Scarica Informatica Documentale Teoria + Esercizi e più Esercizi in PDF di Fondamenti di informatica solo su Docsity!
INFORMATICA DOCUMENTALE
prof. Beatrice D’Amico
2023-2024 BASI DI DATI – VI EDIZIONE Atzeni – Ceri – Fraternali – Paraboschi - Torlone
CAPITOLO 1: INTRODUZIONE
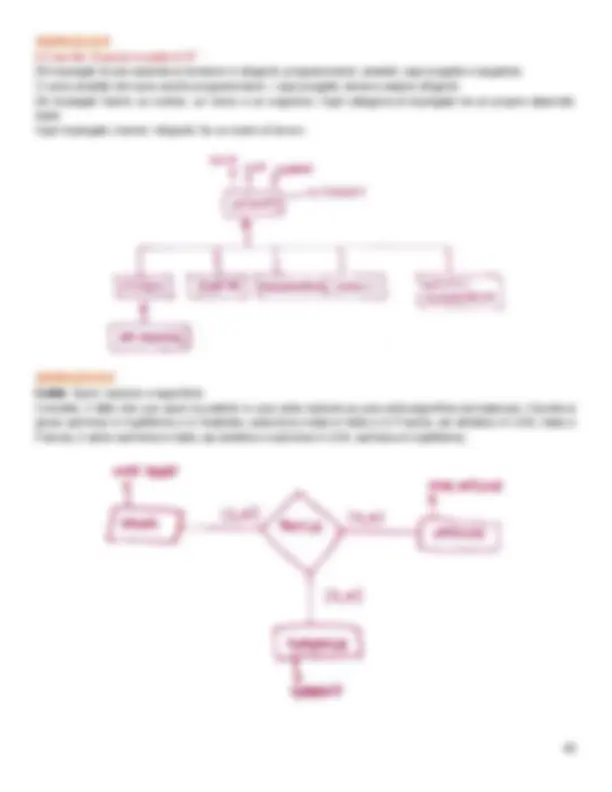
1.1| Sistemi informativi, informazioni e dati Ogni organizzazione è dotata di un sistema informativo, che organizza e gestisce le informazioni necessarie per perseguire gli scopi dell’organizzazione stessa. Per indicare, invece, la porzione automatizzata del sistema informativo viene utilizzato il termine sistema informatico. Nei sistemi informatici, le informazioni vengono rappresentate per mezzo di dati, che hanno bisogno di essere interpretati per fornire informazioni. È difficile spiegare la differenza tra dato e informazione: in modo approssimativo possiamo dire che i dati da soli non hanno significato, ma, una volta interpretati e correlati opportunamente, essi forniscono informazioni, che consentono di arricchire la nostra conoscenza.
Informazione : notizia, dato o elemento che consente di avere conoscenza più o meni esatta di fatti, situazioni, modi di essere; Dato : ciò che è immediatamente presente alla conoscenza, prima di ogni elaborazione; o In informatica: elementi di informazione costituiti da simboli che devono essere elaborati. Base di dati : è una collezione di dati, utilizzati per rappresentare le informazioni di interesse per un sistema informativo.
1.2| Basi di dati e sistemi di gestione di basi di dati In assenza di software dedicati alla gestione dei dati, quest’ultima è affidata ai linguaggi di programmazione tradizionali (C, Fortran, C++, Java…). L’approccio “convenzionale” alla gestione dei dati sfrutta la presenza di archivi o file per memorizzare dati in modo persistente nella memoria di massa. Un file permette di memorizzare e ricercare dati, ma fornisce solo semplici meccanismi di accesso e condivisione. Le basi di dati sono state concepite per gestire in modo integrato e flessibile le informazioni di interesse per diversi soggetti, limitando i rischi di ridondanza e incoerenza. In generale, una base di dati è una collezione di dati.
Un sistema di gestione di base di dati (DBMS) è un sistema software in grado di gestire collezioni di dati che siano grandi, condivise e persistenti, assicurando la loro affidabilità (capacità del sistema di conservare intatto il contenuto della base di dati – funzionalità di salvataggio e ripristino) e privatezza. Deve essere efficiente ed efficace. Una base di dati è una collezione di dati gestita da un DBMS.
Quindi, le caratteristiche di un DBMS sono:
- Grandezza : la quantità di dati che oggi abbiamo a disposizione è enorme. Parliamo di milioni di gigabyte che contengono decine di migliaia di record. I DBMS devono essere in grado di gestirla. Per gestirla hanno a disposizione architetture complesse e articolate che prevedano la gestione dei dati senza porre limiti alla dimensione.
