocemente utilizzando come input le soluzioni già salvate. Operazioni su cubi: ● Slicing : restrizione della vista del cubo lungo un sottoinsieme di una certa dimensione ● Dicing : creazione di sottocubi, applicando operazioni di aggregazione su ognuno di essi ● Drilldown : visione delle relazioni scendendo in maggior dettaglio ● Roll up : ascesa di uno o più livelli di dettaglio, per avere una visione d’insieme e meno particolareggiata ● Aggregation : una o più dimensioni vengono collassate Data Warehouse (DW) La realizzazione di una soluzione OLAP può passare attraverso fasi differenti, sulla base del contesto in cui sono disponibili i dati. OLAP quindi si inserisce in un contesto più ampio, il “datawarehouse” che prenderemo in considerazione ora. Un data warehouse (trad. “magazzino dati”) costituisce l’insieme di dati di un’organizzazione, affiancato da tecniche la cui finalità è l’identificazione di relazioni multidimensionali a fini decisionali. I dati: ● Vengono raccolti da svariate fonti ● Sono disponibili in sola lettura DW: Datamart I dati provengono da svariate fonti, solitamente vari database OLTP, e vengono salvati in vari “datamart”. Questi consentono di applicare più facilmente tecniche OLAP.
Soluzioni possibili In base alle esigenze dettare dalla struttura dei dati e del loro utilizzo varie soluzioni sono possibili: ● MOLAP (multidimensional olap): dati e aggregazioni sono salvate in un db olap ● ROLAP (relational olap): dati e aggregazioni sono salvati in un db relazionale ● HOLAP (hybrid olap): memorizza dati in un db relazionale e le aggregazioni in un db olap MOLAP è utile quando l’aggiornamento dei dati non è molto frequente e la velocità di immissione non è cruciale. ROLAP è indicato quando le analisi vengono svolte di rado, mentre le immissioni nel db sono rapide e frequenti. HOLAP è la soluzione più avanzata, i dati sono ben compressi in un db relazionale e qui agilmente aggiornati. Mentre le analisi sono deputate in un processo a parte di tipo OLAP. IMPLEMENTAZIONE ROLAP Si utilizza un comune DBMS relazionale derogando ai principi relazionali Le tabelle vengono suddivise in : ● Tabelle dei fatti ● Tabelle delle dimensioni Le tabelle dei fatti presentano chiavi esterne collegate alle chiavi primarie delle tabelle delle dimensioni L’estrazione delle informazioni è effettuata attraverso join fra una o più tabelle delle dimensioni La struttura del DB, come detto, non rispetta i canoni della normalizzazione