Scarica Informatica 3cfu obbligatori e più Slide in PDF di Elementi di Informatica solo su Docsity!
Introduzione all'informatica: Informatica come disciplina
La progettazione dei contenuti di questo insegnamento di Informatica si fonda sulla concezione dell'informatica come disciplina scientifica e non soltanto sul ruolo che l'informatica ha assunto nella società contemporanea. A tal fine, si riporta di seguito un passo significativo del Manifesto dell'Informatica , un documento ufficiale che il GRIN (http://www.grin-informatica.it), l'Associazione Italiana dei Docenti di Informatica, ha sottoscritto per definire il corretto approccio alla disciplina informatica e al suo insegnamento. L'informatica è un elemento essenziale della società moderna, non solo perché necessaria al normale svolgimento di quotidiane attività, ma anche in quanto il suo sviluppo plasma e determina quello dell'intera società. Non esiste campo dell'attività umana in cui le scoperte dell'informatica non abbiano lasciato il segno. L'uso del calcolatore, infatti, è uscito dai campi tradizionali del calcolo scientifico per entrare in tutte le aree della produzione industriale, dalla medicina all'editoria. Due miliardi di persone si collegano ad Internet. Centinaia di milioni di miliardi (il numero non è un errore di battitura) di transistor – i componenti elementari delle tecnologie dell'informazione – popolano i prodotti che ci circondano, dall'automobile all'elettrodomestico, dalla pompa di benzina al videogioco, per l'equivalente della metà del valore economico di questi oggetti. Centinaia di miliardi di istruzioni software, manifestazioni di intelligenza umana, animano questi componenti e attraverso di essi tutti i processi che caratterizzano la nostra società moderna. Nel linguaggio comune il termine “informatica” viene usato per riferirsi a tre aspetti tra loro distinti, seppur collegati:
- operativo: un insieme di applicazioni e manufatti (i computer);
- tecnologico: una tecnologia che realizza quelle applicazioni;
- culturale: una disciplina scientifica che fonda e rende possibile quella tecnologia. L’informatica come insieme di applicazioni è la percezione della persona comune; “conoscere l’informatica” significa “saper usare le applicazioni”. L’informatica come tecnologia è la percezione del tecnico (del perito, del laureato, dello specialista, ciascuno al suo livello di competenza); “conoscere l’informatica” significa in questo caso “saper realizzare le applicazioni”. L’informatica come scienza dovrebbe essere invece patrimonio di ogni persona con educazione superiore. Come i principi della fisica, della matematica o della chimica sono utili anche e soprattutto come modello interpretativo della realtà, e non perché chi li conosce possa diventare un fisico, un matematico, o un chimico, così i principi fondamentali dell’informatica sono in grado di fornire modelli di interpretazione e una strumentazione culturale utile nella vita comune della persona colta che deve affrontare le sfide del mondo moderno. In altre parole, si può pensare all'informatica come alla scienza che si occupa dei seguenti temi:
lo studio dei fondamenti teorici della scienza dell'informazione;
la definizione di algoritmi per l'elaborazione automatica delle informazioni;
la realizzazione (implementazione) di questi algoritmi;
e, infine, l’uso del calcolatore.
In definitiva, l’informatica non riguarda i computer più di quanto l’astronomia riguardi i telescopi. Lo studio dell'informatica è quindi importante perché:
lo sviluppo di algoritmi consente di accrescere le facoltà creative, logiche e cognitive dell'individuo;
l’informatica è intrinsecamente multidisciplinare : ogni disciplina prevede una opportuna forma di organizzazione e
trattamento delle informazioni;
l’informatica offre strumenti per modellare i formalmente problemi e poterne affrontare la risoluzione in modo efficiente ed
efficace;
le tecnologie dell'informazione sono diventate strategiche in numerosi ambiti applicativi. Esse non solo semplificano lo
svolgimento di compiti realizzabili anche senza calcolatore, ma offrono vantaggi sul lungo termine altrimenti non accessibili. Branche dell'informatica Nel sentire comune, l'informatica è vista come una disciplina monolitica. Ogni volta che si pensa ad un informatico, si immagina un esperto capace di risolvere qualsiasi problema legato all'uso dei calcolatori. In realtà l'informatica è una disciplina complessa dove si possono riconoscere numerose specializzazioni. Pertanto è possibile, per non dire frequente, che un esperto sviluppi le proprie competenze rispetto a un sottoinsieme di specializzazioni. A titolo esemplificativo, senza alcuna pretesa di completezza, elenchiamo alcune specializzazioni della disciplina informatica:
Informatica teorica
o Teoria dell'informazione
o Teoria della computazione
o Algoritmi e strutture dati
o Teoria dei linguaggi di programmazione
Informatica applicata
o Architettura dei calcolatori
o Sistemi e architetture ( Information Technology - IT)
o Reti di calcolatori
o Basi di dati
o Sicurezza informatica e crittografia
o Interazione uomo-macchina
o Intelligenza artificiale
o Elaborazione digitale dei segnali
o Programmazione
Sviluppo software
Sviluppo web
Sviluppo sistemi integrati
Inoltre l'informatica può essere coniugata ad altre discipline per dare vita a branche multidisciplinari come ad esempio bioinformatica , chimica computazionale , robotica , computer grafica e musicologia computazionale. Storia dell'informatica e nascita del calcolatore Perché si possa arrivare all'informatica come la intendiamo oggi è stato necessario sviluppare parallelamente due diversi aspetti: quello tecnologico e quello filosofico (in particolare logico-matematico). La serie di eventi, idee e scoperte che culmina con i moderni calcolatori ha quindi una moltitudine di protagonisti, disseminati in un arco temporale di almeno 4000 anni, con molte storie parallele. Per quanto il racconto possa essere avvincente e ricco di colpi di scena, non è questa la sede per una esposizione esaustiva. Ci si limiterà pertanto a citare solo alcuni degli aspetti cruciali: quelli più funzionali alla comprensione del pensiero informatico e del funzionamento del calcolatore. Il termine calcolatore designa genericamente un sistema di elaborazione dati, nato in forma meccanica, sviluppatosi in forma analogica e giunto poi alla forma digitale. Generazione 0: I calcolatori meccanici Il più antico strumento di calcolo fu l’abaco, in uso già 4000 anni fa in Cina. Dopo di esso molte furono le scoperte in questo ambito, ma la maggior parte di esse (come ad esempio la pascalina ideata nel 1642 da Blaise Pascal) non vennero mai realizzate. Nel 1702, Gottfried Wilhelm Leibniz sviluppò la logica come disciplina matematica e formale, con i suoi scritti sul sistema numerico binario. Nel suo sistema, l'uno e lo zero rappresentano i valori vero e falso. Questo non ebbe un effetto immediato, ma fu decisivo nel secolo successivo. I primi veri progenitori dell’elaboratore moderno videro la luce agli inizi del XIX secolo. Nel 1804 Joseph Marie Jacquard introdusse una nuova tecnologia per i telai in grado di controllare il movimento di aghi, filo e tessuto attraverso schede perforate, automatizzando così la procedura di tessitura. A metà del XIX secolo, Charles Babbage elaborò una macchina di calcolo in grado di compiere operazioni aritmetiche, ma non fu mai realizzata. Fu Ada Lovelace (considerata oggi la prima programmatrice della storia), ad accorgersi delle vere potenzialità della macchina di Babbage: sebbene fosse stata progettata per svolgere solo calcoli matematici, Ada riconobbe la possibilità di programmare la macchina per altri fini. In questa versatilità risiede la principale differenza tra una calcolatrice tradizionale e un calcolatore. Nel 1854, le idee di Leibniz vennero riprese da George Boole, che pubblica la propria algebra booleana , creando un sistema nel quale è possibile trattare ogni relazione logica attraverso l'utilizzo di formule algebriche. Le operazioni (come l'addizione, la sottrazione e la moltiplicazione) vengono sostituite da operazioni logiche con valori di congiunzione, disgiunzione e negazione utilizzando solamente numeri binari (ossia costituiti dalle sole cifre 0 e 1). Alla fine del XIX secolo, Herman Hollerith, un funzionario statunitense dell’ufficio per il censimento, sviluppò una macchina tabulatrice, sempre a schede perforate, per automatizzare le operazioni di censimento. Il successo e la richiesta di queste macchine fu tale che nel 1896 Hollerith fondò la Tabulating Machine Company, che nel 1924 divenne la International Business Machine (IBM). Tra gli antenati degli anni '30 del calcolatore, figura il Memex, macchina immaginaria progettata da Vannevar Bush. L’idea era quella di un sistema di archiviazione di dati utilizzato a scopi personali. Il dispositivo era descritto come una scrivania dotata di schermi traslucidi, una tastiera, un set di pulsanti e delle leve. Il Memex avrebbe reso possibile la creazione da parte dell'utente di collegamenti tra foto e documenti, e per questo motivo viene oggi ricordato come primo supporto per l'approccio all' ipertesto. Sempre nella prima metà degli anni '30, Kurt Gödel enunciò i suoi famosi teoremi di incompletezza. Oltre a rappresentare un caposaldo nel campo della logica matematica, con importanti implicazioni di ordine filosofico, questi fecero da base per il lavoro di Alan Turing, matematico, logico e crittoanalista inglese. Egli formalizzò un modello di calcolatore universale (la Macchina di Turing, mai costruita realmente), dimostrò come ogni funzione calcolabile si possa eseguire attraverso un algoritmo installato su una Macchina di Turing, ma dimostrò anche come per alcuni algoritmi non sia possibile sapere a priori se siano eseguibili in un tempo finito o infinito. Tra le implicazioni più importanti della Macchina di Turing si sottolinea come essa introduca una netta separazione tra la macchina fisica da una parte , e i dati e gli algoritmi astratti dall'altra. Le basi teoriche per lo sviluppo dei moderni calcolatori sono ora mature. L'evoluzione del calcolatore Generazione 1: I tubi a vuoto (valvole)
Nonostante sia più semplice affrontare algoritmicamente calcoli matematici, o geometrici, è possibile affrontare nello stesso modo qualsiasi problema, a patto che se ne possa fornirne una definizione formalmente corretta e non ambigua. Questo esercizio di formalizzazione trascende l'uso del computer e aiuta gli individui ad affrontare i problemi in modo astratto. Va notato che ogni problema può essere affrontato e descritto in molti modi diversi; quindi non esiste un unico algoritmo per la risoluzione di un problema. Questo significa che lo sviluppo di algoritmi è un'attività che richiede, tra le altre cose, creatività e ingegno. A tal proposito, vale la pena citare una famosa battuta di Bill Gates (co-fondatore della Microsoft): " Sceglierò sempre un pigro per fare un lavoro difficile perché troverà il modo più facile per farlo ". Si sottolinea inoltre come l'efficacia e la complessità di un algoritmo dipendano anche dall'organizzazione dei dati a disposizione dell'algoritmo per la risoluzione del problema. Esistono molti modi di organizzare i dati, ognuno dei quali ha pregi e difetti. In genere gli aspetti più rilevanti di cui tenere conto sono:
la quantità di spazio occupato;
la velocità con cui è possibile reperire un determinato dato;
la facilità con cui si possono aggiungere, modificare o eliminare dati.