- Condivisione : utenti e applicazioni diverse devono poter accedere ai dati in comune. Si evita in questo modo la ridondanza (si evitano le ripetizioni) e conseguentemente si riduce il rischio di inconsistenze. Se esistono molteplici copie dello stesso dato può essere che non siano esattamente uguali. Se ogni dato è memorizzato nel sistema in modo univoco non è possibile incorrere in disallineamenti.
- Persistenza : hanno un tempo di vita che esula dall’applicazione che li utilizza, o dal contesto entro cui sono utilizzati.
- Affidabilità : i DBMS garantiscono l’affidabilità, ossia la capacità del sistema di conservare intatto il contenuto del dato in caso di mal funzionamento del software. È una caratteristica estremamente importante. A questo scopo i DBMS forniscono specifiche funzionalità di salvataggio e ripristino.
- Privatezza : la gestione delle autorizzazioni permette di controllare l’accesso ai dati; quindi, chi vi accede e cosa può fare con questi dati.
- Efficienza : i DBMS sono in grado di svolgere operazioni utilizzando un insieme di risorse che sia accettabile per gli utenti. A patto che il sistema informatico su cui è ospitato il DBMS sia adeguato in termini di spazio, i DBMS sono in grado di ottimizzare il tempo e lo spazio per ogni operazione sui dati che l’utente potrebbe voler compiere.
- Efficacia : i DBMS a seconda del contesto in cui sono inseriti, sono in grado di offrire una buona efficacia complessiva del sistema. Sono in grado di rendere produttive le attività dei loro utenti. I file sono stati introdotti per gestire insieme di dati “localmente” a una specifica procedura o applicazione. I DBMS, a loro volta, utilizzano file per la memorizzazione dei dati.
1.3| Modelli di dati Un modello di dati è un insieme di concetti utilizzati per organizzare i dati di interesse e descriverne la struttura in modo che essa risulti comprensibile a un elaboratore. Ogni modello di dati fornisce meccanismi di strutturazione, che permettono di definire nuovi tipi sulla base di tipi predefiniti e costruttori di tipo. Il modello relazionale dei dati, tuttora il più diffuso e didatticamente più interessante, permette di definire tipi per mezzo del costruttore relazione, che permette di organizzare dati in insiemi di record a struttura fissa. Una relazione viene spesso rappresentata con delle tabelle, le cui righe rappresentano specifici record e le colonne corrispondono ai campi del record; l’ordine di righe e colonne è irrilevante.
Oltre al modello relazionale, esistono: Il modello gerarchico , basato sull’uso di strutture ad albero, e quindi gerarchie; Il modello reticolare , basato sull’uso di grafi; Il modello a oggetti , evoluzione del modello relazionale che utilizza il paradigma di programmazione a oggetti; Il modello XML, rivisitazione del modello gerarchico;
Modelli semi-strutturati e flessibili , sviluppati nel contesto dei NoSQL, che cercano di superare alcune limitazioni del relazionale.
Questi modelli vengono definiti logici , per sottolineare il fatto che le strutture utilizzate da questi modelli riflettono una particolare organizzazione. Più recentemente, sono stati introdotti i modelli concettuali, utilizzati per descrivere i dati in maniera indipendente dal modello logico. Questi modelli tendono a descrivere i concetti del mondo reale, e sono utilizzati in una fase preliminare del processo di progettazione di basi di dati.
CAPITOLO 2: IL MODELLO RELAZIONALE
2.1| Il modello relazionale: strutture 2.1.1| Modelli logici nei sistemi di basi di dati Il modello relazionale si basa sui concetti di relazione e tabella. Questo modello risponde al requisito dell’indipendenza dei dati che, come già visto, prevede una distinzione tra il livello fisico e quello logico: gli utenti che accedono ai dati e i programmatori che sviluppano le applicazioni fanno riferimento al livello logico; i dati descritti a questo livello sono poi organizzati per mezzo di strutture fisiche.
Il termine relazione può avere 3 accezioni diverse:
- relazione matematica → teoria degli insiemi;
- relazione secondo la definizione del modello relazionale;
- traduzione di relationship, costruito del modello Entità-Relazione, usato per descrivere legami tra entità.
2.1.2| Relazioni e tabelle Le relazioni sono necessariamente finite, dato che le basi di dati vanno memorizzate in sistemi di calcolo di dimensione finita.
