Scarica Computazione naturale e più Appunti in PDF di Biologia Computazionale solo su Docsity!
Appunti di “Computazione Naturale”
- Introduzione
- Reti neuroniche
- 2.1 Il neurone biologico
- 2.2 Implementazione
- 2.3 Algoritmo di Backpropagation
- 4 Reinforcement Learning
- 3.1 Algoritmi evolutivi
- 3.2 Metafora biologica
- 3.3 Algoritmi genetici
- 4.1 The Canonical ES Algorithm
- 4.2 (1 + 1)-ES
- 4.3 (μ + λ)-ES and (μ, λ)-ES
- 4.4 Mutation in ES
- 4.5 Recombination
- Evolutionary Programming *
- Artificial Immune Systems
- 6.1 Natural Immune System
- 6.2 Immune System Memory
- 6.3 Immune Network Theory
- 6.4 Artificial Immune Algorithms
- 6.5 Immune Programming
- 7.1 Ricerca sociale (basata su popolazione)
- 7.2 Particle swarm Optimization algorithm (PSO)
- 7.3 Confronto tra PSO e Algoritmi Evolutivi
- 7.4 Conservazione della diversità
- 7.5 Evoluzione di un algoritmo PSO
- 7.6 La metafora (Ant Colony)
- 7.7 Multiple Ant Colonies
- 7.8 Evolving an Ant Algorithm
- 8.1 Varianti della DE
- 8.2 Self-adaptive Differential Evolution
- 9.1 La forma di rappresentazione
- 9.2 Il bloating problem
- 9.3 Architetture GP più complesse
- 9.4 Strongly Typed GP
- 9.5 Grammar-Based GP
- 9.6 Semantics and GP
RETI NEURONICHE
Si propongono di simulare il comportamento dei
neuroni all’interno del cervello. Sono strutture
parallele per l’elaborazione di informazioni
distribuite. Le unità principali sono i neuroni,
organizzati in layer e connessi da canali che inviano
segnale unidirezionale. Ognuno di essi ha una singola
uscita che si dirama a tutti quelli con cui è collegato.
Vengono utilizzate per una vasta gamma di
problematiche come modelli con scopi di previsione,
clustering e classificazione.
Il primo modello matematico di neurone fu proposto
da McCulloch e Pitts: un semplice switch che riceve
input da altri neuroni e si attiva o meno se l’input
raggiungeva una determinata soglia. In seguito, l’unità
sviluppata da Rosenblatt, ha aggiunto l’informazione relativa ai pesi degli input di un neurone. Questo può
essere positivo, cioè eccitatore, o negativo, cioè inibitore.
2.1 IL NEURONE BIOLOGICO
I neuroni sono delle cellule specializzate nella comunicazione nervosa, una forma molto specializzata di
comunicazione intercellulare. È formato da tre parti principali:
- Corpo cellulare (o Soma): che possiede
tutti gli elementi necessari alla cellula,
come il nucleo, il reticolo
endoplasmatico, i ribosomi e i
mitocondri.
- Assone: una lunga fibra nervosa che
trasmette i messaggi, attraverso gli
impulsi chimici ed elettrici, dal corpo
del neurone fino ai dendriti di altri
neuroni o direttamente nei tessuti come
i muscoli. L’assone è spesso avvolto da
una guaina, che contribuisce ad isolare ed a proteggere le fibre nervose oltre che ad aumentare la
velocità di trasmissione dell’impulso nervoso.
- Dendriti: fibre nervose, simili a ramificazioni, che originano dal neurone. Possono essere localizzati ad
una o entrambe le estremità della cellula, permettono al neurone di comunicare con altre cellule.
I neuroni sono polarizzati, esiste cioè una differenza di potenziale
tra lo spazio extracellulare e lo spazio intracellulare. A determinare
questa differenza di carica concorrono gli ioni sodio e potassio. In
un neurone a riposo la concentrazione del sodio è più alta
all'esterno mentre la concentrazione del potassio è più alta
all'interno. L'esterno della membrana ha carica elettrica positiva
mentre l'interno carica elettrica negativa. La differenza di
potenziale che si instaura nel neurone a riposo è indicata come
potenziale di riposo.
Se la cellula riceve uno stimolo depolarizzante sufficientemente
elevato da spostare il potenziale di membrana fino a raggiungere un
potenziale di soglia viene generato un potenziale d’azione (o spike).
Dopo un'inversione di polarizzazione in conseguenza di uno stimolo, il neurone non è in grado di reagire
immediatamente ad un secondo: è richiesto infatti un breve intervallo di tempo, detto periodo refrattario
perché si ripristini il potenziale di riposo.
Ma come imparano i neuroni? Ogni neurone è connesso a moltissimi altri e le sinapsi, che si occupano della
trasmissione degli impulsi, si modificano nel tempo: possono crearsi, scomparire, rafforzarsi o indebolirsi in
base alla frequenza di utilizzo. In particolare, il cambiamento della plasticità sinaptica è dovuto a due processi:
LTP (long term potentiation, quindi eccitatorio) e LDP (long term depression, ovvero inibitorio). Questa
𝜏
( .
) → funzione di trasferimento; 𝜙
( .
) → funzione di attivazione;
proprietà è stata formalizzata da Hebb: “ se un neurone A è abbastanza vicino ad un neurone B da contribuire
ripetutamente e in maniera duratura alla sua eccitazione, allora ha luogo in entrambi i neuroni un processo di
crescita o di cambiamento metabolico tale per cui l'efficacia di A nell'eccitare B viene accresciuta .”
Dal punto di vista della metafora computazionale abbiamo tre differenti forme di apprendimento:
- Unsupervised, nella corteccia cerebrale. Si è dimostrato, infatti, che le sinapsi della corteggia seguono la
regola che propose Hebb: la plasticità è quindi rafforzata se l’input presinaptico è associato ad una
risposta postsinaptica e depresso nel caso in cui all’input presinaptico non corrisponde una risposta
postsinaptica.
- Reinforcement, nei gangli basali. Questo gruppo di nuclei produce dopamina quando si ottempera
l’azione desiderata, rafforzando in questo modo i collegamenti sinaptici.
- Supervised, nel cervelletto. Un’analisi statistica ha infatti mostrato che sono le cellule del cervelletto a
codificare l’errore nei movimenti, rispetto a quelli desiderati.
Continuando sulla metafora biologica, l’attivazione ripetuta di una sinapsi rafforza quella connessione,
abbassando quindi la threshold per l’attivazione del neurone postsinaptico. In una rete neuronica, quindi, i pesi
rappresentano la forza sinaptica delle connessioni tra neuroni.