Infine, un programma può essere definito come un algoritmo scritto in un linguaggio comprensibile al calcolatore, che utilizza dati organizzati secondo una determinata strategia ed è vincolato alle risorse disponibili e alle condizioni al contorno del calcolatore sul quale il programma viene eseguito. Codifica dell'informazione Informazione e codifica L’informazione può essere definita come un insieme di dati espressi mediante una rappresentazione simbolica ed inseriti in un contesto interpretativo. In generale, per rappresentare le informazioni è possibile adottare sistemi di simboli diversi. Ad esempio, come mostrato nella Figura 2.1, le lettere dell’alfabeto, i numeri arabi, i numeri romani o ancora i segnali stradali sono sistemi di simboli comunemente usati per rappresentare e comunicare informazioni. Esiste dunque una corrispondenza arbitraria fra ogni singolo simbolo e l’informazione che esso intende rappresentare. Questa corrispondenza viene chiamata codifica dell’informazione. Un codice è un insieme di simboli e di regole. Queste ultime sono necessarie a definire l’uso e il significato dei simboli. Codificare un’informazione significa determinare una corrispondenza fra i segni di un codice e i dati che costituiscono l’informazione e il suo significato. Di una stessa informazione sono possibili diverse codifiche che usano regole e segni diversi. Ad esempio, in un ristorante si può trovare un cartello con la scritta “vietato fumare” o più semplicemente il simbolo della sigaretta con il divieto. Nonostante l’informazione sia sempre la stessa, ossia che in quel ristorante non si può fumare, per trasmetterla si possono utilizzare codici (cioè simboli) anche molto diversi tra loro. Come costruire un codice Si voglia costruire un codice per comunicare a uno studente il voto conseguito a un esame universitario senza usare la normale numerazione in trentesimi. Le possibili informazioni che il codice deve poter rappresentare sono: “insufficiente”, i voti da diciotto a trenta e il voto “trenta e lode”. Per prima cosa, si deve individuare un insieme di simboli che costituisca il codice, avendo cura di definire un simbolo per ognuna delle informazioni da rappresentare. Ci sarà quindi bisogno di 15 simboli diversi e si dovrà associare ad ogni simbolo la corrispondente informazione, definendo un’opportuna tabella di codifica come nell'esempio della Figura 2.3. Figura 2.3. Esempio di codice per i voti di un esame universitario. In questo modo, dato un voto ( messaggio ), è possibile derivarne una rappresentazione conforme al codice definito (attività di codifica ). Viceversa, dato un messaggio espresso con tale codice, è possibile ricavare il voto corrispondente (attività di decodifica ). Ad esempio, dato il simbolo #, è possibile decodificare il messaggio e affermare che il voto conseguito è 24. E’ importante che a ogni simbolo corrisponda una e una sola informazione, in modo che il messaggio non risulti mai ambiguo. Riduzione del numero di simboli Nell'esempio della Figura 2.3, è stato mostrato un codice che richiedeva 15 simboli per rappresentare altrettante informazioni diverse. Un codice costruito in questo modo è molto semplice e di rapida realizzazione, ma comporta che il numero di simboli che compongono il codice e la tabella di codifica crescano con il numero di informazioni da rappresentare. È facile intuire che la gestione di un codice con un elevato numero di simboli possa essere molto complessa. È possibile costruire un codice che consenta di rappresentare lo stesso numero di informazioni diverse utilizzando un numero inferiore di simboli. Ciò significa ridurre il numero di simboli a disposizione senza tuttavia ridurre il numero di informazioni che possono essere codificate. E' evidente che, avendo meno simboli a disposizione, la rappresentazione di un’informazione richiederà una combinazione di più simboli e quindi una maggiore lunghezza dei messaggi codificati. Con riferimento all'esempio del codice per rappresentare i voti di un esame universitario, si supponga di poter utilizzare soltanto i simboli! £ $ %. Nella Figura 2.4, si mostra un esempio di tabella di codifica basata sui quattro simboli considerati. In questo modo, dato un voto, la lunghezza del messaggio codificato sarà pari a due simboli, il doppio rispetto all'unico simbolo richiesto dal codice della Figura 2.3. Si noti inoltre che sono importanti tanto i simboli quanto la posizione che questi occupano nel messaggio. Infatti il significato di “!$” è ben diverso da “$!”.
Codifica binaria La rappresentazione dell’informazione numerica può adottare varie tecniche. Normalmente si usa la numerazione decimale posizionale, dove una cifra assume un valore dipendente dalla posizione che occupa nel numero. Per esempio, la cifra “2” nel numero 12 vale 2*10^0 (dove 0 è la posizione occupata dal 2 nel numero in esame) e nel numero 2987 vale 2*10^3 (dove 3 è la posizione occupata dal 2 nel numero in esame). Adottando una numerazione in base 10 si hanno 10 cifre con le quali costruire i numeri: 0, 1, 2, 3, 4, 5, 6, 7, 8 e 9. Esistono molti altri tipi di numerazione in cui il numero di cifre è minore a 10, come ad esempio nella numerazione binaria. Questa fu inventata nel XVII secolo da Gottfried Liebniz e si basa sull’utilizzo di soltanto due cifre: 0 e 1. La differenza è che mentre nella numerazione decimale il valore si misura in potenze di 10, nel caso della numerazione binaria il valore si misura in potenze di 2. A parità di valore da scrivere con la numerazione binaria, è necessario impiegare molte più cifre. Questo tipo di numerazione divenne fondamentale con l’avvento dei calcolatori elettronici, poiché le due cifre 0 e 1 sono intuitivamente associabili ai due possibili stati fisici del calcolatore, come ad esempio passaggio/non-passaggio di corrente attraverso un cavo elettrico; polarizzazione/non-polarizzazione di una sostanza magnetizzabile; c arica elettrica positiva/negativa di una sostanza. Per manipolare ed elaborare informazioni (numeri, testo, immagini, audio, video), il calcolatore ha bisogno che queste siano codificate attraverso un codice composto dai soli simboli di 0 e 1. Tale rappresentazione dell’informazione prende il nome di rappresentazione binaria o rappresentazione digitale. Un bit ( binary digit ) rappresenta l’unità minima di informazione, ossia una sola unità informativa che può avere valore 0 o 1. Per poter rappresentare un numero maggiore di informazioni sarà necessario combinare i bit in sequenze. Ad esempio, si supponga di voler fornire una rappresentazione binaria del codice della Figura 2.4. Ogni informazione, cioè ogni possibile voto, deve avere una rappresentazione binaria diversa dalla codifica degli altri voti, come mostrato nella Figura 2.5. Si noti che, poiché il numero di simboli che costituiscono il codice binario è due (0 e 1), la lunghezza di ogni informazione è maggiore rispetto all'esempio della Figura 2.4 in cui si erano usati quattro simboli. All'aumentare del numero di bit di un simbolo, aumenta la quantità di informazioni rappresentabili. Ad esempio, nel caso in cui si voglia rappresentare un numero naturale (intero), il numero di bit determina il valore massimo rappresentabile, mentre nel caso di un numero irrazionale (con virgola), il numero di bit determina implicitamente anche la precisione con cui è possibile rappresentarlo. Nel primo caso sono frequenti le rappresentazioni a 8, 16 e 32 bit, mentre nel secondo caso sono più comuni rappresentazioni a 32 e 64 bit. Unità di misura dell'informazione digitale In informatica, dopo il bit, un'altra unità di misura fondamentale è il byte. Un byte è formato da una sequenza di 8 bit contigui. Un byte può rappresentare 256 informazioni diverse. Questo dipende dal fatto che, avendo 8 bit a disposizione e potendo assumere ogni bit due valori (0 e 1), è possibile definire 2^8 =256 diverse combinazioni di bit. Come per ogni unità di misura, anche il byte possiede multipli che consentono di rappresentare maggiori quantità di informazioni, tuttavia esistono due diverse scale di misura, spesso confuse anche dagli informatici. Errore comune (riscontrabile anche in Windows o MacOS) è infatti usare i nomi del Sistema Internazionale (SI) per riferirsi ai multipli binari, i cui nomi corretti sono stati standardizzati nel 1998 dalla Commissione Elettronica Internazionale (IEC): Multipli del byte Prefissi Binari IEC Prefissi SI Nome Simbolo Multiplo Differenza Nome Simbolo Multiplo byte B 1 B (8 bit) 0 % byte B 1 B (8 bit) kibibyte KiB 210 B (1024 B) 2.4 % kilobyte KB 103 B (1000 B) mebibyte MiB 220 B (1024 KiB) 4.9 % megabyte MB 106 B (1000 KB) gibibyte GiB 230 B (^) MiB)(1024 7.4 % gigabyte GB 109 B (^) MB)( tebibyte TiB 240 B (1024 GiB) 10 % terabyte TB 1012 B (1000 GB) pebibyte PiB 250 B (1024 TiB) 12.6% petabyte PB 1015 B (1000 TB) Ad esempio, se si vogliono memorizzare 5000 numeri, ognuno con una precisione di 16 bit (cioè 2 byte), saranno necessari: 5000*2 = 10000 byte = 9.76 KiB = 10 KB Rappresentazione digitale del testo La codifica binaria può essere utilizzata anche per rappresentare i caratteri alfanumerici, cioè i caratteri alfabetici, i numeri e gli altri simboli usati nella scrittura di testi. A tal fine, è necessario che ogni carattere di scrittura possieda una propria rappresentazione binaria univoca. Si noti che pure segni come le parentesi, le cifre numeriche, gli operatori aritmetici, i segni di punteggiatura e le lettere maiuscole devono avere la propria rappresentazione binaria univoca. I codici attualmente più utilizzati per rappresentare digitalmente i testi sono:
ASCII Esteso : un codice di 8 bit (1 byte)
UNICODE: un codice che può essere usato a 8, 16 o 32 bit (1, 2 o 4 byte) e che codifica i caratteri usati in quasi tutte le
lingue vive e in alcune lingue morte, nonché simboli matematici e chimici, cartografici, l'alfabeto Braille, ideogrammi, ecc. In base al numero di bit usati prende il nome di UTF-8, UTF-16 o UTF-32 (per garantire la compatibilità tra i diversi sistemi, la codifica dell'ASCII Esteso è uguale a quella di UTF-8). Il fatto che un codice “sia di 8 bit” significa che la rappresentazione di un singolo carattere occupa 8 bit (ad esempio, la lettera “a” nella codifica ASCII è rappresentata dal codice 01100001) e che, complessivamente, il codice è in grado di rappresentare fino a 2^8 = caratteri diversi. Questa considerazione è generalizzabile: dato un codice di N bit possiamo dire che ogni carattere di quel codice occupa N bit e che complessivamente il codice può rappresentare fino a 2N^ caratteri diversi. Il primo alfabeto codificato è stato l’alfabeto anglosassone. Questo primo codice venne chiamato ASCII ( American Standard Code for Information Interchange ). In origine l’ASCII era a 7 bit, cioè esistevano 2^7 =128 diverse combinazioni di bit per la rappresentazione dei caratteri. Questo significa che ASCII a 7 bit è in grado di rappresentare fino a 128 caratteri diversi. In questo primo standard (mostrato nella Figura 2.6) non era possibile rappresentare caratteri come le lettere accentate, di uso comune nei paesi di influenza neolatina. A questo primo codice ne fece seguito una sua estensione, detta ASCII esteso. Questa si serve di un
