Scarica MIDA 1 - Model Identification and Data Analysis - Polimi e più Appunti in PDF di Model identification solo su Docsity!
THE (^) FEASIBILITY OF LEARNING THE (^) LEARNING PROBLEM - SUPERVISES L (^). P T
Input :^ XE^ :^ X =^ 2x , ..., Xn]
a set of attributes of an email
Output/label :^ ye Y^ y = (spam/nam] Target function^ :^ f^ :^ Y^ "roled^ law"^ that^ maps^ email^ attributes into (^) a certan (^) label Data : DN = ((x
, y())^ ,^ ( x(2)^ , y(z))^ ... (x()^ , y(n))) record^ of^ emails^ in^ the^ strack ↓ (4)^ : the entire set of attributes
about the first email
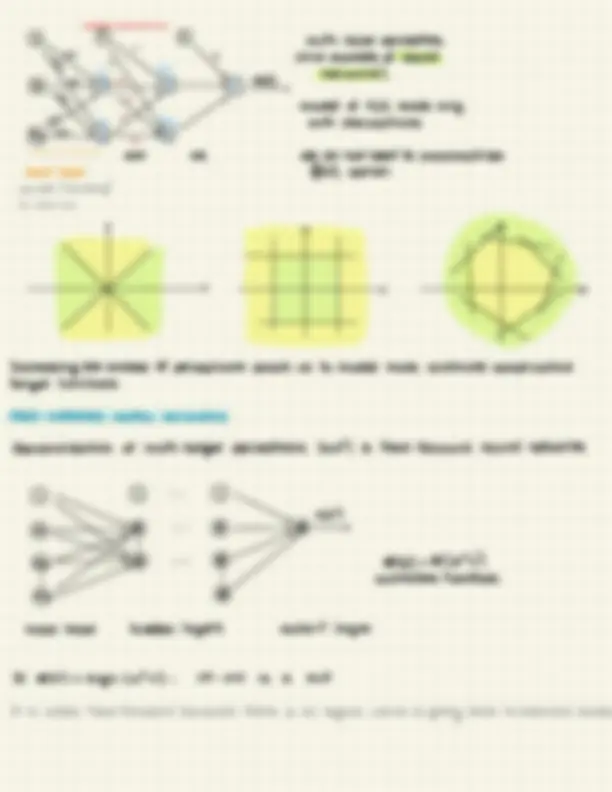
Hypothesis/model : g :^ candidate^ model^ forf & is^ choosed^ from a set of (^) candidate ge H^ :^ hypotesis^ set (^) formulas under consideration : It (^) hypothesis set THE LEARNING PROCEDURE unknown (^) examples (^) learning final G G (^) & hypothesis ↑ -^ Y^ (DATA) algorithm (^) g(f) N (^) &
M g is^ one^ specific model
hypothesis
set out^ of^ the^ set of possible
H (^) models
We can define^ this setI thanks to phisical insight into the application -^ we need to restrict our
attention to^ a specific set^ of^ models^ , depending on^ the^ application
The learning from (^) data is (^) meaningful If :
1. A^ patter exists .^ There^ must^ be^ something to learn^. X^ and y^ are actually related^ to each^ other
- (^) we cannot (^) pin it down (^) mathematically If (^) you have^ mathematical or (^) physical (^) knowledge you have to^ use it and there's no need to use^ a black^ box^ machine
- We (^) have data of the^ problema most^ restrictive (^) assumption
Ex : Learning problem in which^ every sample is^ composed by a^ set^ of^3 balls^ that^ can^ be
coloured or^ empty - For x")^ ,^ x(2)^ , y(3)0y =^ +^1 For x(m)^ , x(5)^ ,^ x(6)^ - y = -^3 4
↓
y (3) (^) x(n) x(5) &
· · ⑧ 0 O^00 What about17)^? x(7) · o o It can be^ y
= 1 If (^) you consider the color of (^) the first ball It can be (^) y 17)^ = -^1 if (^) you consider (^) no2 - (^) y = (^) + 1 3 We don't have^ enough info nc (^) -22 y=^1 to^ answer^ the^ question
2 :^ We^ want^ to^ fit^ a^ function^ through some (^) points :
Y A XEIR I · w The relationship between^ that^ points can^ be^ linear ·
iO but^ also^ non^ linear^ if^ they are^ part of^ a^ sinusold
-^ Y Learning from^ data^ is^ not^ feasible.^ Hume's^ problem^
of induction , 1748- but only from a
deterministic (^) point of view. But (^) it is (^) possible from (^) a statistical (^) point of view statistical models can be^ wrong but (^) they are not^ wrong BIN EXPERIMENT There (^) is a bin in which we can not (^) see inside. There is an^ unknow
number of red and blue^ marbles
↑ I :
-.