Per i modelli di neuroni si hanno 4 livelli di astrazione:
- McColloch-Pitts
- Leaky Integrate Fire (LIF)
- Hodgkin-Huxley
- Multicompartament
McColloch-Pitts
Benché catturi l’essenza dei processi neuronali, ne è una rappresentazione artificiale, dal momento in cui non
include le caratteristiche fisiologiche dei neuroni. Ma è possibile descrivere un circuito che possa calcolare il
cambiamento del potenziale di membrana?
- Il potenziale di membrana è la differenza tra potenziale
intracellulare ed extracellulare, 𝑉
𝑚
𝑖
𝑒
- Abbiamo poi la membrana del neurone che può essere modellata
come una capacità 𝐶
𝑚
𝑚
- I canali ionici possono essere modellati come una resistenza R. 𝑉
𝑅
𝑅
- La distribuzione di carica asimmetrica dovuta alle pompe Na-K
(sodio-potassio) da origine al potenziale di riposo 𝑉
𝑟𝑒𝑠𝑡
Consideriamo di inserire corrente nel neurone.
La membrana agisce come un condensatore, la cui tensione, in assenza di corrente iniettata, decade a un
livello di riposo 𝑉
𝑟𝑒𝑠𝑡
Leaky Integrate Fire (LIF)
Si basa sull’ipotesi che, dal momento che tutti i potenziali di azione inviati nell'assone sono identici, l'unica
caratteristica informativa degli spiking di un neurone è il momento in cui si verificano i potenziali d'azione.
Risulta quindi superflua una modellazione del canale ionico responsabile dello spike. Una volta che la cellula
raggiunge la sua soglia, produrrà rapidamente uno spike, resettandosi immediatamente dopo. LIF divide le
dinamiche dei neuroni in due tipi:
- Sub-threshold (𝑉(𝑡) < 𝑉_𝑡ℎ), in cui la membrana si comporta passivamente, senza quindi che i canali
ionici dipendano dalla tensione, e agisce come un condensatore la cui tensione, in assenza dell’iniezione
di corrente, decade ad un livello di riposo 𝑉
𝑟𝑒𝑠𝑡
- Supra-threshold (𝑉
≥ 𝑉_𝑡ℎ), quando la tensione raggiunge la soglia di threshold al tempo 𝑡
0
, dovuta
ad iniezione di corrente nella membrana si ha che:
- La tensione raggiunge il livello di 𝑉
𝑠𝑝𝑖𝑘𝑒
registrandolo all’istante 𝑡
0
- Il potenziale di membrana viene resettato ad un
valore 𝑉
𝑟𝑒𝑠𝑒𝑡
- Il sistema rimane per un breve periodo in uno
stato refrattario
I principali punti di forza delle reti neuroniche sono:
- Adatti per i problemi che richiedono soluzioni approssimate (non ottime)
- Semplici da implementare
- Veloce
I punti di debolezza, invece:
- Funzionamento black box
- Necessita di molti dati da cui apprendere
- Molti iperparametri, in particolare, la scelta del learning rate e il rapporto exploration/exploitation
Infatti, un learning rate elevato corrisponde a salti molto grandi, quindi in maniera quasi caotica. Dualmente, un
lr molto piccolo corrisponderebbe ad una ricerca esaustiva incappando nella problematica dei minimi locali.
2.3 ALGORITMO DI BACKPROPAGATION
Un singolo neurone può imparare i propri pesi usando la regola del gradiente discendente, tuttavia quasto non
basta quando utilizziamo una rete, dal momento che imparerebbe solo i pesi dell’ultimo layer (calcolando
quindi l’aggiornamento degli stessi in funzione della distanza tra valore di output e target).
Per risolvere questa problematica, dal momento che la derivata è scomponibile, così da propagarla all’indietro.
Abbiamo il punto di partenza degli errori, che è la loss function, e sappiamo come derivarla: sapendo come
derivare ogni funzione dalla composizione, possiamo propagare l'errore dalla fine all'inizio. Ma come facciamo?
Essenzialmente la back-propagation è l’applicazione della chain rule: se abbiamo 3 funzioni 𝑓(𝑔(ℎ(𝑥))), allora
la derivata di f rispetto ad h è uguale al prodotto delle derivate di f e g divido il prodotto delle derivate di g e h :
𝑑𝑓
𝑑ℎ
𝑑𝑓
𝑑𝑔
𝑑𝑔
𝑑ℎ
. Abbiamo quindi due step per la backpropagation: il primo è tra output e hidden layer, e l’altro è
dall’hidden fino all’input.
𝑝
𝑝𝑘
2
𝑀
𝑘= 1
𝑝𝑘
𝑝𝑘
2
𝑀
𝑘= 1
L’errore del p-esimo sample è definito come la loss function (in questo caso MSE) tra il valore di output e quello
target. M è il numero di neuroni in un layer.
𝑘𝑗
𝑜
𝑝𝑘
𝑝𝑘
𝑘
𝑜
𝑝𝑘
𝑜
𝑝𝑘
𝑜
𝑘𝑗
𝑜
𝑝𝑘
𝑝𝑘
𝑘
𝑜
′
𝑝𝑘
𝑜
𝑝𝑘
𝑜
𝑘𝑗
𝑜
𝑝𝑘
𝑜
𝑘𝑗
𝑜
𝑘𝑗
𝑜
𝑘𝑗
𝑜
𝑝𝑗
𝑘
𝑜
𝐿
𝑗= 1
𝑝
𝑘𝑗
𝑜
𝑝𝑘
𝑝𝑘
𝑘
𝑜
′
𝑝𝑘
𝑜
𝑝𝑘
𝑜
′
𝑘𝑗
𝑜
Dove:
𝑝𝑘
𝑜
è l’output del k-esimo neurone senza che sia applicata la funzione di attivazione
𝑘𝑗
𝑜
è il j-esimo peso del k-esimo neurone
𝑝𝑗
è l’ouput del j-esimo neurone dell’hidden layer
L’uso della o fa riferimento all’output layer, quello della h all’hidden
Quindi come propaghiamo all’indietro l’approccio se non abbiamo l’output atteso per gli hidden layer, così da
modificare i pesi? Mediante la chain rule sul layer precedente, in modo da non dover conoscere l’output atteso
per l’hidden layer:
𝑝
𝑘𝑗
𝑜
𝑝𝑘
𝑝𝑘
𝑘
𝑜
′
𝑝𝑘
𝑜
𝑝𝑘
𝑜
′
𝑘𝑗
𝑜
𝑘
𝑗
ℎ
′
𝑝𝑗
ℎ
𝑝𝑗
ℎ
′
𝑝𝑖
2.4 REINFORCEMENT LEARNING
Nel campo del machine learning, il reinforcement learning ha guadagnato popolarità negli ultimi decenni. La
caratteristica principale di questo tipo di apprendimento è che l’agente impara ricevendo stimoli rinforzanti o
punitivi, interagendo con l’ambiente, che alterano la probabilità di determinati comportamenti. Le azioni che
porteranno l’algoritmo a ricevere più reward saranno quelle più frequenti. Questa classe di algoritmi ha
bisogno di essere ben bilanciata tra exploration (e quindi trovare quante più informazioni possibili
nell’ambiente) ed exploitation (quindi utilizzare quante più informazioni possibili per massimizzare i reward).
