Scarica DISPENSE DATA ANALYSIS e più Sintesi del corso in PDF di Statistica solo su Docsity!
DATA ANALYSIS
dati - > 24 , 23 , 24 , 22 , 26 tabella di frequenza (distribuzione di frequenza) - > x n 22 1 23 1 24 2 26 1 questa tabella ci dà tutta l’informazione dei miei dati, ma non ho un’idea chiara di ciò di cui sto parlando. Essendo poco maneggevole, bisogna sintetizzare il gruppo di dati. I metodi più usati per farlo sono le MISURE DI TENDENZA CENTRALE:
- la MEDIA = (X 1 +X 2 +...Xx)/n oppure ΣXi/n (nel nostro esempio è 23 , 8 )
- la MODA = il valore a cui corrisponde la frequenza più alta (nel nostro esempio è 24 )
- esistono le distribuzioni BIMODALI
- la MEDIANA = quel punto della distribuzione, tale che rispetto a quel valore il 50 % dei dati sia minore e l’altro 50 % sia maggiore (nel nostro esempio è 24 ) - quando i valori in mezzo sono pari, per scoprire la mediana si fa la media tra i due La media si può scrivere: μ - > popolazione 𝑥 - > campione La media è sensibile a ogni singolo dato. Al contrario, la mediana è robusta
lezione di ripasso Le misure di dispersione - > esprimono la variabilità dei dati, ossia la tendenza delle singole osservazioni di una distribuzione di allontanarsi dalla tendenza centrale (la media)
- se la distanza dei valori dalla media è poca - > scarti bassi
- se la distanza dei valori dalla media è tanta - > scarti alti Per sintetizzare gli scarti si utilizza la più importante misura di dispersione, ossia la VARIANZA - > (xi - μ) 2 Un’altra misura di dispersione molto utilizzata è la deviazione standard (o scarto quadratico medio) - > √(xi - μ) 2 lezione La classificazione dei software per data science
- per ambito di applicazione
- per politica commerciale (freeware - > software distribuito gratuitamente e senza bisogno di licenza d'uso, es. antivirus e shareware - > software limitato, es. limitazioni di tempo)
- tipo di utilizzo/facilità d’uso Tutte le analisi si basano su matrici di dati unità per variabili
- n righe - > unità statistiche (casi, osservazioni)
- k colonne - > variabili (attributi, feature) Ogni variabile viene interpretata come una dimensione, mentre ogni unità viene interpretata come un punto nello spazio a k dimensioni I dati possono essere:
- numerici (quantitativi) - > rappresentano informazioni intrinsecamente numeriche si può eseguire ogni tipo di calcolo
- categorici (qualitativi) - > non si possono eseguire operazione aritmetiche si possono calcolare frequenze e percentuali a. nominali (es. marca) b. ordinali: categorie ordinate, ma distanze non uguali es. scale di Likert (per niente, poco, così così, abbastanza, molto) I dati binari (dicotomici) sono dati nominali, quindi categorici, ma si possono usare come numerici in molte analisi (quindi fare tutte le operazioni limitate ai dati numerici, es. la media) - > un dato categorico con k categorie si può trasformare in k dati binari Nel primo caso posso scegliere solo un dato, nel secondo caso posso scegliere più dati (il dato categorico si trasforma in più dati numerici)
Per individuare gli outlier si usano strumenti grafici e statistici. Come vengono trattati? - > eliminazione: valori mancanti (se siamo sicuri che siano errori); ranking: sostituisce i dati con l’ordinamento; capping: 𝑥 > 𝑥𝑚𝑎𝑥 → 𝑥 = 𝑥𝑚𝑎𝑥 Una volta puliti, per lavorare meglio, avviene la trasformazione dei dati numerici:
- annullare le di�erenze di scala e di variabilità tra le variabili a. standardizzare - > media 0 , varianza 1 (ridurre tutte le variabili)
b. normalizzare - > intervallo [ 0 , 1 ]
c. discretizzare - > separare in classi
- migliorare la distribuzione dei dati, ridurre l'asimmetria e il numero di outlier Per feature extraction si intende la generazione di nuove variabili da quelle originali, che ci danno un’informazione nuova e aggiuntiva. Ad esempio:
- creazione di variabili dummy - > presenza/assenza di una certa caratteristica
- popolazione e superficie - > densità
- altezza e peso - > BMI
- località - > coordinate geografiche
- GDO: dettaglio scontrini - > aggregazione per scontrino; scontrini - > aggregazione per cliente (carta fedeltà); cliente - > frequenza di acquisto, spesa mensile… La probabilità è una misura delle possibilità che un evento possa verificarsi
- definizione frequentista : quando il numero di prove tende ad infinito:
p = 1 evento certo
p = 0 evento impossibile la somma delle probabilità di tutti gli eventi possibili è pari a 1 : Le distribuzioni di probabilità sono generalizzazioni delle distribuzioni di frequenza, le quali sono in genere basate su dati osservati (campionari) - > le distribuzioni di probabilità sono i corrispondenti modelli teorici di riferimento. Si distinguono
distribuzioni discrete e continue che sono sostanzialmente molto diverse, a causa di una intrinseca di�erenza tra i due tipi di variabili
l
- variabile discreta - > distribuzione discreta - > la probabilità è concentrata nei punti
- variabile continua - > distribuzione continua - > la probabilità è l’area sottostante alla curva
se lancio di un dato, la probabilità che mi esca un valore presente sul dato è ⅙
cosa succede se lancio due dati?