In definitiva, la rappresentazione binaria di un’immagine è costituita da una sequenza di pixel, cioè gruppi di bit che descrivono il colore associato a ciascun punto. Se consideriamo un’immagine di dimensione 640 x 480 espressa secondo lo schema RGB, possiamo calcolare quanti byte saranno necessari per memorizzare tale immagine: 640 x 480 = 307200 pixel, ognuno dei quali richiede 3 byte per rappresentare il colore associato, quindi 307200 x 3 = 921600 byte = 900 KiB. Rappresentazione digitale dei suoni Per i suoni l’unità minima di informazione è rappresentata da un campione di ampiezza, cioè il valore di ampiezza dell'onda sonora in un determinato istante. Gli esempi in Figura 2.7 e 2.8 si riferiscono proprio al suono (questa codifica prende il nome di Pulse Code Modulation, PCM). Un suono può essere descritto come la sensazione causata dall'oscillazione più o meno periodica dell'aria che incide sul timpano dell'ascoltatore. Oscillazioni di diversa ampiezza danno origine alla sensazione di volumi più o meno elevati, mentre il periodo delle oscillazioni incide sulla percezione di suoni gravi o acuti. L'orecchio umano può sentire suoni che oscillano da 20 fino a 20000 volte al secondo (da 20 a 20000 hertz, o Hz). Dunque, per il teorema di Nyquist-Shannon, in genere si campiona il segnale più di 40000 volte al secondo (solitamente 44100 o 48000). Tuttavia, per suoni particolari come la voce, tutte le oscillazioni sopra i 4000 Hz non hanno un particolare contenuto informativo; non è quindi raro vedere codifiche a 8000 campioni al secondo per applicazioni come telefonia o messaggistica vocale. Riguardo alla precisione di ogni campione audio, si è scelto un numero di bit consono a rappresentare la gamma di volumi a cui si è normalmente esposti, dal sussurro fino a rumori forti (ma sotto la soglia del dolore); questo valore è stato fissato a 16 bit. Tuttavia non è raro trovare suoni registrati a 24 bit, in modo da poter sfruttare una precisione maggiore durante le fasi di lavorazione di un prodotto, come può essere un disco musicale. Infine si noti che l'essere umano, in genere, è dotato di due orecchie. Questo gli permette di localizzare la direzione da cui provengono i suoni. Per poter codificare (almeno in parte) questo tipo di informazione, solitamente vengono rappresentati segnali audio stereofonici, cioè composti da due sequenze di campioni, una relativa al canale sinistro ed una al canale destro. Esistono poi codifiche a più canali (come il 5.1, composto da 6 canali indipendenti), che permettono una maggiore precisione spaziale. In definitiva, la rappresentazione binaria di un suono è costituita da una sequenza di campioni, cioè gruppi di bit che descrivono il valore di pressione sonora di ciascun canale. A scopo esemplificativo si può calcolare la memoria necessaria a memorizzare un minuto di musica in qualità CD: 60 secondi x 44100 campioni al secondo x 16 bit per campione x 2 canali = 84672000 bit = 10584000 byte =10336 KiB = 10.1 MiB Rappresentazione digitale dei video Per un video l’unità minima di informazione è rappresentata dal fotogramma, a sua volta composto da pixel. Un video quindi eredita quanto detto relativamente alle immagini, con l'aggiunta però di avere tante immagini quanti sono i fotogrammi di cui è composto, riprodotte ad una velocità sufficientemente alta da fornire, all'occhio umano, l'illusione del movimento. Per via del fenomeno di persistenza delle immagini sulla retina, l'occhio umano fatica a percepire come separate tra loro immagini che si susseguono ad una velocità minima di 10 o 15 fotogrammi al secondo (fps), dunque tale velocità è sufficiente per creare l'impressione del movimento. Tuttavia velocità più elevate consentono di creare un'illusione più realistica, e non è raro trovare codifiche a 25, 30, 50 o 60 fps. Va inoltre considerato che anche in questo caso vale il teorema di Nyquist-Shannon: sarà capitato di vedere video in cui le pale di un elicottero sembrino ferme o girino molto lentamente; questo è il tipico effetto di aliasing temporale che ha luogo quando il movimento da codificare è molto superiore alla velocità con cui si campiona. Materiale registrato a fps più alti (come 120, 240, 300 o addirittura >1000) viene impiegato per la riproduzione in "slow motion" (movimento rallentato), viene cioè riprodotto ad una velocità inferiore per osservare nel dettaglio i movimenti del soggetto del video, altrimenti troppo veloci per essere notati. La tecnica opposta prende invece il nome di "stop motion"; in questo caso i fotogrammi sono registrati a distanza di diversi minuti l'uno dall'altro e poi riprodotti a fps tradizionali, in modo da rendere percepibili movimenti altrimenti troppo lenti per essere notati. Infine si noti che l'essere umano, in genere, è dotato di due occhi, che consentono la cosiddetta visione stereoscopica. Questo permette di valutare la distanza a cui si trovano gli oggetti grazie alle diverse informazioni che ogni occhio riceve. Per poter codificare (almeno in parte) questo tipo di informazione è possibile codificare video stereoscopici , cioè composti da due sequenze di fotogrammi, una relativa all'occhio sinistro ed una all'occhio destro. Queste due sequenze possono essere memorizzate: come aree diverse dello stesso fotogramma; come alternarsi di fotogrammi dell'una e dell'altra sequenza; come sequenze distinte (una successiva all'altra). In definitiva, la rappresentazione binaria di un video è costituita da una sequenza immagini, complete di un'indicazione della velocità a cui vanno riprodotte. A scopo esemplificativo si può calcolare la memoria necessaria a memorizzare un minuto di video in Full-HD a 30 fps: 60 secondi x 30 fps = 1800 immagini, ognuna delle quali con una risoluzione di 1920 colonne x 1080 righe = 2073600 pixel (circa 2 megapixel) 1800 immagini x 2073600 pixel x 24 bit per pixel = 89579520000 bit = 11197440000 byte = 10.43 GiB Elaborazione dei dati multimediali La comodità di codificare il materiale multimediale nei modi descritti in precedenza risiede nel fatto che è possibile applicare modifiche ai dati in maniera molto efficiente sfruttando semplici operazioni matematiche. Consultando la tabella in Figura 2.4, ad esempio, si può notare come la conversione di una lettera maiuscola in una lettera minuscola si può ottenere sommando 32 al numero con cui è codificata. Lo stesso vale per i formati multimediali: se si volesse conferire una tinta rossa ad una foto basterebbe sommare una piccola costante a tutti i byte relativi a quel colore primario, tale da aumentare la quantità totale di rosso che giunge all'occhio. Analogamente, si può simulare l'eco in una registrazione sommando ad ogni campione il campione che lo precede ad una certa distanza. Principali formati multimediali Lo studente più attento si sarà accorto che il numero di bit necessario alla memorizzazione di suoni, immagini e video è decisamente superiore a quanto suggerisce l'esperienza: quasi 1 MiB per una piccola immagine, 10 MiB per un audio di 1 minuto e addirittura 10 GiB per un breve video ad alta qualità. Questa discrepanza trova una giustificazione nel fatto che il modo in cui viene rappresentato nativamente un dato non corrisponde necessariamente al modo in cui viene archiviato in un contenitore. Vi sono infatti 3 modi di memorizzare l'informazione: in modo non compresso , in modo compresso senza perdita di informazioni ( lossless ), e in modo compresso con perdita di informazioni ( lossy ).
I metodi di memorizzazione non compressi comportano un'occupazione di memoria che corrisponde alla memoria necessaria per la rappresentazione originale. A fronte di questo utilizzo smodato di memoria vi è il vantaggio di poter manipolare il materiale multimediale in modo diretto, senza passaggi intermedi necessari a convertire le informazioni in una forma comprensibile al calcolatore. Formati di questo tipo sono ideali per le fasi di lavorazione del bene multimediale. Nella tabella seguente si illustrano i nomi di alcuni formati e contenitori di questo tipo: Esempi di codifiche non compresse Tipo di dati Esempio di^ Codifica^ Esempio di Contenitore Esempio di funzionamento Audio PCM WAV, AIFF Vengono memorizzati tutti i campioni audio nella loro forma originale Immagini Raster/Bitmap RAW, BMP, TIFF Vengono memorizzati tutti i pixel nella loro forma originale Video Raster/Bitmap AVI, MOV Vengono memorizzati tutti i fotogrammi nella loro forma originale Altro (nativa) (nativo) Vengono memorizzati tutti i dati nella loro forma originale I metodi di compressione lossless si basano sull'idea di eliminare ciò che è ridondante, si evita cioè di memorizzare informazioni inutilmente ripetute. Questo comporta un risparmio di memoria che in media si aggira intorno al 50% dell'occupazione originale. Il costo di questo risparmio si riflette nella necessità di reintrodurre la ridondanza (decompressione) per poter elaborare le informazioni (fosse anche solo per visualizzare l'immagine su schermo o sentire il suono). Va comunque notato che la decompressione di un file lossless dà origine alle stesse informazioni di partenza, senza che sia scartato alcun dettaglio. Formati di questo tipo sono quindi l'ideale per l'archiviazione o la trasmissione di dati nella forma più conservativa, senza che però sia sprecata memoria. Nella tabella seguente si illustrano i nomi di alcuni formati e contenitori di questo tipo: Esempi di codifiche lossless Tipo di dati Esempio di Codifica Esempio di Contenitore Esempio di funzionamento Audio FLAC, ALAC, DST, ALS FLAC, MP4 Se un campione è ripetuto, viene memorizzato solo una volta con l'indicazione di quante volte va ripetuto Immagini RLE, LZW TIFF, PNG Se un pixel è ripetuto, viene memorizzato solo una volta con l'indicazione di quante volte va ripetuto Video HuffYUV, Animation AVI Viene memorizzata solo la porzione di fotogramma diversa dal fotogramma precedente Altro Huffman ZIP, RAR Si modifica la codifica in modo che i simboli più ripetuti abbiano un codice più corto Infine, i metodi di compressione lossy si basano sull'idea di eliminare ciò che è irrilevante, si evita cioè di memorizzare informazioni non percepibili dall'utente. Viene quindi persa in modo definitivo tutta quell'informazione che in media non viene percepita. Questo comporta un oggettivo degrado dell'informazione, con la potenziale introduzione di artefatti e distorsioni non presenti nel dato originale. Il risparmio che ne deriva può arrivare fino al 90% dell'occupazione originale. Oltre all'oggettiva perdita di informazioni, il costo è che la decompressone in genere è più onerosa per il calcolatore in termini di potenza di calcolo richiesta. Inoltre, sebbene la decompressione sia sempre necessaria per la fruizione del dato originale, è caldamente sconsigliata la manipolazione dei dati e la successiva ricompressione lossy, in quanto si affronterebbe una nuova perdita di informazioni, con l'introduzione di sempre più distorsioni e artefatti. Formati di questo tipo sono ideali per la fruizione in streaming da parte dell'utente finale. Nella tabella seguente si illustrano i nomi di alcuni formati e contenitori di questo tipo, mentre in Figura 2.10 si può vedere un esempio di immagine che ha subito diverse ri- codifiche (decompressione e ricompressione) in formato JPEG. Esempi di codifiche lossy Tipo di dati Esempio di^ Codifica^ Esempio di Contenitore Esempio di funzionamento Audio Mpeg, AAC, ADPCM, GSM, AMR, WMA^ MP3, AC3, OGG, WMA Se una porzione di segnale è sotto la soglia di udibilità viene scartata Immagini JPEG, GIF TIFF, JPG Si riduce la quantità di colori disponibili (GIF) o si eliminano i dettagli impercettibili (JPG) Video DV, H264, Divx, 3GPP, WMV, Mpeg^ AVI, MP4, MOV, MKV^ Ogni immagine viene divisa in blocchetti e si memorizzano le coordinate dello spostamento di ogni blocco Altro - - Non conoscendo la tipologia di dati non è possibile sapere cosa si può scartare Figura 2.10: A sinistra l'immagine originale, a destra la stessa immagine dopo diversi cicli di salvataggio in JPG. La comparsa di difetti visibili si verifica ad esempio quando si salva sul proprio computer un'immagine e poi la si condivide sui social network, che solitamente ricomprimono le immagini. Struttura del calcolatore: Anatomia di un calcolatore Grazie al lavoro intellettuale di Alan Turing, è possibile modellare il funzionamento di un calcolatore come l’interazione tra componenti fisiche hardware e programmi software. Il termine hardware , letteralmente “ferraglia”, designa la parte fisica della macchina, composta da tutte le componenti materiali che ne consentono il funzionamento sulla base dei principi dell’elettronica. Ogni componente svolge una sua funzione di base:
fisica quantistica (come l' effetto tunnel ), sono ad accesso casuale, molto più veloci di tutte le altre tipologie di memorie secondarie e permettono una notevole riduzione dei consumi (dovuta all'assenza di parti meccaniche). Negli ultimi anni si sta assistendo all'introduzione di supporti chiamati SSD (Solid State Drive) utilizzati come sostituti dei vecchi hard disk: questi nuovi dischi sono ancora molto costosi e non riescono a raggiungere la capacità di memorizzazione dei vecchi hard disk, ma garantiscono enormi incrementi della velocità di lettura e scrittura oltre che consumi ed emissioni sonore estremamente ridotte. Le periferiche Oltre alla CPU e alla memoria primaria e secondaria, il calcolatore ha bisogno di dispositivi di input e output chiamati periferiche per supportare l'interazione con l’ambiente esterno. Le periferiche si collegano al calcolatore mediante interfacce di comunicazione (comunemente dette porte), e possono variare a seconda del tipo e della velocità di trasmissione. Inoltre, per ogni tipo di periferica esiste una scheda chiamata controller che viene connessa alla scheda madre e che ha il compito di gestire il comportamento della periferica. I dispositivi di input consentono di comunicare al calcolatore informazioni provenienti dall'utente o dall'ambiente esterno. I principali dispositivi di input (Figura 3.3) sono: la tastiera, gli strumenti di puntamento (mouse), lo scanner, il microfono, le macchine fotografiche e le videocamere digitali. La tastiera è il dispositivo di input principale ed è comunemente affiancata dagli strumenti di puntamento. Oltre al popolarissimo mouse, un esempio di strumento di puntamento è il touchpad, molto diffuso sui calcolatori portatili e con funzionalità analoghe a quelle del mouse. In particolare, il touchpad è costituito da un’area sensibile al movimento e alla pressione delle dita che è collegata con il puntatore sullo schermo. Lo scanner è una periferica che si collega alla macchina, spesso usando una porta che è detta USB (Universal Serial Bus), che permette di rappresentare digitalmente una sorgente cartacea (una fotografia o un documento scritto). Microfoni, macchine fotografiche e videocamere digitali sono dispositivi analoghi a quelli tradizionalmente conosciuti, con la differenza che sono in grado di comunicare al calcolatore una versione digitale del suono, delle fotografie e dei video realizzati. Figura 3.3. Esempi di periferiche di input. I dispositivi di output consentono al calcolatore di comunicare all'esterno informazioni in esso contenute. I principali dispositivi di output (Figura 3.4) sono: lo schermo, la stampante e le casse per la riproduzione del suono. Figura 3.4. Esempi di periferiche di output. E’ importante notare che nella maggior parte dei casi il collegamento al calcolatore di una periferica richiede, oltre al collegamento dei cavi alla porta adeguata, l’installazione di uno specifico software chiamato driver che ha il compito di gestire il flusso di dati diretto al e proveniente dal dispositivo, facendo in modo che la periferica funzioni correttamente. Esso rappresenta in pratica il vocabolario contenente il "linguaggio" di comunicazione della periferica. Oltre a quelle menzionate, esistono altre tipologie di periferiche. Tra le più comuni è possibile citare la scheda di rete, che permette di collegare un calcolatore ad altri calcolatori tramite una rete locale o la rete Internet, e il modem, che consente di far comunicare due calcolatori tramite la rete telefonica. Si tratta di due esempi di periferiche che sono simultaneamente di input e di output. Programmi e software: Il ruolo del software Se l'hardware è la componente materiale di un calcolatore, il software ne costituisce la componente immateriale. Il termine software (letteralmente "materia morbida") è l'insieme dei programmi che possono essere eseguiti da un calcolatore. In particolare, un singolo programma software è un insieme di istruzioni che un calcolatore, e più precisamente la CPU, deve eseguire per portare a compimento un certo compito ( task ). Microsoft Word è un esempio di programma software che contiene istruzioni per la creazione e la gestione di documenti. Nel contesto di Word, il pulsante che consente di formattare in grassetto un testo selezionato è una funzione software associata a un insieme di istruzioni che consentono di raggiungere l’obiettivo (cioè visualizzare in grassetto una data porzione di testo). Firefox o Chrome sono invece esempi di programmi software che si propongono come strumenti per reperire e visualizzare pagine web. E’ facile pensare a numerosi altri esempi di programmi software, ciascuno con le proprie caratteristiche e finalità. Ne risulta che esistono diverse tipologie di programmi software di cui è opportuno conoscere le specificità. Tipologie di software E’ consuetudine suddividere il software in due macro-categorie: il software di sistema e il software applicativo. Il software di sistema è l’insieme dei programmi che gestiscono le risorse e il comportamento del calcolatore. In questa categoria, il software più importante è il sistema operativo , un insieme di programmi che controlla e gestisce le funzionalità legate a CPU, memoria, periferiche e dispositivi di input/output collegati al calcolatore. Nel software di sistema sono inclusi i firmware e i driver. Il firmware è un software integrato in un dispositivo elettronico per svolgere funzioni specifiche, come l’avvio del dispositivo stesso. Un esempio di firmware è il BIOS ( Basic Input-Output System ) che è un firmware integrato sulla scheda madre del calcolatore con il compito di eseguire la procedura di avvio all'accensione della macchina. Il driver è un software che affianca uno specifico dispositivo e ne consente il corretto funzionamento. Il driver è normalmente installato all'interno del sistema operativo e consente al calcolatore di utilizzare il dispositivo. Ogni dispositivo possiede il proprio driver, e il driver è composto da un insieme di procedure che controllano le varie funzionalità del dispositivo. Ad esempio, una stampante, come ogni dispositivo collegabile a un calcolatore, è dotata del proprio driver, la cui installazione è necessaria affinché il calcolatore possa correttamente farne uso. Il software applicativo comprende tutti i programmi che consentono all'utente di eseguire compiti specifici. Sono esempi di software applicativo i programmi per la creazione e la gestione di documenti (es. Microsoft Word), i fogli di calcolo (es. Microsoft Excel), i browser per la navigazione su web (es. Mozilla Firefox), i programmi per la gestione della posta elettronica (es. Microsoft Outlook), i programmi per l’elaborazione delle immagini (es. Adobe Photoshop) e così via. Il sistema operativo Il sistema operativo (SO) è il software di sistema più importante per il corretto funzionamento di un calcolatore e presiede numerose funzionalità. Da un lato, il sistema operativo si occupa di gestire le componenti fisiche del calcolatore. In particolare, sono di sua competenza funzioni come:
la gestione della CPU e della memoria principale (RAM). In ogni istante, il calcolatore esegue numerosi programmi. Per
questo motivo, il sistema operativo deve stabilire come e in quale ordine questi programmi avranno accesso alla CPU, allocando inoltre lo spazio in memoria principale per ciascuno di essi;
la gestione dei file e la memorizzazione sui dispositivi di memoria secondaria. Il sistema operativo è dotato di un modulo
denominato file system per la gestione dei file. Questo modulo presiede le operazioni di salvataggio/memorizzazione dei file e
le corrispondenti operazioni di lettura/caricamento dei medesimi. Il file system utilizza un’organizzazione dei file in cartelle ( directory ) per favorire una gestione ordinata e intuitiva dello spazio disponibile da parte dell’utente;
l’interazione con le periferiche. Tramite i driver, il sistema operativo è in grado di comunicare con i dispositivi collegati al
calcolatore consentendone il corretto funzionamento. Inoltre, il sistema operativo si occupa di gestire l’interazione fra l’utente e il calcolatore. In particolare, è compito del sistema operativo intercettare i comandi dell’utente e fare in modo che essi siano correttamente eseguiti orchestrando il funzionamento delle varie componenti del calcolatore che si rendessero necessarie. A tal fine, il sistema operativo è dotato di un’interfaccia, normalmente visuale, che consente all'utente di comunicare in maniera intuitiva e naturale con il calcolatore. Questa interfaccia è chiamata GUI ( Graphical User Interface ) e utilizza strumenti come finestre, pulsanti e puntatori per fornire all'utente gli strumenti necessari per invocare l’esecuzione dei comandi. Ad esempio, tramite gli strumenti di input come la tastiera e il mouse, l’utente può invocare la stampa di un documento. Il sistema operativo intercetta il comando e fa in modo che il documento richiesto sia passato alla stampante. Tramite il driver della stampante, il sistema operativo manda in stampa il documento e produce l’output richiesto. Quale sistema operativo? Il sistema operativo è lo stesso per tutti i calcolatori? La risposta è no: esistono sistemi operativi diversi, ognuno con le proprie caratteristiche e peculiarità. I sistemi operativi più diffusi e conosciuti sono Microsoft Windows , Linux, Apple Mac OS X e Android. Windows è un prodotto della società statunitense Microsoft e prende il nome dall'elemento che ne caratterizza l’interfaccia grafica: la finestra (window). Nel corso degli anni, le versioni di Microsoft Windows che sono andate succedendosi sono piuttosto numerose: Windows 95, 98, 2000, XP, Vista, 7, 8 e 10, solo per citarne alcune. Si tratta di un SO disponibile per