Tra questi, il più comune è il Q-learning che valuta quale azione prendere sulla base di una funzione valore-
azione che determina il valore di essere in un certo stato e prendere un’azione (in questo stato).
Tuttavia ha un grande inconveniente, visto che il learning procede in maniera forward, da un’azione all’altra,
mentre il reward è ottenuto all’indietro, solo la penultima mossa è realmente ottimizzata. In altre parole, non
posso ottimizzare tutto il percorso, ma solo l’ultima azione, in quanto non ho evidenze se le azioni intermedie
mi stiano portando nella direzione giusta.
𝑖𝑗
𝑖𝑗
𝑡
𝑡+ 1
𝑡
Dove:
- w sono i pesi della rete
- 𝜂 è il learning rate
- 𝛾 è l’attendibilità con la quale posso stimare il reward ( V ) che otterrò nello stato successivo. È un valore
compreso tra 0 e 1, in base a quanto sono sicuro dell’azione da compiere.
Per ovviare a questa problematica ci si avvale del temporal difference learning in cui non si stimano più i pesi
da dare alle azioni (nel gioco degli scacchi, se faccio una mossa e perdo il pedone è meno grave rispetto a
perdere la regina), ma si ha una stima sui reward stessi:
𝑡+ 1
𝑡
𝑡
𝑡+ 1
𝑡
𝛾 quindi è l’ago della bilancia, in cui se non sono in grado di fare la previsione sul reward, quella componente va
a 0, modificando la mia stima solo del reward ottenuto. Il learning rate, invece, mi dice come si modifica la
previsione del reward in funzione del reward che ho avuto adesso e di quello che avevo stimato nei passi
precedenti.
Infine, il learning rate, determina la dinamica del tipo di ricerca che implementa l’algoritmo: un learning rate
molto elevato consente molta exploration, perché fa variare molto il modo nel quale verrà stimato il reward al
passo successivo, ma farà anche cambiare molto il modo nel quale viene modificato il comportamento sulla
base dello stimolo ricevuto. D’altro canto, un lr molto piccolo consente exploitation, rappresenterebbe una
ricerca esaustiva nello spazio degli stati ed è quindi un raffinamento che vorremmo solo in una fase successiva
a quella dell’exploration. Per questo motivo, nuove tecniche di lr adattivi si stanno facendo strada: grandi valori
iniziali per permettere una visita maggiore dello spazio di ricerca, per poi diminuirli e raffinare la ricerca una
volta trovato il minimo.
L’evoluzione può essere vista come una ricerca tra un enorme numero di possibili soluzioni (in biologia
sequenze genetiche che permettano all’individuo di adattarsi all’ambiente e riprodursi, cioè la fitness ). La
fitness, in natura, è direttamente proporzionale alla probabilità di avere un alto numero di discendenti.
Durante la riproduzione sessuale si ha la ricombinazione (crossover): il un nuovo organismo si forma
dall'unione di due cellule sessuali ( gameti ), ciascuna proveniente da uno dei due genitori.
Successivamente la prole è a volte sottoposta ad una mutazione , che cambia il singolo bit del DNA proveniente
del genitore, spesso a causa di un errore nella copia.
Entrambe effettuano una ricerca in ampiezza nello spazio degli stati, favorendo la diversità.
Va osservato che nelle specie più complesse, c’è sempre un periodo in cui genitori e figli convivono, soprattutto
per una trasmissione di esperienza.
Gli AE sfruttano l’analogia con tale comportamento biologico,
semplificando naturalmente le componenti ed i processi).
Il parallelo biologia-computazione evolutiva può essere visto
come un problema di ottimizzazione, cercare cioè la/e
migliore/i soluzione/i da un insieme di tutte quelle possibili.
Aspetti caratteristici degli AE sono la ricerca parallela, la
variazione casuale e ricombinazione delle soluzioni.
L’idea è di interpretare i parametri che descrivono il problema
come geni artificiali, cioè un insieme di individui, su cui
applicare l’evoluzione. Sono utilizzati operatori genetici su
grandi popolazioni di genotipi, ed il fenotipo è poi valutato in
termini di fitness. Quest’ultima determina se il fenotipo deve
accoppiarsi e trasferire parti del suo materiale genetico alla successiva generazione.
Un primo concetto da modellare è la popolazione : vettore di dimensione costante composto da individui,
corrispondenti alle soluzioni candidate; ogni individuo può accoppiarsi con qualunque altro.
Occorre poi definire la valutazione , cioè il mapping dal genotipo al fenotipo (individuo).
La codifica definisce lo spazio di ricerca, e consiste solitamente in 3 cose: struttura dati, interpretazione e
funzione di decodifica. È strettamente legato alla mutazione ed al cross-over, dal momento che quest’ultime
operano sulla struttura dati stessa, mentre la selezione è indipendente dalla codifica.
Codifica binaria Codifica reale
Vantaggi - Precisione e decodifica definita dall’utente.
- Utilizzabile per altri problemi.
- Facile e veloce da implementare.
- Grande varietà di operatori.
Svantaggi - Decodifica da implementare manualmente.
- Considerare i problemi relativi alla codifica.
- Basso controllo della precisione.
- Distanza non uniforme tra soluzioni vicine
Altre
differenze
Gli operatori vengono applicati prima della
decodifica dello spazio del problema.
Lo spazio di ricerca è uguale a quello del
problema: gli operatori funzionano dopo la
decodifica
Le performance della ricerca sono influenzate dai valori dei parametri che controllano gli operatori.