Dati n>0 insiemi D1, D2, …, Dn e il loro prodotto cartesiano (D1 X D2 X … X Dn)
- il numero n delle componenti viene detto grado del prodotto cartesiano e della relazione;
- il numero di elementi (n-upla) della relazione viene chiamato cardinalità della relazione.
2.1.3| Relazioni con attributi Una relazione matematica è un insieme di n-uple, quindi:
- non vi è alcun ordinamento fra le n-uple;
- le n-uple sono distinte l’una dall’altra
Allo stesso tempo, ciascuna n-upla è ordinata al proprio interno: l’i-esimo valore di ciascuna proviene dall’i-esimo dominio. È quindi definito un ordinamento fra domini.
2.1.4| Relazioni e basi di dati
La base di dati in figura mostra una delle caratteristiche fondamentali del modello relazionale, ovvero l’essere “basato su valori”: i riferimenti fra dati in relazioni diverse sono rappresentati per mezzo di valori che compaiono nelle tuple. Altri modelli logici utilizzano puntatori e vengono definiti “basati su record e puntatori”.
Un modello basato sui valori presenta dei vantaggi:
- richiede di rappresentare solo ciò che è rilevante, i puntatori sono qualcosa di aggiuntivo;
- il modello relazionale permette l’indipendenza fisica dei dati;
- è semplice trasferire i dati da un contesto a un altro, perché tutta l’informazione è contenuta nei valori.
Quindi: uno schema di relazione è costituito da un sim\2 Qbolo R, detto nome della relazione, e da un insieme di attributi X = {A1, A2,…,An} il tutto di solito indicato con R(X). A ciascun attributo è associato un dominio.
Uno schema di base di dati è un insieme di schemi di relazione con nomi diversi: R= {R1(X1), R2(X2),…, RN(XN)}
I nomi delle relazioni hanno la funzione di distinguere le varie relazioni nella base di dati.
Un’istanza di relazione su uno schema R(X) è un insieme r di tuple su X Un’istanza di base di dati su uno schema R= {R1(X1), R2(X2),…, RN(XN)} è un insieme di relazioni r= {r1, r2,…, rn} dove ogni ri è una relazione sullo schema Ri(Xi)
Lo schema della figura sopra è rappresentabile così:
R = {Studenti(Matricola, Cognome, Nome, Data di nascita) Esami (Studente, Voto, Corso) Corsi (Codice, Titolo, Docente)
2.1.5| Informazione incompleta e valori nulli Per rappresentare la non disponibilità di valori, il concetto di relazione viene esteso prevedendo che una tupla possa assumere, su ciascun attributo, o un valore del dominio, oppure un valore speciale, detto valore nullo, che denota appunto l’assenza di informazione.
Prendendo come esempio la tabella a fianco, possiamo notare che i tre valori nulli presenti in essa abbiano motivazioni diverse (i capoluoghi di provincia hanno sempre una prefettura).
- Firenze è capoluogo, ma non conosciamo l’indirizzo della prefettura; il valore nullo sostituisce un valore non noto → valore sconosciuto.
- Tivoli non è mai stata capoluogo, perciò non ha una prefettura. Quindi l’attributo IndirizzoPrefettura non può avere un valore; il valore nullo denota l’inapplicabilità o l’inesistenza del valore → valore inesistente.
- Olbia-Tempio è abolita dal 2016, e non sappiamo se la prefettura sia mai stata istituita, né sappiamo il suo indirizzo. Non sappiamo se il valore esista. Il valore è inesistente oppure sconosciuto → senza informazione.
In genere, nelle relazioni, è possibile specificare che i nulli siano ammessi solo su alcuni attributi e non su altri.
Una chiave è un insieme di attributi utilizzato per identificare univocamente le tuple in una relazione.
Un insieme K di attributi è superchiave di una relazione r se r non contiene due tuple distinte t1 e t2 con t1[K] = t2[K]; K è la chiave di r se è una superchiave minimale di r (cioè non esiste un'altra superchiave K’ di r che sia contenuta in K come sottoinsieme proprio).
Nell’esempio: {Matricola} è superchiave minimale (perché contiene un solo attributo). È una chiave candidata. {Cognome, Nome, Nascita} è un superchiave minimale. È una chiave candidata. {Matricola, Corso} è superchiave, ma non è minimale (perché Matricola da sola basterebbe). Quindi {Matricola, Corso} non è la chiave. {Nome, Corso} non è superchiave, perché le ultime due tuple sono uguali.