numerose piattaforme , cioè installabile su calcolatori con diverse tipologie di microprocessore e scheda madre. Microsoft Windows è un SO commerciale , è dunque necessario pagare l’acquisto di una licenza per poterlo installare su un calcolatore. Linux è un SO non commerciale e può essere installato su un calcolatore senza dover pagare alcuna licenza. La prima versione nasce nel 1991 a opera di Linus Torvalds, un giovane studente da cui il sistema ereditò il nome. Si tratta di un SO estremamente versatile (ispirato ad un importante sistema dell'epoca chiamato UNIX) e, come Microsoft Windows, installabile su numerose piattaforme. Oggi questo SO è disponibile in svariate distribuzioni. Le diverse distribuzioni Linux condividono l’uso del medesimo nucleo ( kernel ) del sistema e si differenziano nei restanti moduli. Ne risulta che le varie distribuzioni possono presentare differenze anche sostanziali per l’utente. Sono esempi di distribuzioni Ubuntu , Fedora e SuSE. Mac OS X è un prodotto della società statunitense Apple ed è concepito per essere installato solo ed esclusivamente sui dispositivi di questo stesso produttore (PC o dispositivi mobili). Come Microsoft Windows, anche Mac OS X è un prodotto commerciale ed è necessario pagare una licenza per installarlo su un calcolatore; come Linux, anche questo SO è ispirato al SO UNIX. Android è un sistema operativo non commerciale sviluppato da Alphabet (azienda nota anche col nome Google) basato su Linux, ma ottimizzato per i dispositivi mobili (smartphone, tablet ecc). E’ possibile scegliere il sistema operativo da installare sul proprio calcolatore? In genere, all'acquisto del calcolatore, il sistema operativo è già installato (e l’eventuale licenza d’uso già pagata in caso di prodotto commerciale). Installare un nuovo sistema operativo può implicare l’acquisto di un’ulteriore licenza d’uso nel caso si scelga un prodotto commerciale come Microsoft Windows. Certamente, la scelta di installare un sistema operativo non commerciale come Linux è sempre possibile e non comporta alcun aggravio di costi. Programmi applicativi I software applicativi si affiancano al software di sistema e completano la dotazione di programmi di un calcolatore. Il software applicativo comprende innumerevoli programmi, ognuno concepito per realizzare specifiche funzionalità di interesse per l'utente finale. Il software applicativo non è pre-installato sul calcolatore: l'utente sceglie quali software applicativi sono di suo interesse e procede con l'installazione. La scelta può richiedere una riflessione: a volte la medesima funzionalità è offerta da più software applicativi e si pone il dubbio di come procedere. In generale, i software applicativi non sono in conflitto fra loro e possono coesistere sul calcolatore senza recarsi reciproco danno. Esistono eccezioni a questa regola generale, come ad esempio il caso dei software antivirus per i quali è raccomandato l'uso di un unico prodotto alla volta. Fatta eccezione per questi casi, i software applicativi, anche quando analoghi per funzionalità, possono essere installati e usati contemporaneamente sul calcolatore. Si pensi al caso dei browser, i software applicativi per la navigazione su web. Esistono numerosi prodotti che offrono questa funzionalità come ad esempio i noti Chrome e Firefox. Entrambi possono essere installati sul calcolatore e possono essere usati contemporaneamente senza alcun problema. Dunque, come scegliere quali software applicativi installare sul proprio calcolatore? Un fattore di scelta è certamente il costo. Numerosi software sono prodotti commerciali ed è necessario pagare il costo di una licenza per poterli installare e utilizzare. Spesso questi software possono essere installati in versione di prova (trial version) che ha una durata limitata nel tempo (tipicamente 30 giorni) oppure offre funzionalità limitate rispetto alla versione ufficiale. Esistono anche software cosiddetti freeware per i quali non è necessario pagare una licenza e possono essere liberamente installati sul calcolatore. Una ulteriore categoria è quella del software open source , programmi di cui è reso disponibile pubblicamente il codice sorgente scritto in linguaggi di alto livello in nome della trasparenza e della possibilità da parte di chiunque di contribuire allo sviluppo. L'installazione richiede l'esecuzione di una procedura di configurazione. Tale procedura installa il programma sul calcolatore e lo rende disponibile per tutte le successive esecuzioni. L'installazione comporta l'occupazione di una porzione di spazio sulla memoria secondaria del calcolatore (disco fisso). Fatta eccezione per lo spazio occupato su memoria secondaria, il software applicativo utilizza (e consuma) risorse del calcolatore solo quando è in esecuzione. Il software applicativo interagisce con il software di sistema e in particolare con il sistema operativo per l'accesso e l'utilizzo delle risorse del calcolatore, come ad esempio la memoria principale e quella secondaria. Pertanto il software applicativo è costruito per funzionare con uno specifico sistema operativo. Il software applicativo è distribuito in diverse versioni, una per ogni sistema operativo su cui può essere installato. Si pensi al caso di Mozilla Firefox che è disponibile per sistema operativo Windows, Linux, Mac OS X e Android. Tuttavia, si tenga presente che numerosi software sono concepiti e distribuiti per funzionare solo con uno specifico sistema operativo e non è possibile utilizzarli su altri sistemi. Si pensi al caso di Microsoft Access, un software applicativo della suite di Microsoft Office che è disponibile solo per sistema operativo Windows. File system e gestione delle memorie di massa Dopo che un testo, un'immagine o qualsiasi altro dato è stato creato, acquisito mediante conversione analogico-digitale, o modificato, è necessario memorizzarlo in maniera persistente nella memoria di massa. Questo in genere viene fatto memorizzando i dati ( contenuto ) in un file (dall'inglese"schedario", il contenitore ). Un file non è altro che una zona di memoria non volatile localizzata mediante un file system , ovvero un modo usato dal SO per suddividere ed organizzare una memoria di massa.
umano), dall'altro perchè la complessità comporta una certa difficoltà di manutenzione, e dipendere da qualcosa che non si sa riparare è un rischio notevole, che trasforma la tecnologia in una vulnerabilità. Un ulteriore rischio è quello del sovraccarico cognitivo (o information overload ). Fenomeno che di per sé è sempre esistito, ma che ha avuto un grande impatto con l'avvento dell'informatica e di Internet. Si tratta di un disturbo che si manifesta quando si ricevono troppe informazioni, rendendo impossibile prendere decisioni o riuscire a concentrarsi su una singola informazione. Nel contesto dell'informatica, si parla di information overload in due circostanze: nel piccolo può essere causato da interfacce grafiche o siti web mal progettati, che inibiscono la capacità di discernere ciò che è importante da ciò che non lo è per via della mole di dati e del modo in cui le informazioni sono presentate. Esiste però anche una dimensione patologica del fenomeno, condizione in cui l'utente passa il tempo navigando compulsivamente da un sito all'altro o scorrendo la pagina di un social network, cercando informazioni sempre più complete o aggiornate, non riuscendo a fermarsi o a ricordarne alcuna, provando un iniziale ed effimero senso di piacere alla comparsa di nuove informazioni, che però lascia subito il posto al bisogno di ulteriori aggiornamenti, ricerca che viene percepita come un dovere o una necessità. La società odierna è plasmata dall'informazione e dalle tecnologie informatiche, attraverso un'influenza reciproca tra ciò che accade nel mondo reale e ciò che accade online. Questo estende il concetto di cittadinanza : la definizione di diritti e doveri deve tenere il passo con le possibilità offerte dalla tecnologia. Si tratta di un lavoro di aggiornamento legislativo e culturale tutt'altro che semplice, in cui non è sempre possibile applicare paradigmi tradizionali, e dove l'informatica stessa propone nuovi paradigmi (come ad esempio la radicalizzazione del principio di trasparenza e libero accesso ai dati che, insieme ai modelli di sviluppo partecipativi, è uno degli aspetti caratterizzanti la cultura Open Source e l'etica hacker). In sintesi, il calcolatore (in ogni sua forma) ha davvero una funzione strategica, e per questo l'infrastruttura va difesa, ma senza che vengano minate la libertà e la privacy dei singoli (ad esempio a seguito dell'introduzione di politiche di priorità di alcuni dati rispetto ad altri, che comprometterebbero la neutralità della rete senza che sussista alcuna ragione tecnica). A loro volta, però, gli utenti hanno responsabilità legate alla sicurezza del sistema e alla diffusione delle informazioni. Questa lezione è dedicata ai problemi di sicurezza informatica (ossia come difendere l'infrastruttura) e alle insidie sociali che sfruttano il mezzo informatico. Perchè la privacy è importante? Quella corrente è definita da alcuni come l'epoca del capitalismo cognitivo , dove ciò che ha valore sono le idee e i beni immateriali (come i dati) più che i prodotti materiali. In questo contesto vale la pena chiedersi cosa si possa celare dietro ad un servizio gratuito come un social network, un servizio di messaggistica o un motore di ricerca. Per i servizi di questo tipo, caratterizzati dalla possibilità di caricare contenuti propri (dati personali e non), i dati stessi costituiscono la forma di pagamento per il servizio ricevuto. Nella maggior parte dei casi, infatti, chi offre il servizio monetizza il suo investimento attraverso la profilazione dell'utente (sotto l'esplicito consenso dell'utente stesso, fornito al momento della registrazione). Per profilazione si intende la raccolta di informazioni al fine di suddividere l'utenza in categorie di comportamento. I fornitori di servizi possono fare un triplice uso dei dati in loro possesso, e ognuno di questi usi nasconde potenziali insidie:
Utilizzo dei dati per la scelta di contenuti personalizzati: il fornitore di servizi (attraverso opportuni algoritmi) può
presentare all'utente contenuti conformi a quelli che sono i suoi interessi e le sue opinioni analizzando la cronologia delle ricerche, le condivisioni sui social network o ciò che scrive nei servizi di messaggistica. Per quanto apparentemente utile, questo può portare all'involontario offuscamento di contenuti contrari al suo sentire, creando di fatto una bolla nella quale tutto sembra confermare il suo punto di vista, allontanandolo da una corretta percezione della realtà.
Vendita a terze parti di servizi basati sui dati di un utente: un fornitore di servizi può vendere a terze parti spazi
pubblicitari personalizzati, dedicati cioè ad una specifica categoria di utenti. Sebbene possa fare piacere non vedere pubblicità completamente casuali, le preferenze di un utente permettono di evincere quale sia la sua personalità. Inserzionisti malevoli interessati alla manipolazione dell'opinione pubblica potrebbero confezionare contenuti e pubblicità adatti a cambiare la percezione di un tema politico o sociale.