3.3 ALGORITMI GENETICI
In genetica, una forte distinzione viene
tracciata tra il genotipo e il fenotipo; il
primo contiene informazioni genetiche,
mentre il secondo è la manifestazione fisica
di queste informazioni. Entrambi hanno un
ruolo nell'evoluzione poiché i processi
biologici della generazione della diversità
agiscono sul genotipo, mentre il "valore" o
idoneità di questo genotipo nell'ambiente
dipende dalla sopravvivenza e dal successo
riproduttivo del fenotipo corrispondente.
Analogamente, nella GA canonica viene fatta
una distinzione tra la codifica di una
soluzione (il "genotipo"), a cui sono applicati
gli operatori genetici simulati e il fenotipo associato a tale codifica.
Gli algoritmi evolutivi, compresa la GA, possono essere caratterizzati come: x
[
t + 1
]
= r (v(s(x
[
t
]
dove 𝑥[𝑡] è la popolazione di codifiche al timestep 𝑡, 𝑣(. ) è l'operatore di variazione casuale (crossover e
mutazione), 𝑠(. ) è la selezione per l'operatore di accoppiamento e 𝑟(. ) è l'operatore di selezione di
sostituzione. Una volta ottenuta e valutata la popolazione iniziale di soluzioni codificate, viene applicato un
processo riproduttivo in cui le codifiche corrispondenti alle soluzioni di migliore qualità o più idonee hanno
una maggiore possibilità di essere selezionate per la propagazione dei loro geni nella generazione successiva.
Proprio come i genotipi biologici codificano i risultati delle prove evolutive passate, la popolazione di genotipi
nella GA codifica anche una storia (o memoria) del successo relativo dei fenotipi risultanti per il problema di
interesse.
La selezione sfrutta le informazioni nella popolazione attuale, concentrando l'interesse sulle soluzioni ad alta
idoneità.
Il crossover e la mutazione perturbano queste soluzioni nel tentativo di scoprire soluzioni ancora migliori. La
mutazione fa ciò introducendo nuovi valori genetici nella popolazione, mentre il crossover consente la
ricombinazione di frammenti di soluzioni esistenti per crearne di nuovi.
Algoritmo
Determina la codifica della soluzione come un genotipo e definire la funzione di fitness;
Creare una popolazione iniziale di genotipi;
Decodificare ciascun genotipo in una soluzione e calcolare l'idoneità della soluzione di ciascuno;
repeat
Selezionare n membri dall'attuale popolazione di codifiche (i genitori);
repeat
Seleziona due genitori casualmente;
Con probabilità 𝑝
𝑐𝑟𝑜𝑠𝑠
, eseguire un processo di crossover, per produrre due nuove soluzioni;
Altrimenti, il crossover non viene eseguito e i figli saranno copie dei loro genitori;
Con probabilità 𝑝
𝑚𝑢𝑡
, applica un processo di mutazione ai figli;
until n nuovi figli sono stati creati
sostituisci la vecchia generazione con la nuova
until condizione di terminazione;
3.3.1 Scelte implementative per GA
Sebbene l'idea di base dell'GA sia piuttosto semplice, un progettatore deve affrontare una serie di decisioni
importanti quando cerca di applicarlo a un problema specifico:
- quale rappresentazione dovrebbe essere usata?
- come deve essere inizializzata la popolazione iniziale di genotipi?
- come deve essere misurata la forma fisica?
- come dovrebbe essere generata la diversità nella popolazione di genotipi?
Nell'applicare la GA, l'utente deve selezionare come deve essere rappresentato il problema, e ci sono due
aspetti di questa decisione. Innanzitutto, l'utente deve decidere in che modo le potenziali soluzioni (fenotipi)
saranno codificate nel genotipo. In secondo luogo, l'utente deve decidere in che modo i singoli elementi del
genotipo saranno codificati.
3.3.1.1 Codifica dei genotipi
Nelle prime ricerche sulle GA sono state utilizzate codifiche a valori binari per i genotipi (0101 ... 1). Il metodo
di decodifica più semplice consiste nel convertire la stringa binaria in un valore intero, che a sua volta può
essere convertito in un valore reale se necessario.
Sebbene lo schema di decodifica per una stringa binaria sia facile da capire, può soffrire di Hamming cliffs ,
poiché a volte è necessario un grande cambiamento nel genotipo per produrre una piccola modifica nel valore
intero risultante.
Gli Hamming cliffs possono potenzialmente creare barriere che la GA potrebbe incontrare difficoltà nel
passaggio. Un sistema di codifica alternativo che è stato
utilizzato in alcuni sistemi GA è quello della codifica Gray.
Nella codifica di Gray, un singolo cambiamento di intero
richiede solo un cambiamento di un bit nel genotipo
binario. Ciò significa che le soluzioni adiacenti nello spazio
Valore intero Codifica binaria Codifica Gray
3.3.4.1 Strategia di selezione
Il disegno della strategia di "selezione per accoppiamento" determina la pressione selettiva dell'algoritmo. Se la
pressione selettiva è troppo bassa, le informazioni dei genitori migliori si diffonderanno lentamente attraverso
la popolazione, portando a un processo di ricerca inefficiente. Se la pressione di selezione è troppo alta, è
probabile che la popolazione resti bloccata in un ottimo locale, poiché un'alta pressione di selezione tende a
ridurre rapidamente il grado di diversità genotipica nella popolazione. Pertanto, strategie di selezione di
migliore qualità, incoraggiano lo sfruttamento di individui migliori, senza perdere troppo rapidamente la
diversità nella popolazione.
SELEZIONE PROPORZIONALE ALLA FITNESS
Il metodo originale di selezione per la riproduzione nell'AG è la selezione proporzionale alla fitness (FPS) e in
questo metodo la probabilità che un membro specifico della popolazione attuale
sia selezionato per l'accoppiamento è direttamente correlata alla sua idoneità
rispetto agli altri membri della popolazione.
Il processo di selezione FPS può essere pensato come una ruota della roulette, dove
agli individui più allenati viene assegnato più spazio sulla ruota. Sebbene questo
metodo di selezione sia intuitivo, può produrre risultati scarsi nella pratica poiché
incorpora una pressione di selezione elevata nella fase iniziale della GA.
SELEZIONE ORDINALE
Un approccio per superare i problemi della selezione proporzionale alla fitness è
usare la selezione basata sul rank. Nella selezione basata sul rank, le persone vengono classificate dal migliore
al peggiore e questa informazione viene utilizzata per calcolare un'idoneità scalata per ogni individuo.