esempio: la somma dei valori del dado rosso e del dado blu
Caso reale delle distribuzioni discrete: il call center modello teorico
- successo - > prendere la linea/trovare la persona
- tentativi ripetuti
- i tentativi sono indipendenti (i tentativi nuovi non sono influenzati da quelli vecchi)
- la probabilità è la stessa a ogni tentativo eventi, distribuzioni, probabilità
- probabilità di prendere la linea/trovare la persona con un tentativo solo
- probabilità di chiamare n volte per prendere la linea, cioè di riuscire la prima volta al tentativo n-esimo
- probabilità di trovare k persone in n tentativi
- probabilità di dover fare n tentativi per trovare k persone
La distribuzione continua si presenta come una curva, e la probabilità delle variabili consiste nell’area sotto la curva
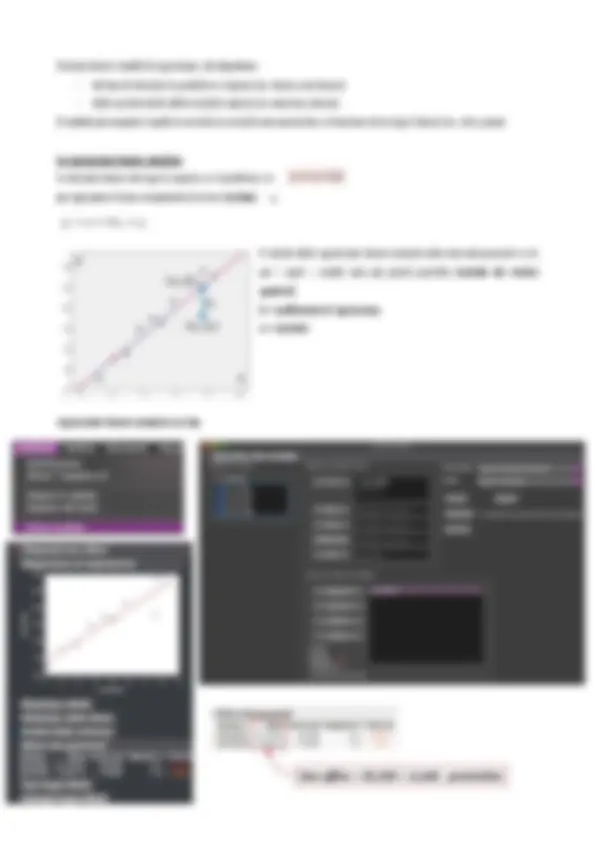
- l’area sotto la curva tra a e b rappresenta la probabilità che X sia compresa tra a e b - > : 𝑷𝒓𝒐𝒃(𝒂 ≤ 𝑿 ≤ 𝒃)
- l’area totale sotto la curva è uguale a 1
- la probabilità in un singolo punto è uguale a 0
Alcuni valori convenzionali: 68 %, 95 % e 99 %
analisi univariata - > una variabile alla volta statistiche descrittive: frequenze, media, varianza… analisi bivariata - > studia la relazione tra due variabili: numerica/numerica, numerica/categorica, categorica/categorica analisi multivariata - > k variabili alla volta modelli statistici, machine learning… Per relazioni bivariate tra dati numerici, si intende l’ andamento relativo di una variabile rispetto all’altra
- concordanza: a valori elevati di una variabile corrispondono perlopiù valori elevati dell'altra
- discordanza: a valori elevati di una variabile corrispondono perlopiù valori bassi dell'altra La covarianza è un indice che permette di verificare la relazione lineare tra due variabili statistiche - > variabili x e y con media μ x e μ y e deviazione standard σ x e σ y covarianza minima: Cov(X,Y) = 0 nessuna relazione covarianza massima: |Cov(X,Y)| = σX σY relazione perfetta, punti allineati La covarianza dipende dall’ordine di grandezza delle variabili, ossia dal loro valore; per eliminare questa dipendenza la si può normalizzare attraverso questa formula:
Il coe�ciente di correlazione è una misura specifica usata nell'analisi della correlazione per quantificare la forza della relazione lineare tra due variabili, ed è un valore compreso tra - 1 e + 1
- tra 0 , 50 e 1 : correlazione forte
- tra 0 , 30 e 0 , 49 : correlazione —-------media
- tra 0 e 0 , 29 : correlazione debole Il coe�ciente di correlazione misura la presenza di relazioni lineari, senza implicare però un relazione di causa-e�etto: a�erma solo che tra due variabili c’è una relazione sistematica, ma non che una determina l’altra Per le correlazioni spurie si intende ad una dipendenza da una variabile comune o pura casualità esempio: di�erenza tra covarianza e correlazione dopo la normalizzazione matrice di covarianza
matrice di correlazione (valori tra - 1 e + 1 )
La relazione tra una variabile numerica e una variabile categorica si analizza mediante le di�erenze in media. La variabile categorica identifica dei gruppi, e si confrontano in seguito le medie della variabile numerica all’interno di quei gruppi
- se le medie nei gruppi sono diverse, allora c’è relazione tra la variabile categorica e quella numerica