2.2.3| Chiavi e valori nulli
- la prima tupla ha valori nulli su Matricola e Nascita → non è identificabile;
- la terza su Nascita e Corso;
- la quarta su Matricola.
L’esempio ci suggerisce la necessità di porre dei limiti alla presenza di valori nulli nelle chiavi delle relazioni. Si adotta una soluzione semplice: su una delle chiavi ( chiave primaria ) si vietano i valori nulli.
La maggior parte dei riferimenti tra relazioni viene fatta tramite le chiavi primarie. Gli attributi che costituiscono la chiave primaria e vengono evidenziati attraverso la sottolineatura (Matricola).
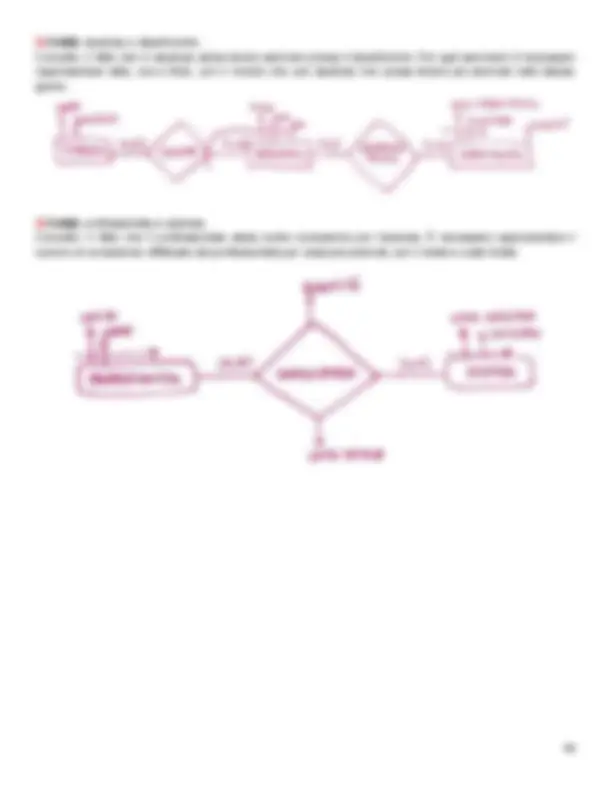
2.2.4| Vincoli di integrità referenziale Un vincolo di integrità referenziale tra un insieme di attributi X={A1, …, Ap} di R1 e un insieme di attributi K={K1, …, Kp} è soddisfatto se per ogni istanza r1 di R1 e per ogni istanza r2 di R2 vale la seguente condizione: ∀𝑡 ∈ 𝑟!: ∃ 𝑠 ∈ 𝑟" ∶ ∀𝑖 ∈ 1,…, 𝑝 : 𝑡 𝐴! = 𝑠[𝐾i]
In altre parole, un vincolo di integrità referenziale (“foreign key”) fra gli attributi X di una relazione R1 e un’altra relazione R2 impone ai valori su X in R1 di comparire come valori della chiave primaria di R2.
Vincoli di integrità presenti:
- tra la relazione Agenti e l’attributo agente della relazione Infrazioni ;
- tra gli attributi Stato e Numero di Infrazioni e la relazione Auto.
Un vincolo di integrità referenziale viene indicato inquadrando gli attributi soggetti al vincolo e collegando con una freccia il riquadro alla relazione (tabella) da cui la chiave proviene.
Esempio: supposto che esista un vincolo di integrità referenziale sull’attributo NumTreno della tabella FERMATA rispetto alla tabella TRENO, la notazione per indicare tale vincolo è la seguente:
CAPITOLO 3: ALGEBRA E CALCOLO RELAZIONALE
Nelle basi di dati ci sono due funzioni fondamentali:
- aggiornamento : funzione che, data un’istanza di base di dati, produce un’altra istanza di base di dati, sullo stesso schema;
- interrogazione : funzione che, data un’istanza di base di dati, produce una relazione, su un dato schema.
L’algebra relazionale è un linguaggio procedurale (le operazioni complesse vengono specificate descrivendo il procedimento da seguire per ottenere la soluzione). Il calcolo relazionale è, invece, un linguaggio dichiarativo, in cui le espressioni descrivono le proprietà del risultato, piuttosto che la procedura per ottenerlo.
3.1| Algebra relazionale È un linguaggio procedurale, costituito da un insieme di operatori , definiti su relazioni e che producono ancora relazioni come risultati.