Un esempio di un processo di classificazione lineare è fornito da:
f
rank
= 2 − P +
2 (P− 1 )(rank− 1 )
n− 1
Dove 𝑛 è il numero dei membri della popolazione e 𝑃 è un fattore di scala ∈ [ 1. 0 , 2. 0 ] che determina la
pressione di selezione. Un vantaggio della selezione basata sul rango è che riduce il rischio di influenzare il
processo di ricerca a seguito di una selezione troppo intensiva delle migliori soluzioni nelle prime generazioni
di GA.
Un altro metodo di selezione basato sul rank è la selezione per troncamento. In questo schema, i primi 𝑚 degli
𝑛 individui nella popolazione vengono selezionati.
Un metodo comunemente usato, ed efficiente dal punto di vista computazionale, è la selezione del torneo. Sotto
la selezione del torneo, i membri k vengono scelti casualmente senza essere sostituiti dalla popolazione. Il più
adatto è scelto come vincitore del torneo ed è selezionato per essere un genitore.
3.3.5 Mutation e Crossover
L'operatore di mutazione svolge un ruolo fondamentale nel GA poiché garantisce che il processo di ricerca non
si fermi mai. Al contrario, il crossover, se applicato come unico metodo per generare diversità, cessa di
generare novità quando tutti i membri della popolazione convergono allo stesso genotipo. Se viene applicato un
tasso di mutazione molto alto, gli operatori di selezione e di crossover possono essere sopraffatti e l'AG
assomiglia efficacemente a un processo di ricerca casuale. Viceversa, se viene utilizzata una pressione di
selezione elevata, sarà necessario un tasso di mutazione più elevato per impedire una convergenza prematura
della popolazione. Nell'impostare un tasso appropriato di mutazione, l'obiettivo è selezionare un tasso che aiuti
a generare novità utili ma che non distrugga rapidamente le buone soluzioni prima che possano essere sfruttate
attraverso la selezione e il crossover.
GENOTIPI BINARI
La forma originale di crossover per i genotipi a valori binari era il crossover a punto singolo. Un valore 𝑝 𝑐𝑟𝑜𝑠𝑠
viene impostato all'inizio del GA e per ogni coppia di genitori selezionati viene generato un numero casuale
dalla distribuzione uniforme 𝑈 ( 0 , 1 ). Se questo valore è maggiore della soglia, viene applicato il crossover per
generare due nuovi figli; altrimenti il crossover viene aggirato e i due figli sono cloni dei loro genitori. Le soglie
di crossover sono tipicamente selezionate dalla gamma 𝑝_𝑐𝑟𝑜𝑠𝑠 ∈ ( 0. 6 , 0. 9 ) ma, se lo si desidera, la velocità di
crossover può essere variata durante l’esecuzione.
Un problema del crossover a punto singolo è che i componenti correlati di una soluzione codifica che sono
ampiamente separati sulla stringa tendono a essere interrotti quando viene applicata questa forma di
crossover. Un modo per ridurre questo problema consiste nell'implementare un crossover a due punti, in cui le
due posizioni di taglio sulle stringhe principali vengono scelte casualmente e vengono scambiati i segmenti tra
le due posizioni.
Un'altra forma popolare di crossover è il crossover uniforme, nel quale viene effettuata una selezione casuale
del valore del gene da ciascun genitore quando si riempie ciascuna locazione corrispondente sul genotipo del
figlio. Il processo può essere ripetuto una seconda volta per creare un secondo figlio, oppure il secondo figlio
potrebbe essere creato utilizzando i valori non selezionati durante la produzione del primo.
Per i genotipi binari, un'operazione di mutazione può essere definita come un bit-flip. Tipici tassi di mutazione
per un GA con valori binari sono comunemente dell'ordine 𝑝
𝑚𝑢𝑡
= 1 /𝐿 dove 𝐿 è la lunghezza della stringa
binaria.
GENOTIPI REALI
L'operatore di crossover può essere modificato per i genotipi a valori reali in modo tale che (ad esempio) gli
elementi della stringa di ciascun genitore siano mediati per produrre il valore corrispondente nei loro figli. Più
in generale, i valori reali in ciascuna locazione del figlio possono essere calcolati come combinazione lineare dei
valori dei genitori.
Mentre una semplice strategia per modificare la mutazione per le codifiche con valore reale consiste
nell'implementare un operatore di mutazione stocastica, in cui un elemento di una stringa con valore reale può
essere mutato aggiungendo un valore reale piccolo (positivo o negativo) ad esso.
3.3.6 Strategia di rimpiazzo
Nel decidere quali genitori e figli possano sopravvivere nella generazione successiva è possibile applicare
un'ampia varietà di strategie di sostituzione, tra cui:
- sostituzione diretta (i figli sostituiscono i genitori)
- sostituzione casuale (la nuova popolazione viene selezionata casualmente dai membri della
popolazione esistente e dai loro figli)
- sostituzione del peggiore (tutti i genitori e i figli sono classificati in base alla fitness e i peggiori sono
eliminati)
- sostituzione a torneo (il perdente del torneo è selezionato per la sostituzione).
Nella GA canonica viene generalmente adottata una strategia di sostituzione generazionale. Il numero di figli
prodotti in ogni generazione è uguale alla dimensione attuale della popolazione e durante la sostituzione
l'intera popolazione attuale viene sostituita dalla popolazione appena creata di codifiche figlio. Il rapporto tra il
numero di figli prodotti e le dimensioni della popolazione attuale è noto come gap generazionale ; quindi, il
divario generazionale è tipicamente 1.
Una seconda strategia popolare è la sostituzione dello steady state , in cui solo un piccolo numero di figli (a volte
solo uno) viene creato durante ogni generazione che sostituirà il peggiore dell’attuale generazione. L'adozione
di una strategia di sostituzione dello stato stazionario assicura che le popolazioni successive si sovrappongano
in misura significativa (i genitori e i loro figli possono coesistere), richiede meno memoria e consente all'AG di
sfruttare soluzioni valide immediatamente dopo essere state scoperte.
Generalmente, la selezione basata sul fitness è implementata per la selezione dei genitori o per la selezione
sostitutiva, non per entrambi. Se la selezione basata sul fitness è implementata per entrambi, verrà creata una
pressione selettiva molto forte, che porterà a una convergenza molto rapida. Un'altra strategia di sostituzione
comune è l'elitarismo, in base al quale il miglior membro (o diversi membri migliori) della popolazione attuale
sopravvive sempre nella popolazione successiva, garantendo che un buon individuo non si perda tra
generazioni successive.