- se le medie nei gruppi sono uguali, non c’è relazione tra la variabile categorica e quella numerica
Gli istogrammi mostrano la distribuzione di frequenza di una variabile numerica
I grafici a barre rappresentano frequenze o altri indici (es. la media) di variabili categoriche e sono tipicamente decrescenti I grafici a torta e ad anello mostrano la distribuzione di una variabile categorica ( Σ = 100 %). Il limite dei grafici a torta è che non mostrano chiaramente le relazioni tra le parti. Da evitare sono le versioni 3 D dei grafici 2 D (problemi di prospettiva)
Nei grafici a linea nell’asse verticale c’è sempre la variabile numerica, mentre nell’asse orizzontale c’è una variabile numerica o ordinale (di solito date)
I grafici a dispersione e a bolle rappresentano due variabili numeriche in un piano cartesiano, e le bolle aggiungono una terza dimensione
Terza dimensione bolle - > PIL pro capite
- più la bolla è grande, più è alto il —-------PIL
- più la bolla è piccola, più è basso —--------il PIL Il colore delle bolle può aggiungere una quarta dimensione
Best practice: KISS - keep it short and simple
- adattare il grafico all’audience
- mostrare i valori, usare etichette, titoli e legenda
- evitare livelli di precisione inutili
- per confrontare grafici usare scale e basi di dati coerenti
- evitare distorsioni e forzature dei dati
La data visualization:
- grafici multipli simultanei, combinati in una dashboard
- interattività: modifiche ai grafici facili, rapide e reversibili
- grafici collegati tra loro: le operazioni fatte su uno si riflettono su tutti
“Una visualizzazione di dati deve essere bella solo se la bellezza può favorire la comprensione” - Should Data Visualizations Be Beautiful?, S. Few, 2012 “ Se i numeri sono noiosi allora avete quelli sbagliati. Il presupposto etico per operare nell’information design dovrebbe essere che i nostri lettori sono svegli e interessati; possono avere da fare, essere ansiosi di passare oltre, ma non sono stupidi” - Envisioning Information, E. Tufte, 2022 La statistica inferenziale opera su campioni di una popolazione e il suo obiettivo è estendere alla popolazione i risultati ottenuti sul campione Lo scopo delle stime campionarie è calcolare un parametro della popolazione (es. media, percentuale, indici vari…), e quella che si ottiene dal campione (statistica campionaria) è una stima del parametro - > la stima varia da campione a campione, è a sua volta una variabile casuale. In tutti i casi di interesse pratico, la distribuzione teorica della statistica campionaria (distribuzione campionaria) è nota, ed è la base della statistica inferenziale La statistica ha un modo caratteristico di fornire le sue stime:
- la stima puntuale è il valore della statistica campionaria
- la stima intervallare (intervallo di confidenza) è la stima puntuale ampliata con l’ errore campionario
Il trade-o� negli intervalli di confidenza (semi)ampiezza dell’IC della media al 95 % = 1 , 96 ∙ 𝜎√ n
ampiezza dell’intervallo ~ precisione