Ci sono vari operatori:
- operatori insiemistici tradizionali : unione, intersezione, differenza → possono essere definiti anche nelle relazioni;
- insiemistici specifici : ridenominazione, selezione ed elaborazione;
- join : presenta varie forme: join naturale, prodotto cartesiano, semijoin e theta join;
- divisione : ridondante, in quanto esprimibile con altri operatori.
SELEZIONE
Questo operatore è il primo che vediamo che permette di manipolare le relazioni. La selezione produce un sottoinsieme delle tuple che soddisfano una certa condizione, riducendole in orizzontale.
Viene utilizzato questo simbolo 𝝈 a pedice del quale viene indicata la condizione di selezione. Possiamo usare operatori di confronto (=,≠,<,>,≤,≥) all’interno della condizione. Si possono combinare condizioni differenti utilizzando gli operatori logici and ∧, or ∨, not ¬.
ESEMPIO Trovare gli impiegati con almeno 30 anni e uno stipendio maggiore di 4000.
Trovare i cittadini che sono nati nella città in cui hanno la residenza.
ESEMPIO DI SELEZIONE SUL RELAZIONALE
Aereo (Numero, OraPartenza, MinutoPartenza, Partenza, Destinazione, OraArrivo, MinutoArrivo, Categoria) Aeroporto (NumAereo, Nome, Ora, Minuto) Si richiede di produrre la lista di tutti gli aerei internazionali partiti dopo le 12.00 e prima delle 16.00.
PROIEZIONE
La proiezione riduce le tuple di una relazione in verticale, quindi elimina attributi.
Viene utilizzato questo simbolo 𝝅 a pedice del quale viene indicato l’attributo o gli attributi su cui vogliamo che avvenga la proiezione. Dati una relazione r(X) e un sottoinsieme Y di X, la proiezione di r su Y indicata con 𝜋) 𝑟 , è l’insieme delle tuple su Y ottenute dalle tuple di r considerando solo i valori su Y: 𝜋) 𝑟 = {𝑡[𝑌]|𝑡 ∈ 𝑟} 𝝅attributo(Relazione)
JOIN COMPLETO
All’estremo opposto possiamo avere la situazione in cui ciascuna tupla di un operando è combinabile con tutte le tuple dell’altro operando. Il risultato conterrà |𝑟1| × |𝑟2|, dove 𝑟 indica la cardinalità della relazione r, ossia quante tuple la compongono.
JOIN INCOMPLETO
Un join può produrre un risultato in cui non tutte le tuple degli operandi sono presenti nel risultato. In questo caso parliamo di tuple dondolanti.
JOIN ESTERNI
Reparto è la chiave, e in una chiave non posso avere valori nulli. Il join esterno (o outer join) prevede che tutte le tuple diano un contributo al risultato, eventualmente estendendolo con valori nulli. Ne esistono tre tipi:
“Operando” = relazione
Tipi numerici approssimati , tre tipi:
- float [(precisione)] → precisione indica il numero di cifre associate alla mantissa, mentre l'esponente dipende dall’implementazione.
- real → precisione fissa.
- double precision
Descrivono numeri approssimati mediante una rappresentazione in virgola mobile, in cui a ciascun numero corrisponde una coppia di valori: mantissa (valore frazionario) ed esponente (numero intero)
Istanti temporali : introdotti in SQL-2, descrivono informazioni temporali e possono avere tre diverse forme:
- date → ammette i campi year, month e day -- in SQL si scrive “AAAA-MM-GG” (tra apici).
- time [(Precisione)][with time zone] → ammette i campi hour, minute, second.
- timestamp [(Precisione)][with time zone] → ammette tutti i campi, da year a second.
L’opzione with time zone è usata per la differenza di fuso orario.
Intervalli temporali : permette di rappresentare intervalli di tempo. La sintassi è: interval PrimaUnitàDiTempo [ to UltimaUnitàDiTempo]
Domini introdotti in SQL-
- Boolean: valori booleani (true o false)
- Bigint: si aggiunge a smallint e integer.
- BLOB e CLOB: oggetti di grandi dimensioni; sequenza arbitraria di valori binari (BLOB, Binary Large Object) o di caratteri (CLOB, character Large Object).
4.2.2| Definizione di schema SQL consente la definizione di uno schema di base di dati come collezione di oggetti. Ha questa sintassi: create schema [NomeSchema] [authorization] Autorizzazione] {DefElementoSchema}
Autorizzazione rappresenta il nome dell’utente proprietario dello schema; se non è specificato, si assume che il proprietario sia l’utente che ha lanciato il comando.
