Scarica Classificazione e Predizione: Processi per Descrivere e Prevedere Datos e più Slide in PDF di Tecniche Di Intelligenza Artificiale solo su Docsity!
Luiss
4 Classificazione
Dipartimento di Giurisprudenza
Classificazione e predizione
- Classificazione e predizione sono processi volti alla creazione di modelli che possono essere usati: - per descrivere degli insiemi di dati; - per fare previsioni future
Classificazione e predizione
- Il percepito dell’agente è composto da dati, caratteristiche, che possono essere di tipo continuo (es. temperatura) o categoriali (es. colore rosso).
- I dati categoriali possono essere ordinabili (es. scarso, insufficiente, …) o non ordinabili (es. sesso)
Classificazione e predizione
- All’agente può essere chiesto di predire un dato continuo, nel qual caso si tratta di predizione o regressione.
- All’agente può essere chiesto di predire un dato categoriale, nel qual caso si tratta di classificazione.
Classificazione e predizione
- Inoltre, possiamo avere percepiti bilanciati o sbilanciate a seconda che i dati disponibili siano egualmente ripartiti tra le classi o meno.
Classificazione e predizione
- Data Mining (estrazione di conoscenza): scoprire regolarità e patterns in dati multidimensionali e complessi
- Miglioramento delle performance : macchine che migliorano le loro capacità
- Software adattabili : programmi che si adattano alle esigenze dell’utente. Applicazioni
Fase 0 – preparazione dei dati (training e test) 1 di 4
- Data cleaning: pre-elaborare i dati in modo da
- Eliminare il rumore ● usando tecniche di smoothing
- Eliminare eventuali outliers ● dati con caratteristiche completamente diverse dal resto degli altri, probabilmente dovuti ad errori nei dati o a casi limite
- Trattare gli attributi mancanti ● Ad esempio, sostituendo un attributo mancante con la media dei valori per quell'attributo (nel caso di attributo numerico) o la moda (per attributi nominali)
- Anche se la maggior parte degli algoritmi di classificazione hanno dei meccanismi per eliminare rumore, outliers e attributi mancanti, una pulizia ad-hoc produce un risultato migliore.
Fase 0 – preparazione dei dati (training e test) 2 di 4
- Analisi di rilevanza degli attributi
- Nota anche col termine feature selection dal termine usato nella letteratura di machine learning.
- L'obiettivo è ottimizzare le prestazioni
- Il tempo impiegato per effettuare una analisi di rilevanza e l'addestramento sull'insieme di attributi
ridotti è minore del tempo per effettuare l'addestramento su tutti gli attributi
- Può anche migliorare la qualità del modello.
- Trasformazione dei dati
- Ad esempio, generalizzare alcuni attributi secondo una gerarchia dei concetti...
- oppure normalizzarne altri
- Per esempio, ridurre il range di variabilità di un attributo numerico all'intervallo [0,1] sostituendo 0 al
valore minimo, 1 al massimo e gli altri di conseguenza.
Fase 0 – preparazione dei dati (training e test) 4 di 4
Tid Refund Marital Status Taxable Income Cheat 1 Yes Single 125K No 2 No Married 100K No 3 No Single 70K No 4 Yes Married 120K No 5 No Divorced 95K Yes 6 No Married 60K No 7 Yes Divorced 220K No 8 No Single 85K Yes 9 No Married 75K No 10 No Single 90K Yes 10 Refund Marital Status Taxable Income Cheat No Single 75K? Yes Married 50K? No Married 150K? Yes Divorced 90K? No Single 40K? No Married 80K? 10
Dati dichiarazione reddito fraudolente (Cheat = Yes) o meno (Cheat = No)
Training set
Test set
Quaderno su esempio dati classificazione
dataset di esempio classificazione.ipynb
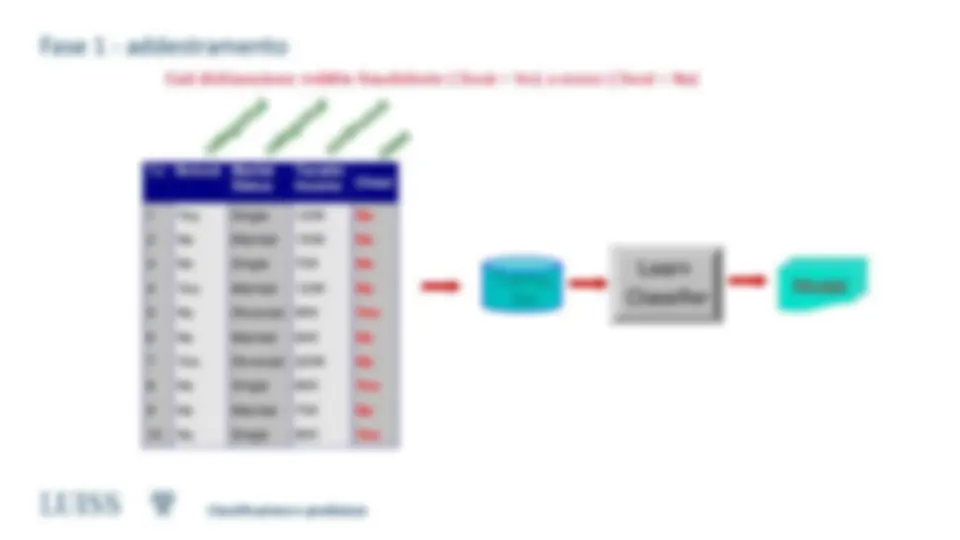
Fase 1 - addestramento
- Dati una collezione di dati (training set )
- Ciascun record contiene un insieme di attributi, uno dei quali è la classe di appartenenza.