livello di confidenza ~ a�dabilità se si alza il livello di confidenza (es. da 95 % a 99 % → maggiore a�dabilità), l’ampiezza dell’intervallo aumenta (si passa da 1 , 96 a 2 , 57 → minore precisione). Per migliorare l’a�dabilità senza peggiorare la precisione, e viceversa, bisogna aumentare la numerosità del campione Reverse engineering - > la formula: 𝑒𝑟𝑟𝑜𝑟𝑒 = 1 , 96 ∙ 𝜎/√ n può essere utilizzata al contrario per stimare a priori la numerosità del campione La formula rispetto a n fornisce la numerosità n necessaria in base a: - il livello di confidenza scelto (es. 95 % - > 1 , 96 ) - una stima di 𝜎 - il massimo di errore accettabile esempio calcolo della numerosità campionaria si vuole stimare la media della popolazione con: - livello di confidenza 95 % - errore massimo ± 1 - stima di 𝜎 = 8 - > occorre quindi un campione di 246 casi
sommario
Lo scopo della verifica delle ipotesi è fornire criteri razionali per decidere se accettare o respingere delle ipotesi Il paradigma della statistica classica è
formulazione dell’ipotesi l’obiettivo è trarre conclusioni su due a�ermazioni contrastanti relative a un parametro della popolazione 𝑯𝟎 : ipotesi nulla - > la situazione teorica "nota" (es. 𝐻 0 : la media è uguale all'anno scorso) 𝑯𝟏 : ipotesi alternativa - > l'opposto di 𝐻 0 (es. 𝐻 1 : la media è diversa dall'anno scorso)
esperimento statistico si individua una statistica campionaria di distribuzione nota adatta a testare l'ipotesi nulla e la si calcola su un campione. Si assume che 𝐻 0 sia vera e ci si chiede: se è vera, qual è la probabilità di ottenere per caso un valore della statistica test uguale o più estremo di quello osservato nel campione? Si usa la distribuzione campionaria per calcolare questa probabilità ( p-value)
accettazione o rifiuto dell’ipotesi nulla si confronta il p-value col livello di significatività scelto (es. 0. 05 ) - > 0. 05 è il livello convenzionale più usato, ma altri livelli sono possibili
- p-value < 0. 05 allora il test è statisticamente significativo - > si rifiuta l’ipotesi nulla 𝑯 0 e si accetta 𝐻 1
- p-value > 0. 05 allora il test non è statisticamente significativo - > si accetta l’ipotesi nulla 𝑯 0 es. 𝐻 0 : la media è uguale all'anno scorso se p-value = 0. 02 - > p < 0. 05 - > la media è diversa se p-value = 0. 12 - > p > 0. 05 - > la media è uguale
Test della indipendenza tra variabili categoriche χ² (chi-quadrato) è una misura della distanza dall’indipendenza χ² = 0 - > indipendenza χ² >> 0 - > dipendenza χ² = 71. 58 ( p-value - > l’area a destra di quel punto nella distribuzione)
Le ipotesi: l'ANOVA verifica se almeno due medie sono diverse, non dice quali medie sono diverse 𝐻 0 : 𝜇 1 = 𝜇 2 = … = 𝜇𝑘 (tutte le medie sono uguali) 𝐻 1 : almeno due medie sono diverse tra loro ipotesi probabilistiche:
- le osservazioni devono essere indipendenti (casualità)
- la variabile numerica deve avere una distribuzione normale e varianza uguale in tutti i gruppi La statistica campionaria test per l'ANOVA si chiama 𝐹 e ha una distribuzione 𝐹 con due parametri (gradi di libertà) 𝐹 ≈ 1 → medie uguali (accettare 𝐻 0 ) 𝐹 ≫ 1 → medie diverse (rifiutare 𝐻 0 ) rapporto 𝐹 = 10 , 2850 - > 10 (?) Il p-value è la probabilità di ottenere valori ≥ 𝐹 :
- p-value "piccolo" (es. 𝑝 < 0 , 05 ) → test significativo: ci sono di�erenze statisticamente significative tra le medie
- p-value "grande" (es. 𝑝 > 0 , 05 ) → test non significativo: le di�erenza tra le medie si possono considerare casuali
Nella
variabile
numerica ci sono due fonti di variabilità:
- tra i centri dei gruppi (▲): devianza tra gruppi (between)
- all’interno dei gruppi (●): devianza entro i gruppi (within)
! la varianza nella prima distribuzione è più piccola rispetto la varianza nella seconda distribuzione!