4.2.3| Definizione delle tabelle Una tabella SQL è costituita da una collezione ordinata di attributi e da un insieme (eventualmente vuoto) di vincoli. Ogni tabella viene definita associando un nome ed elencando gli attributi che ne compongono lo schema.
Create table Dipartimento ( Nome varchar(20) primary key, indirizzo varchar(50) città varchar(20) )
4.2.4| Definizione dei domini
Create domain NomeDominio as TipoDiDato [ValoreDiDefault] [Vincolo]
4.2.6| Vincoli intrarelazionali
- not null il valore nullo non è ammesso per l’attributo; quindi, il valore deve sempre essere specificato, o si assegna un valore di default;
- unique definisce (super)chiavi, posso avere valori nulli;
- primary key chiave primaria (una sola, implica not null);
- check.
Vincolo not null Il vincolo NOT NULL determina che il valore nullo non è ammesso come valore dell’attributo. Nel caso di vincoli NOT NULL può essere utile specificare un valore di default per l’attributo. L’istruzione DEFAULT specifica un valore di default per un attributo quando un comando di inserimento dati non specifica nessun valore per l’attributo.
Vincolo Unique Il vincolo UNIQUE impone che i valori di un attributo (o di un insieme di attributi) siano una superchiave, cioè righe differenti della tabella non possono avere gli stessi valori.
Vincolo Primary Key Il vincolo PRIMARY KEY identifica l’attributo che rappresenta la chiave primaria della relazione:
- si usa una sola volta per tabella.
- implica il vincolo NOT NULL
Vincolo Check Il vincolo CHECK specifica un vincolo generico che devono soddisfare le tuple della tabella. Un vincolo CHECK è soddisfatto se la sua espressione è vera o nulla.
4.2.7| Vincoli Interrelazionali I vincoli interrelazionali più diffusi sono quelli di integrità referenziale. In SQL per la loro definizione si usa il vincolo foreign key. L’unico requisito è quello che l’attributo a cui fa riferimento sia soggetto a un vincolo unique. Il vincolo può essere definito in due modi:
- se c’è un solo attributo, si può usare il costrutto reference, con il quale si specifica la tabella esterna (e il suo attributo) a cui l’attributo in questione fa riferimento;
- quando vi sono più attributi, si usa il costrutto foreign key, posto al termine della definizione degli attributi, elencando gli attributi coinvolti e seguito dalle definizioni dei corrispondenti attributi della tabella esterna, sempre grazie a REFERENCES.
4.3.2| Dichiarazioni semplici Le operazioni di interrogazione vengono specificate per mezzo dell’istruzione select.
SELECT selezionare gli elementi che voglio vedere nel risultato; → proiezione in algebra relazionale; FROM elenco le tabelle da cui estraggo le tuple; WHERE specifico la\le condizione\i che le tuple devono rispettare.
Il risultato dell‘interrogazione è una tabella con una riga per ogni riga prodotta dalla clausola FROM ed eventualmente filtrata dalla clausola WHERE (se esiste), le cui colonne dipendono dalla lista degli attributi nella clausola SELECT.
CLAUSOLA FORM L’argomento della clausola FROM è la tabella o l’elenco di tabelle alle quali si vuole accedere.
- se viene specificato un elenco di tabelle, viene eseguito il loro prodotto cartesiano.
- sul prodotto cartesiano delle tabelle elencate vengono applicate le condizioni specificate nella clausola WHERE se presente. Si può usare l’operatore punto per identificare le tabelle da cui vengono estratti gli attributi (Impiegato.Nome).
CLAUSOLA WHERE La clausola WHERE ammette come argomento un’espressione booleana costruita combinando predicati semplici con gli operatori AND, OR e NOT.
- AND: seleziona le righe in cui tutti i predicati sono veri
- OR: seleziona le righe in cui almeno un predicato è vero
- NOT: seleziona le righe in cui il predicato è falso
Ciascun predicato semplice usa gli operatori =, <>, <, >, <= e >= per confrontare un’espressione costruita a partire dal valore di un attributo con un valore costante, oppure un’altra espressione. Per esprimere la precedenza degli operatori AND e OR si fa uso della parentesi.
CLAUSOLA SELECT Restituisce lo stesso risultato della query precedente, ma ri-denomina (temporaneamente) la colonna output Dipart.
SELECT: ALIAS DI TABELLA O ATTRIBUTO
CLAUSOLA WHERE
Estrarre i nomi ed il cognome degli impiegati che lavorano nell’ufficio 20 del dipartimento Amministrazione.