we (^) pick N^ marbles (^) independenty p :^ ip[picking a^ blue^ marble]^ (p^ is^ unknow) N : fraction^ of^ blue^ marbles^ in^ the^ sample^ (^ is^ known)
blue marble^ <^ g(x) =^ f(x)
red marble <^ >^ g(x) = f(x)
For each (^) data (^) point Xi (^) we know (^) f(xi) and for (^) each (^) ge tt we can find out whether
g(xi) =^ f(xi)^ or^ not
This doesn't tell (^) us whatf (^) is (^) , but it can tell us if (^) I will (^) approx. f tells an (^) estimation of the (^) error rate (^) p thatg makes (^) in approximating
f.
We (^) can explore the entire (^) hypothesis set H to find (^) a function h with small (^) error rate
We need to introduce the concept of error rate estimation I for learning problems
IN SAMPLE ERROR : Ein(g)
= [g(x(i))^ +^ f(x(i)))^ (g(H) cerrore sul^ dataset) XEN
- (^) D =^1 if the statement (^) is true I · D =^0 if (^) the statement (^) is false The (^) in-sample error e[o, 17 and (^) tells us now (^) good our model is based on the extracted dataset OUT OF SAMPLE ERROR E^ out(g) = 1P(g(x) + (^) f(x)]
lerrore su altri campioni)
Xe N This is the^ real^ probability of (^) mis-classifying one (^) input We (^) can (^) apply (^) Hoeffding's inequality for the (^) learning problem
- 2E2N Ip((p -^ pl^ >^ 2)^ <^ ze^ bin^ experiment y
- (^) 2E2N IP(1Ein(g) -^ Fout(g)/^ >^ []^ =^ 2e^ verification^ of^ a^ model^ g Idoes (^) not depends on^ f^ and^ Eout The (^) inequality tell^ us if^ the^ misclassification error made (^) by (^) g on the^ sample is representative of^ the^ misclassification^ error^ over /
I don't^ want^ g to be^ equal to^ f^. I want to generalize well^ also^ with^ other^ set
gi M^ =^3 candidate^ models^ M^ =^11 HIl 92 93 - Cardinality IP(/Ein(g) - Fout(g)/c2] =^ 2Me.2EN^ > (^) we'll (^) need more samples If M increase we are^ not^ sure (^) anymore that^ Einlg) Fout(g). On the^ other^ hand the^ higher M^ ,
the smaller Ein because we can
findg that^ fits (^) well the data: trade off OBJECTIVES (^) OF LEARNING (^2). (^) Fitting : (^) Minimize (^) Ein(g) with (^) respect to (^) gett & trade-of
- Generalization^ :^ minimeze^ /Ein(g) -Eout(g)/ Minimization of^ Fout(g) is not^ possible
LINEAR CLASSIFICATION O^ We^ have^ a^ line^ , so there^ are^2 classes
f(x) (^) - DATA (^) Learning (^) -G algorithm (^) model of (^) the A description of^ A^ turget^
function
the real World by a^ turget ↑ function H
How can I select the set of model :
guess Istart with (^) a (^) simple model (^) class) H
prior physical knowledg ↑
&
For now we assume I Is given and includes the^ target function. f
We also assume It is the class of linear functions I
To find^ out^ the best^ filting model we use PLA PERCEPTRON (^) LEARNING ALGORITHM (PLA) key assumption^ :^ there^ exists^ a^ hyperplane^ that^ divides^ the^ classes The main rationale behind PLA is^ to^ move the line until we don't^ have (^) any misclassified (^) points -wan(x(il (^) , w(a))^ = y (i)^ , V(x(i) (^) , y(i)) e Di 42 ,height^
- we drow (^) a line random ...
- There is at least one misclassified (^) point ... ...... I
. (^) & - (^) weight
- X 42 ,height^ y S (^) 3) If we rotate (^) the line (^) we can classified ... well (^) every point ... ...... I . (^) & Butnow^ can^ I^ rotate^ the^ line^?
- weight X
How to^ rotate^ the line :
PLA UPDATE RULE
It (^) serves to (^) improve the (^) quality of^ w^. M n(x, w) =^ [iwixi^ =^ wTx i =^0 It's (^) an iterative (^) algorithm.