Vendita dei dati a terze parti: i dati raccolti da un fornitore di servizi possono infine essere venduti a terze parti per scopi di
indagine, ad esempio per progettare nuovi prodotti in linea con i desideri dei possibili acquirenti. Tuttavia una volta che i dati sono in possesso di altri non è sempre facile capire l'uso che ne sarà fatto. Emblematico è il caso di Cambridge Analitica , che sfruttando la raccolta illegale di dati di milioni di utenti ha estratto il profilo psicologico di tutti coloro fossero indecisi riguardo alle preferenze di voto, ed in seguito, mediante pubblicità mirate (si veda il punto precedente), ha influenzato l'opinione pubblica cambiando le sorti di almeno due importanti votazioni del biennio 2016-2017, ingerendo così sugli equilibri geopolitici degli anni successivi. In risposta a questo tipo di pericoli, la Comunità Europea ha proposto la direttiva GDPR (Regolamento generale sulla protezione dei dati), che impone a chi ospita i dati degli utenti di esplicitare in sede di registrazione l'uso che ne verrà fatto, e di fornire gli strumenti per poterli interrogare ed eventualmente cancellare. Va infine sottolineato che ogni tipo di azione svolta online (visitare un sito web, mandare un messaggio, cercare qualcosa, ecc) lascia sempre tracce, sia sul proprio dispositivo sia in rete. Casi di utilizzi malevoli di queste tracce non sono rari, e per difendersi (almeno in parte) da questo tipo di pericoli si possono adottare soluzioni basate su:
l' anonimizzazione, ossia l'offuscamento della propria identità attraverso strumenti specifici (sebbene sia un comportamento
malvisto da alcuni fornitori di servizi, perchè il motivo dell'anonimizzazione potrebbe essere anche criminoso);
modelli comportamentali , ossia adottare comportamenti intrinsecamente sicuri, come ad esempio considerare di pubblico
dominio qualsiasi cosa si faccia con un calcolatore (fosse anche solo salvare una foto sul telefono, scrivere una mail personale o ricevere un messaggio privato) o compiere azioni casuali per inquinare i dati relativi al proprio comportamento;
implementazioni normative, ossia leggi più severe che regolamentino la memorizzazione dei dati (sebbene scrivere queste
leggi non sia affatto semplice, soprattutto alla luce del fatto che sono spesso i governi stessi a compiere azioni di massivo monitoraggio della rete, sfruttando le zone grigie della legislazione). Manipolazione sociale e fake news Quello della manipolazione dell'opinione pubblica attraverso internet è un tema molto importante, tanto da essere oggetto di studio da parte della NATO. Unitamente al resto delle infrastrutture tecnologiche nel loro insieme, è considerato dagli eserciti nazionali alla stregua di un vero e proprio campo di battaglia (insieme a terra, mare, aria e spazio). Le operazioni tattiche svolte in questo dominio vengono perpetrate (da forze armate, governi, o semplici privati) attraverso un monitoraggio estensivo della rete e la diffusione di: notizie falsificate ( fake news ); notizie reali presentate in modo tendenzioso; condivisione di contenuti originali da parte di account fasulli ( fake account ). Il tutto confezionato ad arte per manipolare l'opinione pubblica. Un esempio lampante riguarda le violenze nel Myanmar del 2016, in cui è stata documentata un'attività di propaganda basata su fake news e utilizzo di fake account, diffusa attraverso i social network da parte dell'esercito di regime, che ha portato ad atti di violenza ai
danni della minoranza musulmana Rohingya, tanto da essere classificata come genocidio dal Commissariato delle Nazioni Unite per i Diritti Umani. A complicare la situazione si consideri poi che, oltre a quello ideologico, ci può essere un secondo movente per la diffusione di fake news: quello economico. Alcuni social network infatti permettono all'utente di guadagnare denaro attraverso la pubblicità mostrata contestualmente alla fruizione di un suo contenuto. Alcuni soggetti sfruttano questo meccanismo di monetizzazione creando contenuti estremamente virali per massimizzarne la diffusione, e quindi il guadagno. Una delle caratteristiche che può rendere virale un contenuto è proprio la sua capacità di polarizzare l'opinione pubblica, facendo leva su temi controversi e divisivi. Spesso fake news indistinguibili da quelle confezionate per fini ideologici rientrano in questa categoria. Un esempio che spicca per creatività riguarda un'agenzia che diffondeva fake news riguardanti i temi più disparati, e al tempo stesso gestiva un sito di debunking (demistificazione) che smontava tutte le false notizie, garantendosi così un gran volume di condivisioni, sia da parte di chi credeva alle fake news, sia da parte di chi condivideva le smentite. In questo caso il movente era economico, ma il danno ideologico è stato ingente, perchè ha screditato l'importante operato di altri debunker , onesti e appassionati. Esistono infine fornitori di servizi illegali a cui spesso si appoggiano i soggetti interessati alla diffusione di contenuti malevoli (sia per fini economici che ideologici) chiamati click farm. Queste realtà forniscono in genere due tipi di prodotto: click e fake account. Nel primo caso si tratta di centinaia di agenti (fisici e/o virtuali) che passano il tempo cliccando e visualizzando i contenuti del cliente per aumentarne artificialmente il numero di interazioni con il pubblico, in modo da ingannare gli algoritmi preposti al riconoscimento dell'interesse generale di un contenuto ed aumentarne la diffusione. Nel secondo caso vengono venduti account di social network confezionati su misura per impersonificare una specifica tipologia di persona, utilizzati come vettore per influenzare l'opinione pubblica riguardo a temi specifici con commenti e provocazioni ( troll ). Questi account sono confezionati così bene da sembrare reali: hanno una storia, foto, e una fitta rete di amici. Spesso vengono creati partendo dal furto di credenziali di un vero account, motivo per cui chiunque può essere una potenziale vittima del furto di credenziali. Come forma di difesa dai fake account, molti social network stanno impiegando algoritmi in grado di riconoscere i comportamenti inautentici, ma non si tratta di un compito facile: sebbene vengano cancellati migliaia di account ogni giorno, molti riescono a superare le maglie di sicurezza. Difendersi dalle fake news Ogni volta che si vede una notizia condivisa da qualcuno bisognerebbe chiedersi se sia genuina o meno, abituarsi ad essere scettici :
non ci si deve fermare al titolo, ma va letto l'intero articolo;
si deve valutare la credibilità della fonte. Chi ha condiviso l'informazione? E' un esperto in materia?
si deve valutare la qualità della notizia. Quali sono le prove? E' bene verificare l'autenticità di eventuali fotografie (ad esempio
con la ricerca tramite immagini di Google);
ci sono riferimenti o link a fonti ufficiali? Cosa dicono fonti diverse da quella condivisa?
Inoltre ci possono essere anche indizi nel modo in cui l'informazione è presentata che suggeriscono scarsa attendibilità:
uso di click-bait (esche per i click): si tratta di tecniche usate nel giornalismo meno professionale per spingere gli utenti a
cliccare su un titolo; tra queste si citano: toni sensazionalistici, domande nel titolo, presenza di elenchi (es. "10 cose che la scienza non dice!");
grande mole di pubblicità (che spesso rende difficile anche la fruizione del contenuto);
errori grossolani nel testo e anomalie tipografiche;
gli articoli sono privi di data, non sono firmati e non citano alcuna fonte ufficiale.
Tuttavia, se la fake news è ben confezionata, o se testate giornalistiche affidabili hanno creduto alla notizia e l'hanno ridistribuita, questi segni potrebbero essere stati eliminati, a quel punto il fact checking (cioè il lavoro di accertamento degli avvenimenti citati e dei dati usati in un testo o in un discorso) è l'unico modo per capire se una news è genuina. Esistono diversi blog e pagine di social network che si occupano di debunking e fact checking, alcune delle quali riportano elenchi di pagine web associate alla insistente diffusione di fake news. Come raccomandazione generale, è bene non diffondere notizie qualora si abbiano dubbi sulla veridicità del contenuto. Truffe e altri rischi simili Nella sfera personale, quando non si ha una grande dimestichezza con la fenomenologia del linguaggio testuale e visuale di internet, i rischi che si incontrano più di frequente sono: le insistenti pubblicità non richieste ( Spam ), i tentativi di truffa perpetrati per via telematica ( Scam ), e i tentativi di furto di credenziali per mezzo di false comunicazioni ufficiali ( Phishing ). Quasi tutti i sistemi di messaggistica e di posta elettronica oggi incorporano algoritmi anti-spam/scam/phishing, tuttavia alcune minacce a volte riescono a superare questi controlli automatici, è quindi bene imparare a riconoscerle. Elementi che possono suggerire la scarsa attendibilità di un messaggio sono:
il mittente è sconosciuto o (in caso di mittente noto) il contenuto è atipico per quel mittente;
il messaggio fa leva su presunte vincite, risparmi, fatture, spedizioni, personaggi facoltosi o attraenti e qualsiasi altro tipo di
esca che stimoli la curiosità;
si riscontrano errori grossolani nel testo e anomalie tipografiche;
i collegamenti presenti nel messaggio non portano dove dovrebbero (link sui quali è bene non cliccare mai);
sono presenti allegati sospetti e non richiesti.
Figura 5.1: Quando fermiamo il puntatore su un link senza cliccare, solitamente nella parte bassa dello schermo vediamo l'indirizzo della pagina di destinazione Introduzione alla sicurezza informatica
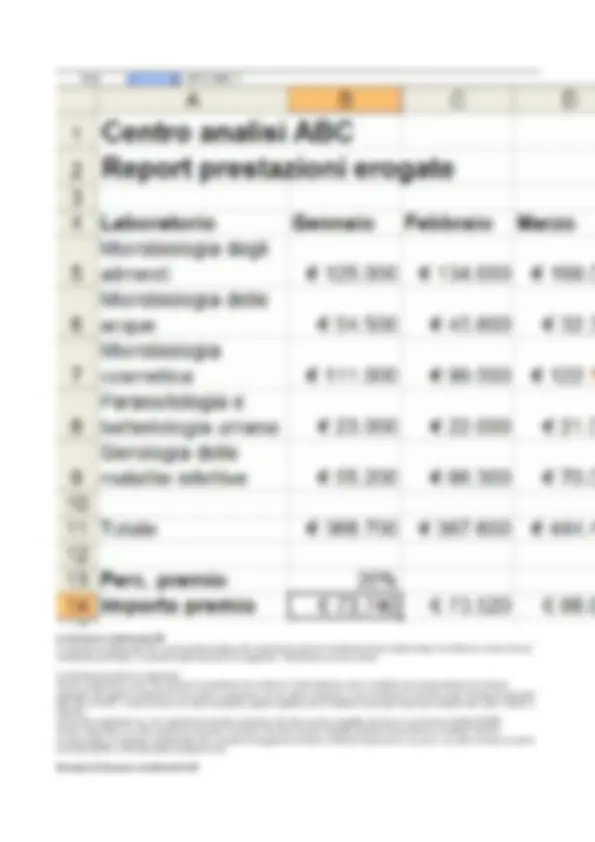
Nelle prossime pagine, si presenteranno i principali aspetti che caratterizzano i fogli di calcolo e, dove necessario, si farà riferimento allo strumento Microsoft Excel (in seguito denominato semplicemente Excel) per illustrare nozioni e esempi. Tuttavia, si precisa che tali contenuti sono facilmente applicabili a tutti i principali fogli di calcolo oggi disponibili. Organizzazione di un foglio di calcolo Un foglio di calcolo si presenta come una griglia di celle, ciascuna risultante dall’intersezione di una riga e una colonna. Convenzionalmente, le colonne e le righe di un foglio di calcolo sono identificate rispettivamente da un indice progressivo alfabetico (A, B, …) e da uno numerico (1, 2, …). Ne consegue che ogni cella possiede coordinate univoche rappresentate dalla combinazione degli indici di colonna e riga che la determinano. Ad esempio, nella Figura 1.1 è rappresentata una porzione di foglio di calcolo in cui è stata selezionata la cella B4. In un foglio di calcolo, esiste sempre almeno una cella selezionata che indica la posizione corrente. La cella selezionata è evidenziata mediante una bordatura più marcata rispetto a quella delle altre celle. Inoltre, essa è dotata di un quadratino sporgente nell’angolo in basso a destra chiamato maniglia di riempimento che, come spiegato in seguito, consente di accedere a particolari funzionalità legate al riempimento automatico di celle e al trascinamento di formule. Nell’esempio della Figura 1.1, è possibile notare la maniglia di riempimento della cella selezionata. Sopra alla griglia delle celle, il foglio di calcolo mostra la barra della formula ( fx ), che visualizza il contenuto della cella correntemente selezionata. Nell’esempio della Figura 1.1, la barra della formula è vuota dal momento che la cella B4 selezionata non ha alcun contenuto. Inserimento di dati Una cella di un foglio di calcolo può ospitare tre diverse tipologie di contenuto: valori testuali , cioè una sequenza di caratteri alfanumerici (anche denominata stringa di testo ); valori numerici , cioè una sequenza di cifre; formule , cioè espressioni di calcolo che consentono di eseguire operazioni riferendosi (in generale) al contenuto di altre celle. Una formula può essere composta manualmente utilizzando i consueti operatori aritmetici di somma (+), sottrazione (-), prodotto (*), divisione (/) ed elevamento a potenza (^). A questi, si aggiunge la possibilità di costruire una formula utilizzando, anche in modo combinato, le funzioni predefinite che il foglio di calcolo mette a disposizione per eseguire calcoli complessi. Una formula ha sempre inizio con il simbolo di uguaglianza (=), al quale segue l’espressione della formula da calcolare. Una volta completato l’inserimento della formula (ad esempio premendo il tasto Invio sulla tastiera o un apposito pulsante nell'interfaccia), la cella mostra il risultato calcolato mediante l’espressione inserita. Selezionando una cella che contiene una formula, l’espressione corrispondente è visualizzata nella barra della formula. Un esempio di inserimento di dati in un foglio di calcolo è mostrato nella Figura 1.2 dove:
le celle A1, A2 e A4 contengono stringhe di testo;
le celle B1 e B2 presentano valori numerici;
la cella B4 contiene una formula.