- Trovare un modello per l’attributo classe che diventa funzione degli altri attributi
- Obiettivo: trovare una funzione che assegni in modo accurato l’attributo classe a nuovi records non classificati. - Un test set è usato per determinare l’accuratezza del modello. - Di solito il dataset iniziale è suddiviso in training e test sets: costruiamo il modello con il training set, e usiamo il test set per validarlo.
Fase 1 - addestramento
- Supervised learning (classification)
- Supervisione: I dati del training set (osservazioni, misure, etc.) sono stati preventivamente associati a etichette che indicano la classe di appartenenza - conoscenza supervisionata
- I nuovi record di dati sono classificati usando il modello costruito sulla base del training set
- Unsupervised learning (clustering)
- L’etichetta della classe è sconosciuta
- Dati un insieme di misure, osservazioni, ecc. lo scopo del clustering è quello di stabilire l’esistenza di gruppi/classi nei dati - Imparare l’esistenza di un qualche modello presente nei dati, che dà luogo ad una suddivisione dei
dati, senza conoscenza precedente
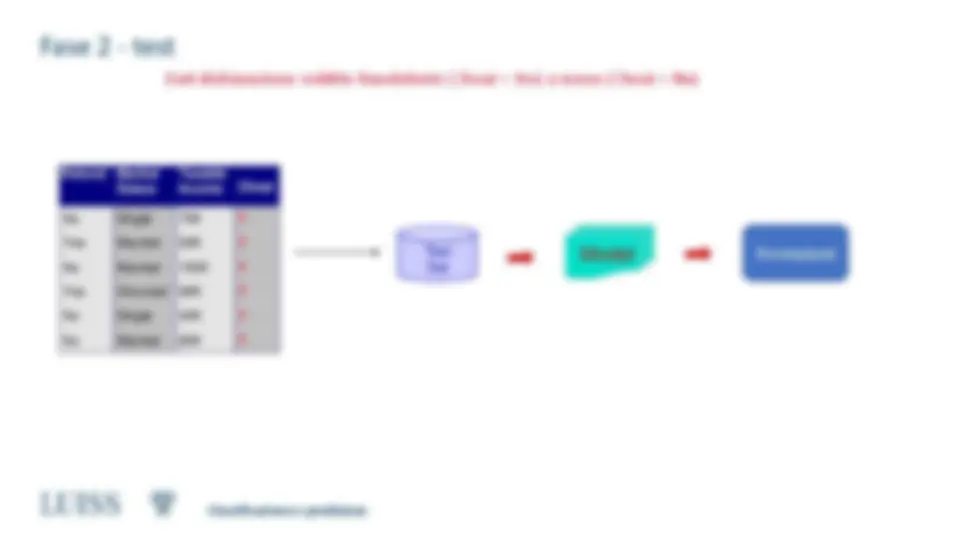
Fase 2 - test
- Valutazione degli algoritmi di classificazione
- Accuratezza nella predizione
- Velocità
- Tempo per costruire il modello
- Tempo per usarlo
- Robustezza
- Abilità del modello di fare previsioni corrette anche in presenza di dati errati o mancanti
- Scalabilità
- Caratteristica degli algoritmi che sono efficienti non solo per piccoli insiemi di dati ma anche per
grossi database.
- Interpretabilità
- Possibilità di assegnare un significato intuitivo al modello generato.
Fase 1 - addestramento
Tid Refund Marital Status Taxable Income Cheat 1 Yes Single 125K No 2 No Married 100K No 3 No Single 70K No 4 Yes Married 120K No 5 No Divorced 95K Yes 6 No Married 60K No 7 Yes Divorced 220K No 8 No Single 85K Yes 9 No Married 75K No 10 No Single 90K Yes 10
Training
Set
Model
Learn
Classifier
Dati dichiarazione reddito fraudolente (Cheat = Yes) o meno (Cheat = No)