· We start with random
guess (for^ w)
this (^) is a new coefficient for^ m-point · With (^) iteration (t) : wHH) = w(t) + y(m) (t)^
. X (m)(t) ( (m) , (^) y (m))^ denotes^ one^ misclassified^ point
THEOREM 1 :
PLA (^) converges to perfect classification in a finite number^ of^ iteration. ·^ Good^ in^ terms^ of data (^) Fitting (Ein) we don't know Why does^ PLA^ Update^ rule^ work^ :^ anything^ about^ Eout Assume (x(m) (^) , y(m)) is a misclassified^ point +^ y(m) + n(x (m)^ , w(t)) Assume (^) y(m) =^ + 1
- y(m) =^ h(x(m)^ ,^ w(t))^ =^ - 1 = (^) sign(w(t) - y(m)) = - 1 · (^) w(t(T. (^) x (m)^ > (^) o T (^) T w(t +^ 1)^. x (m)(t)^ =^ w(t).^ x(m)(t)^ + (^) x(m(Yy)y(m)(t) -x(m)(t)^.^ x(m)(t)^ trasposition I want^ this to^ be^ argument of^ sign > (^8) O ↓ (m) t).^ x(m)(t) = xi^ +^ +2^ +....^ >o y(m)(t) =^150
If the result is^ so on
If the result^ is^ to^ the^ algorithm continues^ and^ the^ term^ witTx (m) (t) becomes avery time^ less^ negative by (^) adding a^ positive^ term · PLA solves the filting problem · Generalization (^) problem could be an issue
- 2 N · Hoeffding Inequality^ : (^) 1P(IEin(g) - Eout(g) 1 > (^) E) = 2 Me &
number of candidate
THEOREM 2 models
Fout(g)
= (^) IP(n(x) + (^) f(x)] = Ein(g) + (^) 0) dimension of^ the^ input vector · en (^) (N)) NX (^) size of the dataset Fout(g) =^ Ein(g)^ +^ 0) - en(N) The difference between Font and Ein decrease with^ N and increase with the number of
feature n in X
objective to^ minimize^ :^ Eout(n)^ = It((n()-f(x))] not^ possible to^ compute it Approssimate (^) sample-based objective : Ein(h)-hilgli^ can be^ compt se We want^ to^ find^ the^ line/surface^ that^ minimize^ Ein^ least^ squares problem Hypothesis set^ : y =^ w,^ X^ +^ wo^ /2D^ casel U N y = [wixi +^ wo^
= 2 wixi = wTx^ (n-dimentional^ space)
i =^0 General Idea : (^) we want^ to (^) minimize the vertical distance between the (^) point and the predictor (^) y Learning problem^ =^ optimization^ problem
min Ein(h)^ =^ min Ein(w)
n(x) W Ein(w) = wixyli
- o ...I^ Y CIRNy(n^ + 1) i (^) (data matrix) " IN^ X (^) ,^ (N) O / yE IRN scalar output ww nx^1 Ein(w) (^) = (wx)^ yliwYY
To find^ the^ minimum of^ a function Ein^ (W) , we need^ to^ set^ the^ gradient of^ the function
to (^0) Necessary condition^ for^ optimality^ : ·^ 2Ein(w)
Ein(w) =^0 -^ =^ O gradient is null
zu (^) w
- > estimated (^) minimum (^) point ·^ GEinIw)^30 nession is (^) positive definite aW2 (^) We ↓
So the^ point we find^ is a minimum
Linear (^) algebra recall : d +^1 A (^) Matrix (^) M(d + ) +^ (d^ +^ 1)^ IS (^) positive definite (M30) if^ Maso^ , VX0^ , XeIR Trides : · Vw(w"Aw) = (^) (A + (^) AT) w (^) , A c1R(d +) +(d+1)
· Vw(wTb) = b belrd+
Ein(w) = (wix" Xw + yy - 2wTXTy) *Ein(w) = * (2x
(x
(x+^ x)w^ =^ x +^ y^ normal^ equations
-Ein(w) =^ (x+^ Xw - x (^) y)
:Ein1w) =
So (^) , Nu Ein V au Second condition^ is (^) always satisfied ↓ W2 ·^ JW, L I we have^ one (^) stationary point , this^ is^ a^ minimum
= (^) x : (^) prediction of heart (^) attack blood It^ can^ be^ formulated^ as^ a & age (^) G^ f(x)^