Alcune applicazioni GA utilizzano operatori di affollamento per integrare la loro strategia di sostituzione. Al fine
di incoraggiare la diversità nella popolazione delle codifiche di soluzione, una nuova soluzione figlio può
entrare nella popolazione solo sostituendo l'attuale membro della popolazione che è più simile a sé stesso,
evitando di avere troppi individui simili nella nuova popolazione.
3.3.7 Scelta dei parametri
Quando si applicano i GA ai problemi del mondo reale, l'utente deve scegliere i valori per diversi parametri tra
cui il tasso di mutazione, il tasso di crossover e le dimensioni della popolazione, oltre a selezionare la forma di
selezione, la strategia di sostituzione, ecc..
EVOLUTION STRATEGIES *
Le strategie di evoluzione (ES) sono state ampiamente utilizzate come strumento per risolvere problemi di
ottimizzazione a valori reali e sono state applicate con successo anche all'ottimizzazione combinatoria,
all'ottimizzazione vincolata e all'ottimizzazione multiobiettivo. Due caratteristiche degne di nota di ES sono che
utilizza tipicamente una rappresentazione a valori reali (sebbene esistano versioni binarie e integer di ES) e che
si basi principalmente sulla selezione e sulla mutazione per guidare il processo evolutivo. La maggior parte
delle applicazioni di ES incorporano l'auto-adattamento, in quanto l'algoritmo altera il suo tasso di generazione
della diversità in risposta al feedback durante il processo di ottimizzazione. Sebbene negli ultimi anni l'idea di
EA adattativi sia diventata molto diffusa, ES è stata la prima famiglia di EA a incorporare l'auto-adattamento
come parte integrante del suo algoritmo.
4.1 THE CANONICAL ES ALGORITHM
Sebbene le persone si riferiscano spesso a ES (o addirittura a GA) come se fosse un singolo algoritmo, è più
accurato visualizzare ES come una famiglia di algoritmi. Nell’algoritmo 5.1 descriviamo una forma base (non
auto adattiva) di ES. Supponiamo che l'oggetto sia quello di trovare il vettore dei numeri reali 𝑥 =
1
𝑛
𝑛
che è associato a una funzione. Esistono molti modi in cui è possibile adattare lo
pseudocodice precedente per produrre algoritmi ES alternativi. La popolazione può essere inizializzata in modi
diversi (casuali o meno) e la generazione dei figli potrebbe derivare esclusivamente dalla mutazione o potrebbe
anche impiegare un operatore di ricombinazione. Potrebbero essere applicate anche molteplici strategie di
selezione e sostituzione.
4.2 (1 + 1)-ES
Negli studi iniziali delle strategie di
evoluzione l'attenzione era focalizzata su uno
schema a genitore singolo e figlio singolo,
noto come (1 + 1) - ES. In questo schema
l'intera popolazione è composta da un
genitore che dà origine a un singolo figlio. Il
genitore e il suo bambino competono quindi
per sopravvivere alla generazione successiva.
Quindi, questo schema consiste in una ricerca
point-to-point dello spazio della soluzione. Un
problema pratico con questo approccio è che può comportare un lento progresso verso regioni migliori dello
spazio della soluzione.
4.3 (Μ + Λ)-ES AND (Μ, Λ)-ES
Dopo la sperimentazione iniziale con lo schema (1 + 1), l'attenzione è stata focalizzata su genitori singoli e figli
multipli, schemi (1, λ) e (1 + λ). In questi approcci, il genitore produce λ figli. Ognuno dei bambini viene
generato mutando i singoli elementi del vettore del genitore usando un'estrazione casuale da N (0, σ), una
distribuzione normale. Nel caso di (1, λ) il migliore dei figli λ sopravvive nella generazione successiva, mentre
nel caso di (1 + λ), il genitore originale viene sostituito solo se uno dei suoi figli λ è migliore. Più in generale,
possono esserci più genitori, più figli, schemi ES, indicati come (μ + λ) - ES e (μ, λ) - ES. In entrambi questi
schemi, i genitori vengono selezionati casualmente (con sostituzione) da μ. Dopo che questi genitori sono stati
mutati per produrre i figli λ (λ μ), viene implementato un processo di selezione per decidere quale dei genitori e
dei figli sopravviverà alla generazione successiva. All'aumentare del valore di λ aumenta anche la pressione
selettiva dell'algoritmo. La natura della fase di selezione dipende da quale degli schemi viene utilizzato. Nel
primo schema, (μ + λ), l'intera popolazione di genitori e figli compete per la sopravvivenza nella generazione
successiva, con i migliori μ. Nel secondo schema, tutti i sopravvissuti sono selezionati dall'insieme di figli λ in
modo che ogni individuo abbia una durata di un solo periodo. Pertanto, (μ + λ) corrisponde a una strategia di
sostituzione elitaria, poiché una buona soluzione nella popolazione iniziale può scomparire solo se sostituita da
un figlio migliore, mentre lo schema generazionale (μ, λ) non garantisce la sopravvivenza di un buon genitore
nella prossima generazione. Nonostante ciò, lo schema di sostituzione (μ, λ) è più comunemente utilizzato nelle
applicazioni ES in quanto lo scarto di tutti i genitori rende più facile alla popolazione migrare lontano
dall'ottima locale.
4.4 MUTATION IN ES
Ogni individuo in ES è tipicamente rappresentato come un vettore di valori reali, x = (x1, ..., xn). Associato a
questo vettore è un insieme di parametri di strategia. Questo set può contenere un singolo valore o, in
alternativa, uno o più valori per ogni elemento nel vettore della soluzione. Nel caso più semplice di mutazione,
ignorando inizialmente l'auto-adattamento, è possibile impostare un valore di vettore di strategia singolo 𝜎.
Applicando la fase di mutazione al vettore di soluzione di un genitore, viene quindi formato un vettore figlio
applicando addizionalmente un numero casuale r estratto da una distribuzione gaussiana 𝑁 ( 0 , 𝜎) (dove il
valore di σ è scelto dall'utente) per ciascun elemento del vettore genitore. Quindi, il vettore 𝑥 (𝑡) diventa 𝑥 (𝑡 +
1 ) = 𝑥 (𝑡) + 𝑟. Supponendo che il valore di 𝜎 sia relativamente piccolo, la maggior parte delle mutazioni sarà
corrispondentemente piccola, con occasionali mutazioni più grandi. Il parametro 𝜎 è indicato come dimensione
del passo di mutazione poiché svolge un ruolo critico nel determinare l'effetto dell'operatore di mutazione.