In particolare, si noti che la cella B4 visualizza il risultato della somma delle celle B1 e B2. Essendo la cella selezionata, l’espressione aritmetica calcolata in B4 è mostrata nella barra della formula sopra la griglia di celle. Riempimento automatico di celle Talvolta, i dati di un foglio di calcolo appartengono a un elenco predefinito e possono richiedere una lunga attività di inserimento. In questi casi, è possibile utilizzare una funzionalità chiamata riempimento automatico di celle che consente di inserire automaticamente gli elementi relativi alle serie di dati predefinite. Sono disponibili serie di dati testuali, come i mesi dell’anno o i giorni della settimana, e numeriche, come le progressioni aritmetiche di ragione impostata dall’utente. La funzionalità di riempimento automatico di celle è accessibile tramite la maniglia di riempimento. Ad esempio, si supponga di voler inserire in un foglio di calcolo il resoconto giornaliero delle prestazioni erogate da un laboratorio di analisi nell’arco di un anno solare. Come mostrato nella Figura 1.3, è possibile disporre i nomi dei dodici mesi dell’anno sulla prima riga del foglio di calcolo (celle da B1 a M1) e numerare progressivamente le righe del foglio (celle da A2 a A32) per denotare i giorni, in modo tale da avere una cella per ogni giorno dell’anno in cui inserire gli importi relativi alle prestazioni erogate (celle da B2 a M32). La funzionalità di riempimento automatico di celle agevola la predisposizione di questo foglio di calcolo, inserendo automaticamente sia l’elenco dei mesi sia i numeri relativi ai giorni. Per l’inserimento dei mesi, è necessario inserire il primo elemento dell’elenco (Gennaio) nella cella B1. Selezionando la cella B1 e posizionando il mouse sulla maniglia di riempimento, si attiva la funzionalità di riempimento automatico trascinando il mouse nella direzione in cui si vogliono inserire gli altri mesi (nell'esempio di Figura 1.3, si tratta di trascinamento orizzontale), come mostrato sotto: Analogamente, è possibile inserire i numeri da 1 a 31 per denotare i giorni. Si tratta di una progressione aritmetica di ragione 1 (questo significa che la differenza fra due elementi consecutivi della progressione è costante e uguale a 1). È necessario inserire i primi due elementi della progressione (la cifra 1 in A2 e la cifra 2 in A3). Selezionando le due celle A2 e A3 e utilizzando la maniglia di riempimento è possibile completare la progressione trascinando il mouse nella direzione opportuna (nell'esempio di Figura 1.3, si tratta di trascinamento verticale), come mostrato sotto. Si noti che nel caso di giorni della settimana o di mesi dell'anno è sufficiente evidenziare una cella, mentre nel caso di valori numerici ne vanno selezionate (almeno) due, il che consente al programma di calcolare la ragione della progressione. Tale caratteristica e può essere sfruttata per replicare i valori di una cella o per creare progressioni di natura differente. Ad esempio, se l'operazione venisse invocata su una singola cella contenente il valore 0 , questo verrebbe replicato su tutte le celle
consecutive, così come se il contenuto fosse il valore 1 , il carattere a o la stringa pippo. Se invece le celle oggetto di selezione e trascinamento fossero due e contenessero i valori 1 e 3 , il programma riempirebbe le celle successive con 5 , 7 , ecc. Va sottolineato che questo comportamento è tipico dei valori numerici: se i valori fossero invece a e b , il programma, anziché portare avanti la sequenza alfabetica con c , d , ecc., applicherebbe il criterio di replicazione, compilando le celle successive con a , b , a , b , e via dicendo. Dimensionamento di righe e colonne Inizialmente, le colonne e le righe di un foglio di calcolo sono impostate alla medesima dimensione, creando l’effetto di una griglia omogenea di celle tra loro identiche. La larghezza di ogni colonna e l’altezza di ogni riga, possono essere modificate in base al contenuto da ospitare. È possibile modificare la larghezza di una colonna o l'altezza di una riga utilizzando il dispositivo di puntamento (mouse), come mostrato nell'esempio della Figura 1.4 per la colonna A. Se questa operazione viene compiuta avendo evidenziato più colonne o più righe, il dimensionamento viene applicato a tutti gli elementi della selezione. In alternativa, mediante le opzioni di formato, è possibile impostare il valore numerico esatto di larghezza di ciascuna colonna (in Excel, tramite il comando di menù Formato > Colonna > Larghezza). Allo stesso modo, è possibile modificare l’altezza di una riga del foglio di calcolo. Alcuni programmi, tra cui Excel, implementano un altro metodo efficace per dimensionare le celle. Un doppio clic sul bordo di separazione tra colonne (o righe) nell'intestazione, come mostrato in Figura 1.4, dimensiona in maniera ottimizzata, sulla base del contenuto dell'intera colonna (riga), la sua larghezza (altezza). Il bordo su cui cliccare è quello che separa la colonna (riga) da dimensionare da quella successiva. È bene notare che la griglia di un foglio di calcolo deve sempre possedere una struttura regolare, quindi non è possibile modificare la dimensione in larghezza o altezza di una singola cella. Nell’esempio della Figura 1.2, la larghezza della colonna A e l’altezza delle righe 1 e 2 sono state incrementate per ottenere una migliore disposizione del testo nelle celle A1 e A2. Formattazione di celle I fogli di calcolo mettono a disposizione numerose funzionalità di formattazione delle celle e del loro contenuto. Tali funzionalità possono essere suddivise nelle seguenti categorie:
Numero. Le funzionalità di questa categoria consentono di personalizzare la visualizzazione dei valori numerici contenuti
nelle celle. Ad esempio, si può indicare che il valore numerico contenuto in una cella esprime una percentuale, facendo in modo che il simbolo percentuale (%) sia visualizzato a fianco del numero. Analogamente, sono disponibili opportuni formati per personalizzare la visualizzazione dei numeri che esprimono valute, date/orari, frazioni e numeri esponenziali.
Allineamento. Riguarda la disposizione del contenuto di una cella. Ad esempio, è possibile specificare l’allineamento
orizzontale (sinistra, centro, destra, giustificato) e verticale (in alto, al centro, in basso). È anche possibile indicare l’orientamento della cella (orizzontale, verticale, diagonale secondo una specifica angolazione). Infine, esiste un’opzione per fare in modo che il contenuto di una cella possa essere disposto su righe diverse qualora superi la larghezza della cella.
Carattere. Si tratta di funzionalità analoghe a quelle offerte dai programmi di videoscrittura come Microsoft Word e
OpenOffice Writer per la formattazione del testo. Esempi di questa categoria sono la selezione di tipo, colore e dimensione del font e l’impostazione di stili come il testo grassetto, corsivo e sottolineato.
Bordo. Le funzionalità di questa categoria consentono di personalizzare la bordatura della cella. Ad esempio, è possibile
specificare il colore e lo spessore del bordo anche per singoli lati della cella.
Motivo. Contiene funzionalità relative alla colorazione dello sfondo delle celle.