Y ~ occurrence of binary classification problem , but :
: (^) & a heart attack the corresponding prediction^ will^
have
weight (^) very low accuracy
the output is a probability
In (^) supervised (^) learning problems : Y (^) I
X g (^) f(x) P(y/X)& random^ y (^) & stocastic (^) description
: extraction^ of the real world
Xn
we are not^ interested in (^) y but in (^) P(y(x) Turget function^ :^ f(x)^ =^ IP(y^ =^1 (x) Sequivalent description^ :^ f(x)^ = 1P(y =^ - 1(x))
IP(y =^ 1(x)^? In this case
yf f(x) f(x) (^) ~ data ⑭ & &
H
He have two (^) problems : · we need to (^) determine the (^) hypotesis Set H
· we need to select a proper
learning algorithm^ A
Let's select the hypotesis set H :
lnear classification : Y ·
wTX
S & go^ Y^ G ye( -^1 ,^ +^13 &
Y Sa Y
linear (^) regression model ·^ wTX^ &^ g^ G y EIR Si (^) score S= wTX
we can assume the
risk is linear
In our (^) problem , the^ output of^ the^ model^ is a (^) probability it^ must be^ a number e [0, 17 LOGISTIC MODEL
takes a linear combination^ of^ the (^) Input
Y (^5) .- s^ represents^ the^ risk
· wTX go G
also known as :^ soft threshold
S or^ sigmod function
h(s) = e
e [0, 1] logistic function^
g 1 +^ es g this^ can^ be^ used^ to^ output^ a^ probability S
score could^ be^ seen^ as^ a^ model^ of^ the^ risk
h(x) (^) y =^ + 1 IP(y =^ +^ 1)x] =
I 1 - h(x)
y =^ -^1 es (^) I h(s) =^1 -^ h(S)^ =^ =^ h)^ - S)
1 + es^1 +^ es
(P[y =^ +^ 1(x]^ =^ h(y^
- S) = h(y wix) The (^) objective of the learning problem^ : to find w such that (^) hlywix) -^ f(x) Main issue (^) : we do^ not measure the (^) output of^ f(x)! In linear^ classification : (^1) Ein(g) = [i(f(x) + (^) n(x)]) (^) everytime I (^) missclassified a (^) point y y^ = sign(wTx) In linear^ regression : Ein(h) (^) = (fx)^ n^ mean (^) squared error Y y =Tx
In logistic regression :
err(y(i) (^) , nw(X(i))^ =^ en(1^ +^ e
- y(i)wTx(i)) cross. (^) entropy We (^) have formulated the (^) optimization problem : nw(x) =^ estimate^ of^ the^ probability f(x) = argmin (^) tens e -y(i)wT X(i)) W wenters (^) non (^) linearly the cost function to minimize
In this case Ein depends non-linearly on w
NONLINEAR OPTIMIZATION In (^) logistic (^) regression : N
Ein(w) =
[en(
- e y) (^) wix(i)) pointwise error err(y(i) ,^ hw(x(i) we want to find the minimum of^ Ein : = (^) argmin Ein (^) (w) w We need^ to set : VEin() =^ o D (^) Ein(w)-en+ (^) e y will
1 + e g(i)wTy(i)^
= 1 = gli^1 + ey(i)wT x(i) There is (^) no analitical (^) expression for i^ s (^).^ t. VEin(w) =o This (^) is a non linear function o^ we can not (^) compute : VEin(w) =^0 We'll use an (^) algorithm which is used for^ numerical^ minimization. This (^) algorithm is called (^) gradient descent
GRADIENT DESCENT
Ein() Objective : to start from a (possibly random)
guess i of w (^) and more towards a minimum of (^) the (^) curve
Some problems :
M ↑ (^1 1). how to (^) "roll down" the surface in (^) a high-dimensional w(d) (^) local (^) global w
setting
minimum?
minimum
- (^) how not to (^) be stuck in local (^) minima?