Anche se questo meccanismo di mutazione è facile da implementare, esso presenta due problemi evidenti: non
riesce a considerare il ridimensionamento di ogni dimensione nello spazio della soluzione, e la dimensione del
passo di mutazione non è sensibile allo stadio del processo di ricerca.
Il primo problema sorge quando elementi differenti del vettore di soluzione di un individuo possono avere una
scala molto variabile. Quindi, un valore adatto di 𝜎 per una dimensione potrebbe non essere adatto per un altro.
Il secondo problema sorge anche a causa del valore fisso per 𝜎.
È possibile utilizzare due approcci di base per adattare i parametri della strategia mentre viene eseguito
l'algoritmo. È possibile applicare uno schema deterministico come la regola 1/5 di successo, oppure è possibile
consentire l'evoluzione dei parametri della strategia.
4.5 RECOMBINATION
Sebbene le implementazioni iniziali di ES si siano concentrate sull'uso di un operatore di mutazione per
generare diversità, ES può anche includere un operatore di ricombinazione o crossover. In questo caso,
l'algoritmo canonico è alterato in quanto i figli λ sono inizialmente creati applicando iterativamente l'operatore
di ricombinazione e successivamente un operatore di mutazione come già descritto. L'operatore di
ricombinazione in ES produce in genere un singolo figlio. ES non impone l'obbligo per un figlio di avere due
genitori. Per indicare il numero di genitori utilizzati, la notazione ES standard (μ + λ) ES e (μ, λ) - ES può essere
estesa a (μ / ρ, + λ) - ES e (μ / ρ, λ) - ES dove ρ ≤ μ (ρ è noto come numero di mescolamento) è il numero di
genitori che si combinano per produrre un singolo figlio. Nell'applicare ripetutamente l'operatore di
ricombinazione per generare μ figli, i genitori possono essere selezionati usando una metodologia basata sulla
fitness, ma generalmente vengono selezionati casualmente. Due approcci alla ricombinazione sono
comunemente visti in ES, discreto e intermedio. Nella ricombinazione discreta, uno dei valori principali viene
selezionato casualmente per ciascun dei valori reali che costituiscono il vettore della soluzione figlio. Nella
ricombinazione intermedia, viene calcolato al media dei valori dei genitori genitoriali per ogni elemento del
figlio. Più in generale, la ricombinazione intermedia può essere una qualsiasi combinazione lineare dei due
valori genitore. La Figura 5.1 illustra ciascuna forma di ricombinazione nel caso in cui un bambino abbia due
genitori. Questo è indicato come ricombinazione locale. Una seconda forma di ricombinazione chiamata
ricombinazione globale viene anche utilizzata in ES. Nella ricombinazione globale, per ogni elemento del
vettore figlio, due (o più) genitori vengono estratti a caso dalla popolazione e il valore del figlio viene ottenuto
usando i valori dei genitori casuali come già discusso.
ARTIFICIAL IMMUNE SYSTEMS
L’immunocomputing si ispira all’abilità di problem solving del sistema immunitario. Il sistema immunitario
protegge il nostro corpo dalle infezioni causate da agenti patogeni (virus, batteri, funghi e parassiti);
Esso si divide in innato (capace di riconoscere generiche forme di molecole presenti solo negli agenti patogeni e
mai in organismi/cellule propri del corpo umano) ed adattivo (riconosce patogeni che non sono riconosciuti da
quello innato e mantiene una memoria sui pattern conosciuti).
Le capacità del sistema immunitario naturale comprendono la capacità di riconoscere, distruggere e ricordare
un numero quasi illimitato di agenti patogeni (oggetti estranei o nonself che possono entrare nel corpo, come
virus, batteri, parassiti e funghi multicellulari) e anche di proteggere il l'organismo da cellule self squilibrate.
Gli algoritmi AIS più comuni possono essere raggruppati in quattro categorie (Figura).
Prima di iniziare a trattare della metafora e poi degli algoritmi definiamo alcuni termini:
- Agenti patogeni: corpi estranei inclusi virus, batteri, parassiti multicellulari e funghi.
- Antigeni: qualsiasi molecola che il sistema immunitario possa riconoscere. Gli antigeni possono essere
nonself, per esempio, molecole estranee espresse da un agente patogeno. Gli antigeni possono anche
corrispondere alle molecole self.
- Leucociti: globuli bianchi, compresi fagociti e linfociti (cellule B e T), per identificare e uccidere i
patogeni.
- Anticorpi: glicoproteine (proteine + carboidrati) rilasciate nel sangue in risposta a uno stimolo
antigenico che neutralizza l'antigene legandosi specificatamente ad esso.
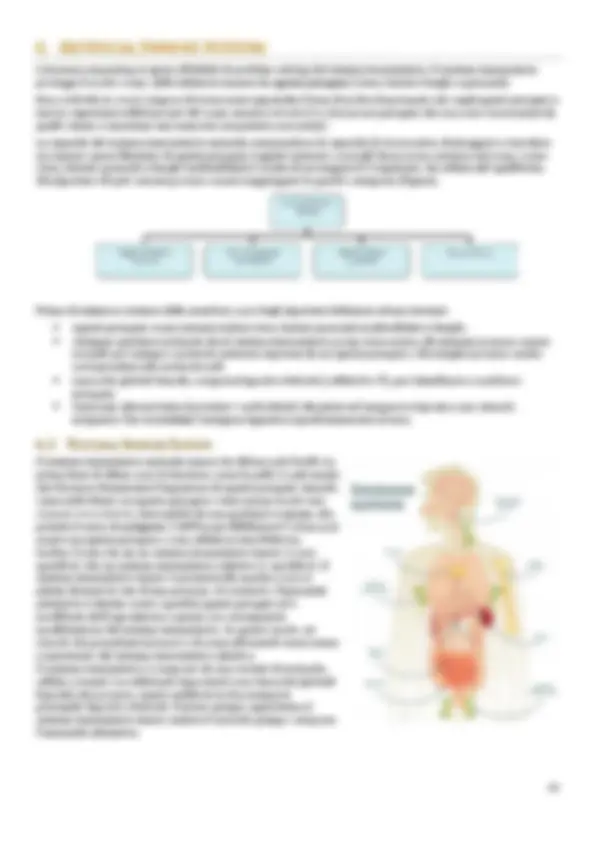
6.1 NATURAL IMMUNE SYSTEM
Il sistema immunitario naturale umano ha difese a più livelli. Le
prime linee di difesa sono le barriere, come la pelle e i peli nasali,
che bloccano fisicamente l'ingestione di agenti patogeni. Quando
viene individuato un agente patogeno viene messa in atto una
risposta immunitaria , innescabile da una qualsiasi sostanza, che
prende il nome di antigene (“ANTIcorpi GENEratore”). Esso può
essere un agente patogeno o una cellula morta/difettosa.