Nel primo caso sono molto sicura che le medie sono diverse, perché la varianza è così piccola che l’oscillazione che proviene dalla casualità del campione, è praticamente nulla Nel secondo caso non sono più così sicura perché la varianza, e quindi l’oscillazione data dalla casualità del campione, è maggiore
!! attenzione alla di�erenza tra consumo e citazione: quelle dichiarate per intervistato sono tutte le marche consumate le citazioni sono le marche più consumate (max 6 )!!
- analisi della concorrenza ● analisi sugli attributi di marca o di prodotto ○ riduzione dimensioni ○ di�erenze tra marche ○ preference analysis (totale e per marca) ○ quadrant analysis
- segmentazione ● segmentazione dei prodotti, sugli attributi di prodotto ○ cluster analysis (k-means, attributi o fattori?) ○ mapping dei cluster ● segmentazione delle marche, sul consumo ○ cluster analysis gerarchica sul consumo (per intervistato) ● segmentazione delle marche, sugli attributi di marca ○ cluster analysis gerarchica (attributi o fattori? usare le medie)
- conclusioni ● sintesi dei risultati principali ● suggerimenti operativi o strategici ● possibili estensioni e approfondimenti consigli:
- creazione di file excel dove aggiungere mano mano i risultati utili
- precisare lo scopo di ogni analisi nel contesto applicativo (non come funzionano le tecniche)
- per le singole analisi precisate i risultati principali e le opzioni scelte e il perché (es. quale test, p-value, R 2 , varianza spiegata)
- curare soprattutto l'interpretazione dei risultati
ANALISI FATTORIALE
L’analisi è una tecnica multivariata che nasce dalla grande disponibilità di dati e quindi dal conseguente bisogno di sintetizzarli
- numerosità (più righe) - > aspetti computazionali: il tempo di elaborazione aumenta linearmente
- dimensionalità - > complessità del problema: il tempo di elaborazione aumenta più che linearmente, gli algoritmi tradizionali possono non funzionare più, ridondanza informativa e di�coltà di interpretazione
i motivi per cui si decide di ridurre la dimensionalità sono due:
- ridurre il numero delle variabili (aspetto prevalentemente tecnico)-> preprocessing dei dati per analisi successive
- riducendo la dimensionalità si riesce ad individuare strutture nelle relazioni tra le variabili - > sintesi di valutazioni espresse da intervistati, sintesi di dati secondari, generazione di KPI Per ridurre il numero delle variabili si può: generare nuove variabili da aggiungere a quelle originali nella matrice dei dati allo scopo di sostituirle nelle analisi
Individuare strutture nelle relazioni tra le variabili
Le sette variabili in realtà si possono raggruppare in due gruppi fondamentali (evidenziati in rosa nella tabella): età e debito (abbiamo scoperta una relazione che prima era nascosta nel nostro dataset) Esistono due tecniche diverse per la riduzione della dimensionalità:
- analisi fattoriale
- analisi delle componenti principali (PCA) di�eriscono per obiettivo prevalente, ipotesi, dettagli tecnici; ma danno in genere risultati simili