Initialization issue :
Open problem Smart (^) Strategy : (^) We can (^) try several initial conditions and take^ the best^ minimizer How not to be stuck in local (^) minima : (2.) Good (^) news : (^) logistic model has (^) only one (^) minimum (the cast is convex) Ein(w)" Ein(w)^ is^ a^ convex^ function^ , so^ it^ has^ only 1 minimum · (^) GD can not end (^) up in (^) a local minimum (^) , so (^) problem 2. does (^) not exist. -W How to roll down the surface :^ (1^. )
w[o] -^ W(l] :...^ o^ wend] =^ w
key idea^ of^ gradient^ descent (^) (GD) : to take (^) a "small step" in the direction of a unit Vector r w[i +^ 1) = (^) w(i) + nu n : (^) Step size What is the best^ choise for V^ : We need^ to^ find the direction ofi corresponding to the^ steepest slope (^) (negative -Ein(w) =^ Ein^ (w(it) -^ Ein^ (w(is) (^) Ein(w)"
Ein[wi] Ein[wi]sEin[wit]
we want^ DEin(w)^ to^ be^ the^ largest possible" · ( with^ negative (^) sign!^ ) Ein(wi^ +^ 1]^ -W
The best situation is^ a variable n
wich starts as a large number and lower^ as^ we
get close^ to^ the^ minimum
Heuristics :
& (iz
= 7
. (^110) Ein (^) (w(ij)Il [i] : learning rate this is an indicator of "how far" the^ minimum is Final (^) update rule^ : VEin (^) (w(it) (^) = w(i] - m/18Ein(wsi)). DEin(w(is) W[i +^ 1] = W (i) - 7(i]
118tin (wsiTII 1)^ VEin(wCiT^ Ill
GD rule : (^) W[it] = (i]-nBEin (w[i])
Algorithm :
- Initialize the (^) weights w[0] B. (^) for i = (^0) , 1 ... do
- compute the gradient Ein^ (w[i])
- Set the (^) direction (^) v[i] = (^) VEin(w(il)
update the^ weights w[it] =^ W[i] +^ V[i]
- (^) iterate until it's (^) time to (^) stop Stoppingcriteria^ :
Ein 1 .To set a threshold on 11VEin 11
· 2. Upper bound on the number of iterations
& an (^) leration · 3. To set a threshold (^) on (^) Ein number
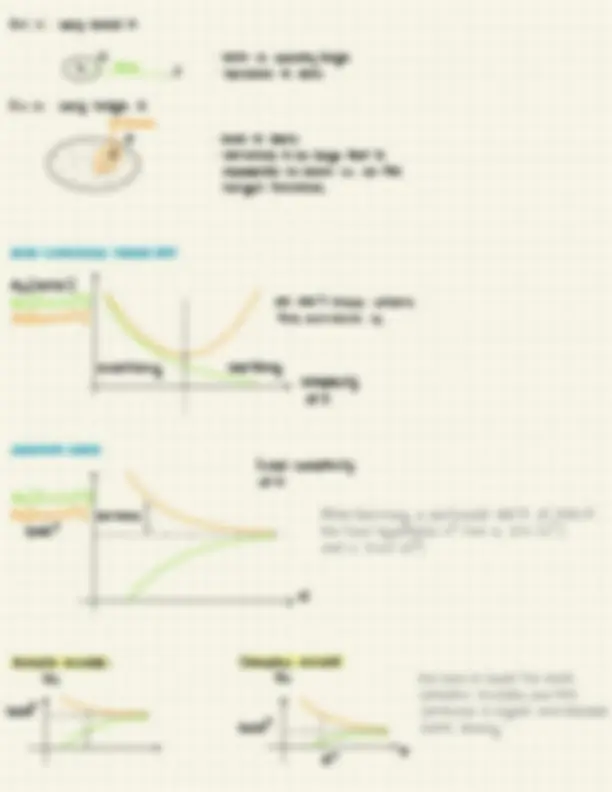
THE BIAS-VARIANCE TRADE OFF
In (^) machine (^) learning , there (^) are two main (^) problems
=. Data fitting (to "explain" the^ observation)
- Generalization
filting
Me data & g() (^ = (x) &
H
To (^) have a trade-off between data (^) fitting and (^) generalization , we have to^ choose the right hypothesis set^ H.
· If the set is too
big I^ cannot^ zoom^ in^
the right hypothesis
· If the set is too small it's
very (^) likely that^ my target^ function^ is^ outside J Blas/Variance (^) decomposition of Fout is the (^) right tool to (^) chose H BIAS-VARIANCE DECOMPOSITION Iwe focus on linear (^) regression only , for (^) simplicity) Dr = G(x) , (^) y(1)) , (x(2), y(2)) ... (x (^ *) , y(N))) data set^ (N^ fixed) n(x(i)) = (^) w +^ x(i)^ = (^) y(i) class (^) of models (^) In fixed) We assume that (^) y(i) =^ f(x(i))^ ~^ no noise in the dataset Ein(w) (^) = (y(i) · y(i)(y() wx)^ costfunction^ to^ minimee se Real (^) objective (unfeasible) :^ minimization^ of^ Eout(w) D It (^) out (n) =(((f(x) -^ (x))"]
È weighted over all X domain
#p (Eout^ (n"))^ :^ che +^ (f(x)^
- nP(x))2]) average on^ all^ possible^ dataset