



Clustering
Sistemi informativi per le Decisioni
Slide a cura di Prof. Claudio Sartori









































































Studia grazie alle numerose risorse presenti su Docsity

Guadagna punti aiutando altri studenti oppure acquistali con un piano Premium

Prepara i tuoi esami
Studia grazie alle numerose risorse presenti su Docsity
Prepara i tuoi esami con i documenti condivisi da studenti come te su Docsity
Trova i documenti specifici per gli esami della tua università
Preparati con lezioni e prove svolte basate sui programmi universitari!
Rispondi a reali domande d’esame e scopri la tua preparazione
Riassumi i tuoi documenti, fagli domande, convertili in quiz e mappe concettuali
Studia con prove svolte, tesine e consigli utili
Togliti ogni dubbio leggendo le risposte alle domande fatte da altri studenti come te
Esplora i documenti più scaricati per gli argomenti di studio più popolari
Ottieni i punti per scaricare
Guadagna punti aiutando altri studenti oppure acquistali con un piano Premium
clustering o analisi dei gruppi (dal termine inglese cluster analysis introdotto da Robert Tryon nel 1939) è un insieme di tecniche di analisi multivariata dei dati volte alla selezione e raggruppamento di elementi omogenei in un insieme di dati
Tipologia: Appunti
1 / 81

Questa pagina non è visibile nell’anteprima
Non perderti parti importanti!
Clustering
Scenario: Analisi e gestione dei mercati
Customer profiling
Quali tipi di cliente acquistano quali prodotti?
Clustering, classificazione
Identificare le richieste dei clienti
Trovare il prodotto migliore per clienti diversi
Predire quali fattori possono attrarrenuovi clienti
Produrre informazioni di sommario
Rapporti multi-dimensionali
Sintesi statistiche descrittive
Clustering
Clustering - descrizione del problema
input:
un insieme di N oggetti d-dimensionali
output:
determinare un partizionamento naturaledell'insieme di dato in k clusters + rumore
proprietà desiderate nei cluster:
oggetti nello stesso cluster sono simili^ Î
massimizzata la similarità intra-cluster
oggetti in cluster diversi sono differenti^ Î
minimizzata la similarità inter-cluster
Clustering
Prospettiva di ricerca
Dal passato...^
^
machine learning ^
database ^
visualizzazione
... per il futuro^
^
numero di punti dati (N) ^
numero di dimensioni (d) ^
livello di rumore ^
frequenza di aumento del numero di punti dati
Clustering
Alcuni datiPotrebberofacilmente esseremodellati comeuna distribuzionegaussiana con 5componentiMa cerchiamouna soluzione più“amichevole”e soddisfacente...
Clustering
Compressione con perdita Supponiamo di dovertrasmettere le coordinatedi punti presi a casoda questo insieme: dovremoideare un meccanismodi codifica/decodifica.Limitazione: ci è permessodi trasmettere soltanto due bitper punto. La trasmissione sarà con perdita (lossy)Perdita =
somma dei quadrati
degli errori tra le coordinatedecodificate e quelle originali.Quale codifica/decodificaminimizza la perdita?
Clustering
Idea due Supponiamo di dovertrasmettere le coordinatedi punti presi a casoda questo insieme: dovremoideare un meccanismodi codifica/decodifica.Limitazione: ci è permessodi trasmettere soltanto due bitper punto. La trasmissione sarà con perdita (lossy)Perdita =
somma dei quadrati
degli errori tra le coordinatedecodificate e quelle originali.Quale codifica/decodificaminimizza la perdita?
Idee migliori?
Clustering
K-means
cluster vuole
(es. k=5)
Clustering
K-means
cluster vuole
(es. k=5)
k
posizioni
come centri
il suo centro più vicino
Clustering
K-means
cluster vuole
(es. k=5)
k
posizioni
come centri
il suo centro più vicino
il centroide dei puntiche possiede...
Clustering
K-meansPartenza Example generated byDan Pelleg’s super-duperfast K-means system:
Dan Pelleg and AndrewMoore. Accelerating Exactk-means Algorithms withGeometric Reasoning.Proc. Conference onKnowledge Discovery inDatabases 1999,(KDD99) (available onwww.autonlab.org/pap.html
)
Clustering
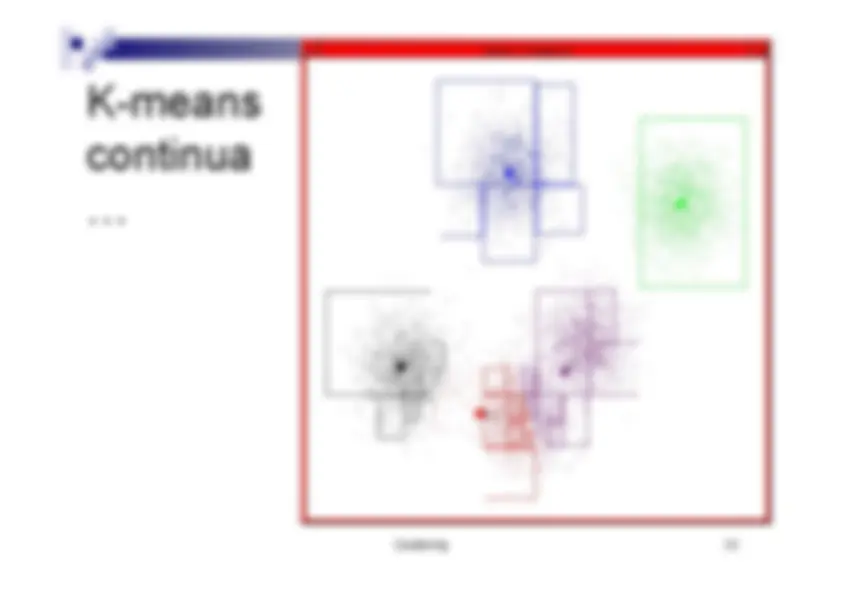
K-meanscontinua…
Clustering
K-meanscontinua…
Clustering
K-meanscontinua…