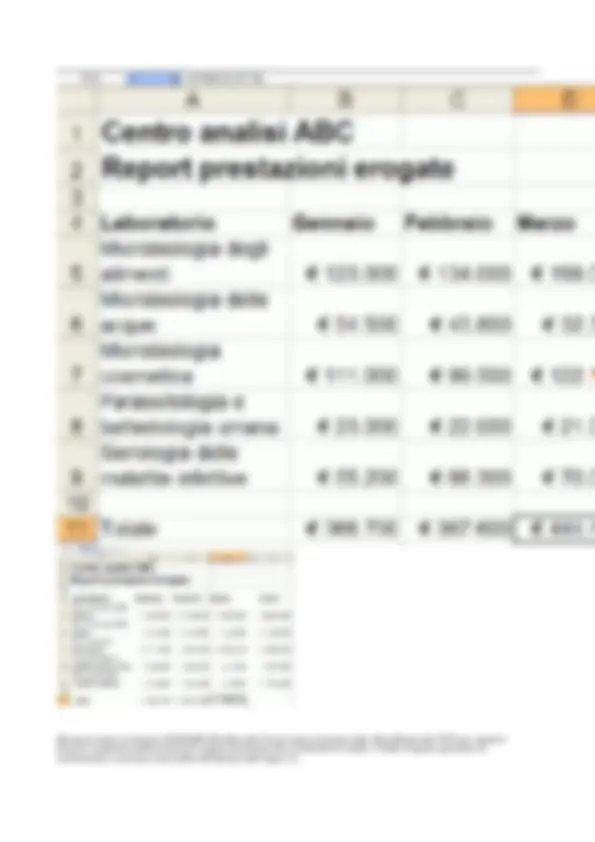
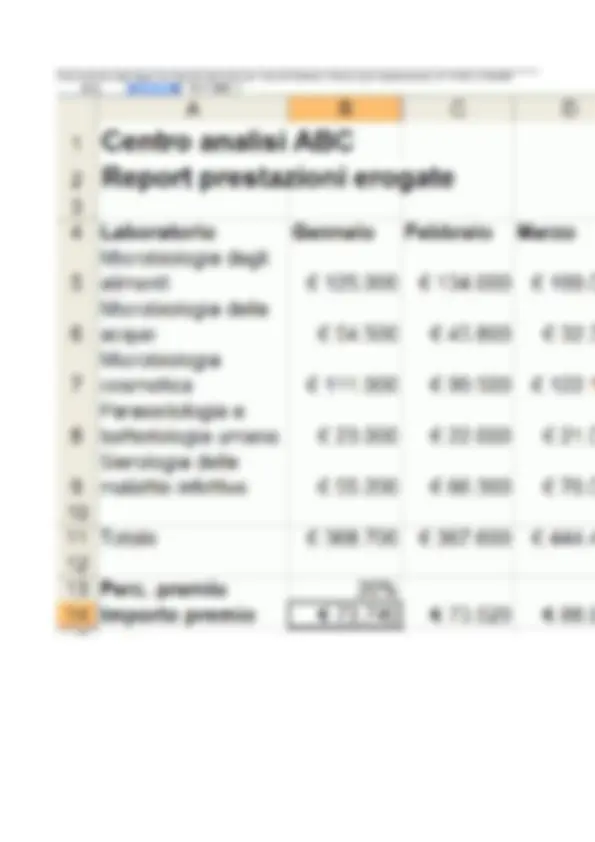
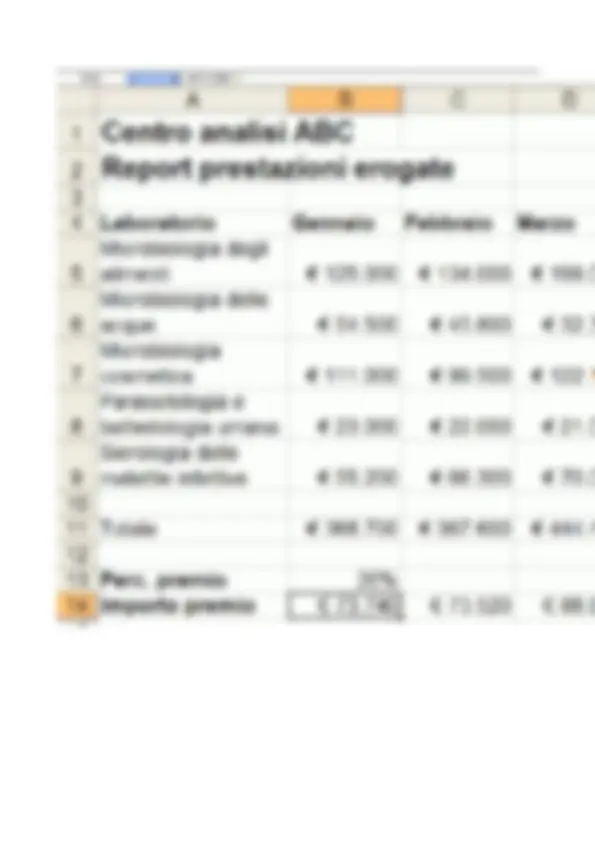
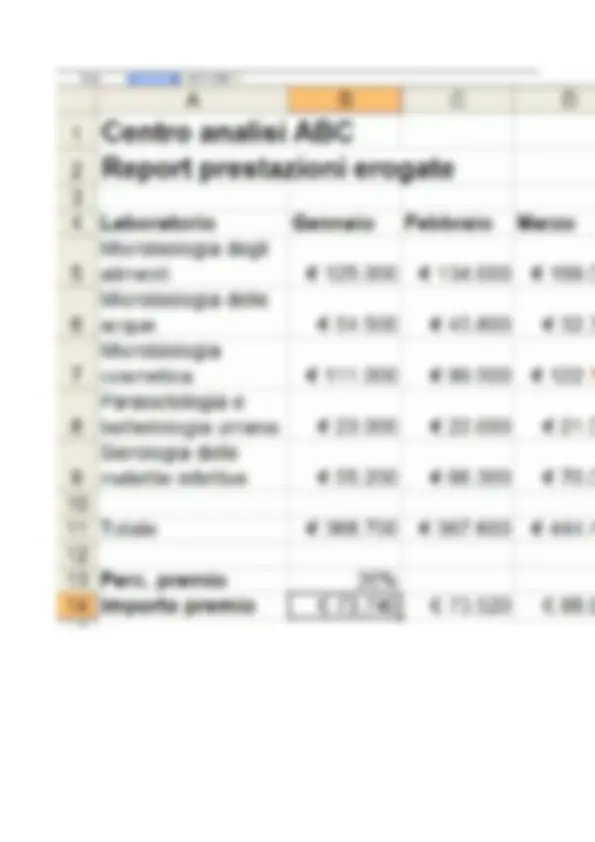
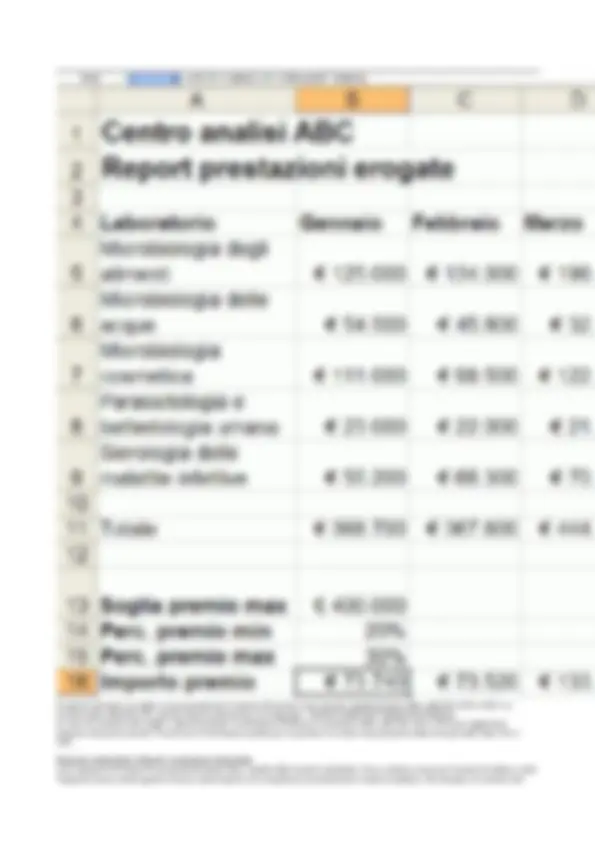
Nell’esempio della Figura 1.2, si noti la disposizione su due righe del testo contenuto nelle celle A1 e A2 ottenuta mediante la corrispondente opzione di formato allineamento. Inoltre, si noti che le celle B1, B2, B4 sono state impostate al formato numerico di valuta. Questo comporta la visualizzazione del simbolo della divisa Euro (€) e del separatore delle migliaia accanto ai valori numerici contenuti nelle celle. Esempio di foglio di calcolo Consideriamo il foglio di calcolo riportato nella Figura 1.5, che sarà utilizzato come esempio di riferimento nelle prossime unità di contenuto. Il foglio mostra un report trimestrale con gli importi complessivi delle prestazioni mediche erogate da un ipotetico laboratorio di analisi. In questo esempio, sono state applicate varie opzioni di formattazione. In particolare, è stata aumentata la dimensione del font del testo (righe 1 e 2), è stato applicato lo stile grassetto (celle A1, A2, A4, B4, C4 e D4) ed è stata modificata la larghezza delle colonne (colonna A) e l’altezza delle righe (righe 5, 6, 7, 8, 9). Inoltre, è stato impostato il formato valuta per le celle che contengono gli importi delle prestazioni (celle nell’intervallo B5:D9). A seconda della lunghezza del testo inserito, può capitare che il contenuto di una cella occupi visivamente lo spazio delle celle attigue. Nell’esempio di Figura 1.5, questo avviene per le celle A1 e A2, che occupano rispettivamente parzialmente lo spazio della cella B1 e delle celle B2 e C2. In questi casi, si ricordi che, nonostante la visualizzazione possa trarre in inganno, il testo è interamente contenuto nelle celle A1 e A2 mentre le celle B1, B2 e C2 sono vuote.
Allo stesso modo, la funzione SOMMA(B5:D5) della cella F5 può essere trascinata nelle celle dell’intervallo F6:F9 per calcolare l’importo complessivo delle prestazione erogate nel trimestre dai vari laboratori di analisi. L’effetto di questa operazione di trascinamento è anch'esso osservabile nell’esempio della Figura 2.1.
Aggiornamento dei risultati di formule e funzioni Una caratteristica fondamentale dei fogli di calcolo è l’aggiornamento automatico dei risultati di formule e funzioni quando il contenuto di una cella riferita subisce una modifica. Questo significa che ogni volta che il contenuto di una cella viene cambiato, le formule e le funzioni presenti all’interno del foglio di calcolo che lavorano su quella cella vengono automaticamente ricalcolate per aggiornare il risultato. Nell'esempio in Figura 1.5, si supponga di modificare l’importo delle prestazioni erogate dal laboratorio di microbiologia degli alimenti nel mese di gennaio (cella B5). In particolare, si sostituisca l’importo esistente (€ 123.000) con un nuovo importo pari a € 125.000. Automaticamente, le somme calcolate nelle celle B11 e F5 sono aggiornate dal foglio di calcolo e sono impostate al nuovo valore di € 368.700 e € 458.000, rispettivamente. I risultati delle altre operazioni di somma rimangono invece invariati, dal momento che la cella B modificata non rientra negli intervalli di celle considerati dalle formule nelle celle C11:D11 e F6:F9. Il risultato di questa operazione di aggiornamento è mostrato nella Figura 2.2. Riferimenti relativi e assoluti Negli esempi mostrati in precedenza, sono state utilizzate formule e funzioni contenenti riferimenti relativi alle celle. Questo consente di fare in modo che, in caso di trascinamento della formula o della funzione, i riferimenti siano automaticamente traslati. Tale comportamento può non essere auspicabile quando, trascinando una formula, si vuole mantenere fisso il riferimento a una o più celle. In questi casi, è necessario utilizzare nella formula o funzione un riferimento assoluto alle celle per fare in modo che, durante l’operazione di trascinamento, tale riferimento resti invariato e non subisca traslazione. Un riferimento assoluto è creato anteponendo il carattere $ alla coordinata della cella che deve restare fissa durante l’operazione di trascinamento. Nell'inserire le coordinate di una cella, è possibile combinare l’uso di riferimenti relativi e assoluti. Si supponga di voler inserire in una formula o funzione il riferimento alla cella B5. Esistono quattro possibilità:
inserire il riferimento B5. Il riferimento è completamente relativo, dunque sia il riferimento alla colonna sia quello alla riga
scorrono in caso di trascinamento;
inserire il riferimento $B5. Il riferimento alla colonna è assoluto ($B) e resta fisso, il riferimento alla riga è relativo (5) e scorre
in caso di trascinamento;
inserire il riferimento B$5. Il riferimento alla colonna è relativo (B) e scorre, il riferimento alla riga è assoluto ($5) e resta fisso
in caso di trascinamento;
inserire il riferimento $B$5. Il riferimento è completamente assoluto, dunque sia il riferimento alla colonna sia quello alla riga
restano fissi in caso di trascinamento. Esempio con riferimenti relativi e assoluti Si consideri l’esempio in Figura 1.5. Si supponga che, in base a una disposizione interna, il centro di analisi riceva ogni mese un premio pari a una percentuale fissata rispetto all'importo complessivo delle prestazioni erogate in quel mese da parte di tutti i laboratori. Come mostrato nella Figura 2.3, si inserisce nella cella B13 la percentuale da utilizzare per il calcolo del premio mensile, e nella cella B14 la formula per calcolare l’importo effettivo del premio. La formula della cella B14 è la seguente: = B11 * $B$ Calcolando la formula, l’importo del premio per il mese di Gennaio risulta pari a € 73.740. Per calcolare l’importo del premio per i mesi di Febbraio e Marzo va trascinata la formula della cella B14 rispettivamente nelle celle C14 e D14. Nella formula inserita, i riferimenti alla cella $B$13 sono assoluti. In questo caso, l’uso dei riferimenti assoluti è necessario poiché trascinando la formula in C14 e D14 si desidera che i riferimenti alla cella $B$13 restino fissi e non siano traslati. Al contrario, i riferimenti alla cella B11 sono relativi perché si vuole che siano traslati e che vadano a considerare gli importi complessivi delle prestazioni per i mesi di Febbraio e Marzo (celle C11 e D11, rispettivamente).