Inoltre, l'uomo ha sia un sistema immunitario innato (o non
specifico) che un sistema immunitario adattivo (o specifico). Il
sistema immunitario innato è presente alla nascita e non si
adatta durante la vita di una persona. Al contrario, l'immunità
adattativa è diretta contro specifici agenti patogeni ed è
modificata dall'esposizione a questi, con conseguente
modificazione del sistema immunitario. In questo modo, un
ricordo dei precedenti invasori e di come affrontarli viene creato
e mantenuto dal sistema immunitario adattivo.
Il sistema immunitario è composto da una varietà di molecole,
cellule e tessuti. Le cellule più importanti sono leucociti (globuli
bianchi) che possono essere suddivisi in due categorie
principali: fagociti e linfociti. Il primo gruppo appartiene al
sistema immunitario innato mentre il secondo gruppo compone
l'immunità adattativa.
I globuli bianchi ( leucociti ) circolano nel corpo attraverso i vasi sanguigni e quelli linfatici, sorvegliando
costantemente il corpo umano alla ricerca di patogeni. Quando trovano un bersaglio, cominciano a moltiplicarsi
e mandare segnali alle cellule di altro tipo di fare lo stesso.
I nostri globuli bianchi sono immagazzinati in diverse zone del corpo dette organi linfoidi. Questi includono:
- Timo: una ghiandola tra i polmoni e appena sotto il collo.
- Milza: un organo che filtra il sangue. Si trova nella parte superiore sinistra dell'addome.
- Midollo osseo: trovato nel centro delle ossa, produce anche globuli rossi.
- Linfonodi: piccole ghiandole posizionate in tutto il corpo, collegate da vasi linfatici.
È possibile inoltre distinguere diverse tipologie di linfociti:
- FAGOCITI: circondano e assorbono gli agenti patogeni e li abbattono “mangiandoli”.
- LINFOCITI: aiutano il corpo a ricordare invasori e riconoscerli qualora riattaccassero. Questi nascono nel
midollo osseo; alcuni rimangono nel midollo e si sviluppano in linfociti B (cellule B), altri si dirigono verso il
timo e diventano linfociti T (cellule T).
Questi due tipi di celle hanno ruoli diversi: le cellule B producono gli anticorpi e aiutano a mettere in
guardia i linfociti T; le cellule T eliminano le cellule compromesse presenti nel corpo e aiutano a mettere in
guardia altri leucociti. Esistono diversi tipi di linfociti T:
o Cellule T helper (cellule Th): coordinano la risposta immunitaria. Alcuni comunicano con altre
cellule e alcuni stimolano le cellule B a produrre più anticorpi. Altri attraggono più cellule T o
fagociti.
o Cellule T killer (linfociti T citotossici): come suggerisce il nome, queste cellule T attaccano altre
cellule. Sono particolarmente utili nel riconoscere virus e cellule infette.
6.1.1 Innate Immune System
Il sistema immunitario innato utilizza un certo numero di firme affidabili di estraneo o nonself, come i pattern
molecolari associati ai patogeni (PAMP), per identificarli. I PAMP sono schemi molecolari ampiamente condivisi
dai patogeni ma non dalle molecole self. Se viene rilevata una firma nonself, il sistema innato attiva una risposta
infiammatoria in cui i componenti del sistema immunitario tentano di attaccare l'invasore e arrestarne la
diffusione. La risposta infiammatoria provoca sintomi quali arrossamento e gonfiore che possono verificarsi in
punti di ferita. La risposta infiammatoria è avviata dai recettori Toll-like (TLR).
Questi riconoscono i PAMP, che sono di vitale importanza per la sopravvivenza di agenti patogeni come batteri,
virus, funghi e parassiti. Sembra che i TLR si siano evoluti nel tempo per riconoscere le molecole che sono
componenti fondamentali di una vasta gamma di agenti patogeni e la capacità di riconoscere queste molecole è
stata codificata nel nostro genoma. Pertanto, i TLR svolgono un ruolo chiave nell'identificazione del tipo di
patogeno invasore e mobilitano la parte appropriata del sistema immunitario quando richiesto. L'allarme
emesso dal sistema immunitario innato quando vengono rilevate molecole estranee è segnalato da proteine
note come citochine che non solo inducono la risposta all'infiammazione del sistema immunitario innato, ma
attivano anche le cellule B e T necessarie per la risposta adattativa.
Le citochine sono prodotte da varie cellule del sistema, compresi macrofagi e cellule dendritiche, entrambe
dotate di TLR. I macrofagi circolano nel corpo alla ricerca di segni di infezione. Se li scoprono, impostano la
risposta infiammatoria, sommergono l'invasore e secernono citochine che sollevano un allarme generale del
sistema immunitario per reclutare altre cellule nel sito di infezione. Le cellule dendritiche ingeriscono e
successivamente presentano frammenti dell'antigene patogeno alle cellule T nei linfonodi e rilasciano citochine
di segnalazione che indicano il livello di pericolo associato a quell'antigene.
6.1.2 Adaptive Immune System
Se il sistema immunitario innato non può rimuovere rapidamente un agente patogeno, il sistema immunitario
adattivo entra in azione. Un ruolo chiave viene svolto in questo processo dai linfociti che circolano
costantemente attraverso il sangue. Un importante componente della popolazione di linfociti è costituito da
cellule B e T prodotte nel midollo osseo.
Le cellule B e T sono in grado di riconoscere e rispondere a determinati modelli non antigenici (molecole
estranee) presentati sulla superficie dei patogeni (nel caso delle cellule T) o dell'antigene che è stato espresso
da un agente patogeno invasore (nel caso delle cellule B). Un ruolo importante nel processo di riconoscimento
delle cellule T è svolto dalle molecole.
Queste molecole agiscono per trasportare peptidi (frammenti di catene proteiche) dalle regioni interne di una
cellula e presentano questi peptidi sulla superficie della cellula. Questo meccanismo consente ai componenti del
sistema immunitario di rilevare le infezioni all'interno delle cellule senza dover penetrare nella membrana