Scarica Modellazione dei dati (Database) e più Schemi e mappe concettuali in PDF di Elementi di Informatica solo su Docsity!
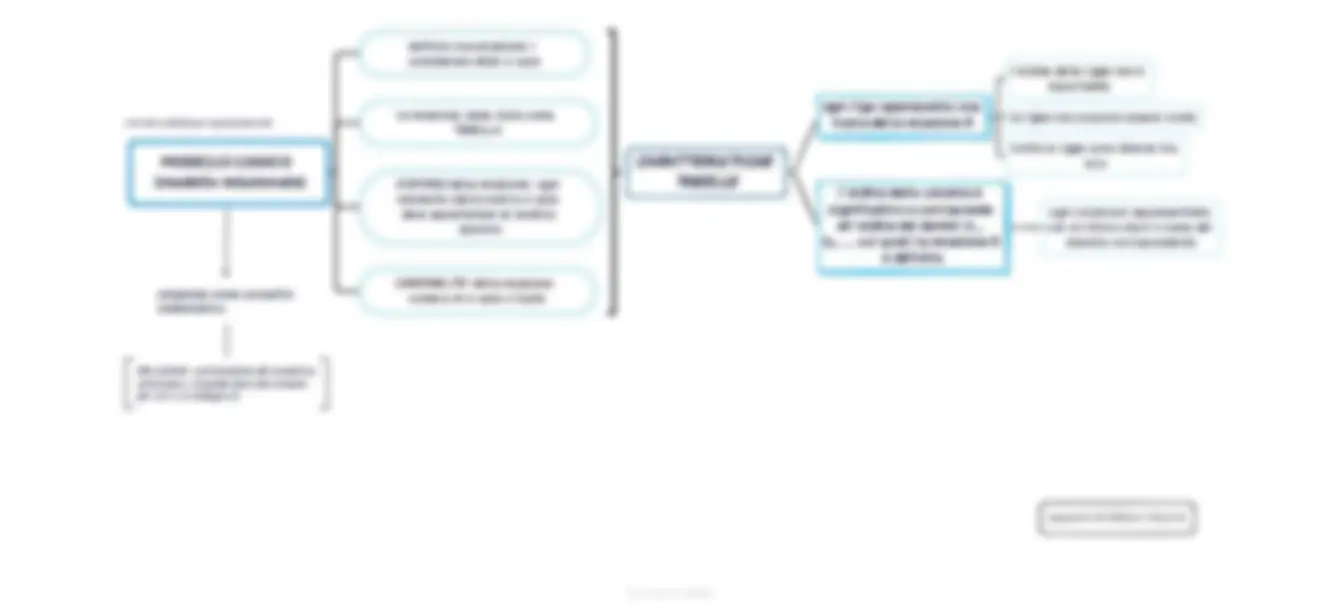
MODELLAZIONE DEI
DATI
REALTA'
MODELLO CONCETTUALE
(modello E/R)
ENTITA' ASSOCIAZIONE 1: 1:N N:N ATTRIBUTI DOMINIO FORMATO DIMENSIONE OPZIONALITA' NULL
MODELLO LOGICO
(modello relazionale)
TABELLA DOMINIO CARDINALITA' CARATTERISTICHE TABELLE RIGHE COLONNE
LIVELLO FISICO
riguarda l'effettiva rappresentazione dei dati nei dischi del computer
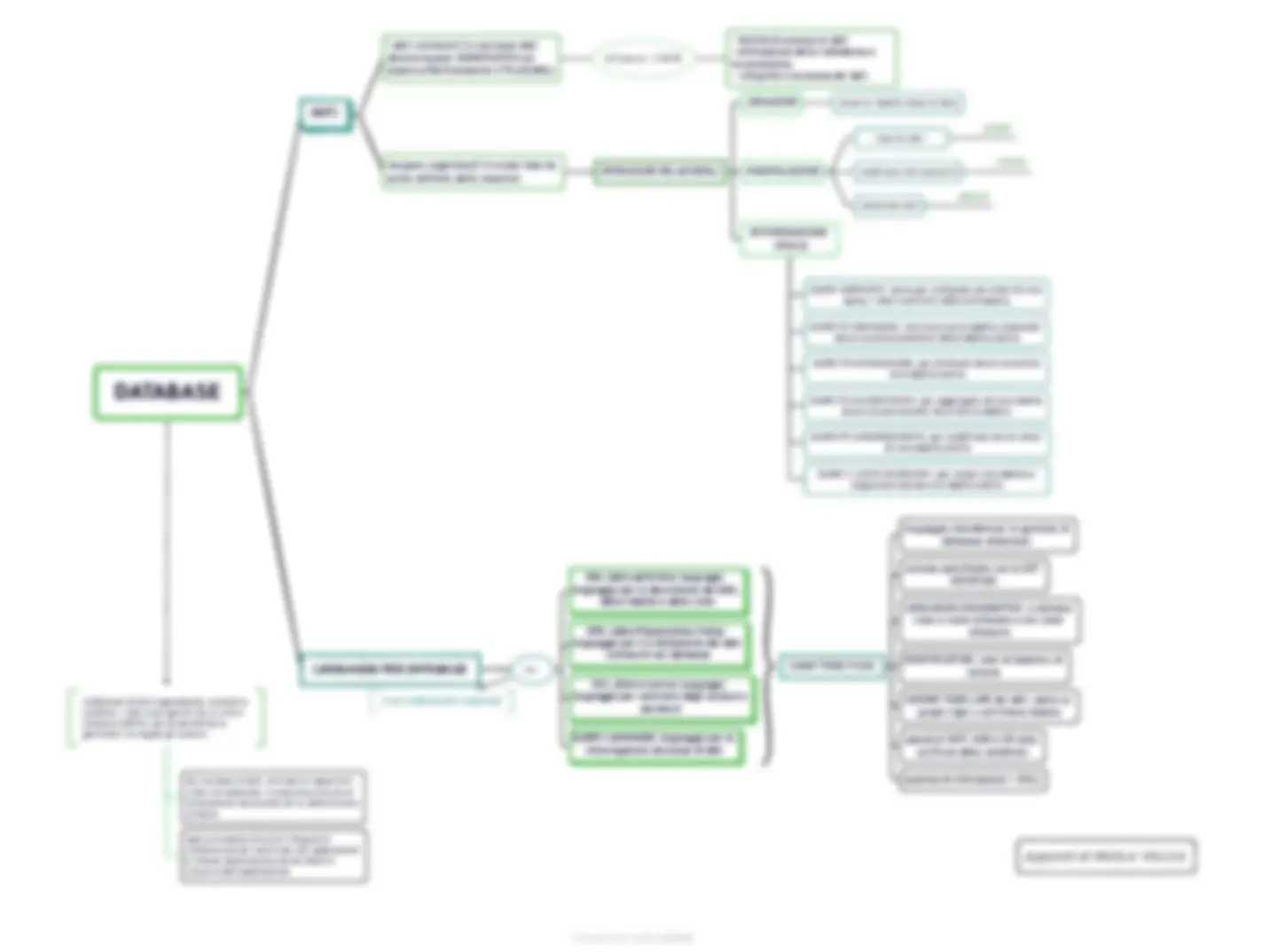
DATABASE
DATI OPERAZIONI RELAZIONALI CREAZIONE MANIPOLAZIONE QUERY SQL DDL DML DCL QUERY LANGUAGE e... SELECT FUNZIONI DI AGGREGAZIONE^ Conteggio, Somma, Media, Min/Max) ORDINAMENTI^ Crescenti o Decrescenti RAGGRUPPAMENTI con Funzioni di Aggregazione o clausola Having Attività di raccolta, organizzazione e conservazione dei dati.
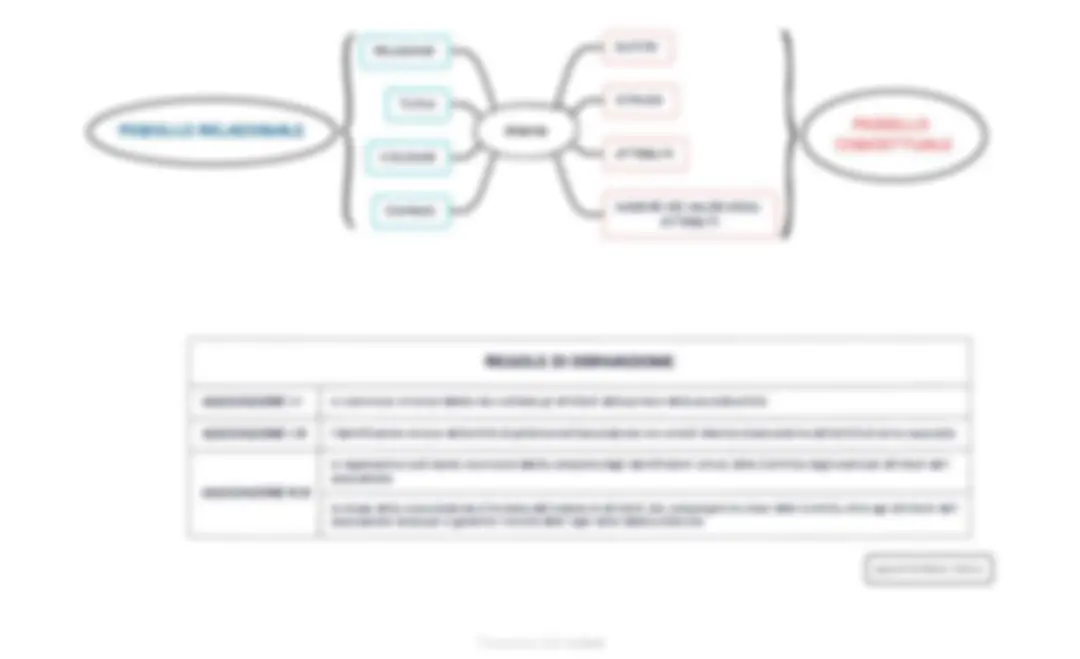
MODELLO CONCETTUALE (modello E/R)
ENTITA': oggetto, concreto o
astratto, che ha un significato.
ASSOCIAZIONE (relationship):
legame tra due entità che
stabilisce un'interazione tra le
stesse.
1 �1 (UNO A UNO): biunivoca. Ad ogni istanza della prima entità si associa una sola istanza della seconda entità e viceversa. 1:N (UNO A MOLTI): semplice. Ad ogni istanza della prima entità si può associare una o più istanze della seconda entità, mentre ad ogni istanza della seconda entità si deve associare una sola istanza della prima. N:N (MOLTI A MOLTI): complessa. Ad ogni istanza della prima entità si possono associare una o più istanze della seconda entità e ad ogni istanza della seconda entità si possono associare una o più istanze della prima. strumento utile per analizzare le caratteristiche di una realtà in modo indipendente dagli eventi che in essa accadono
CHIAVE PRIMARIA
(Primary Key)
insieme minimale di uno o più attributi che permette di distinguere un'istanza dall'altra. Non può avere valore nullo. C'è n'è una sola per ogni entità. Non può essere duplicata. es. matricola di uno studente
SUPERCHIAVE
sottoinsieme di attributi della relazione che consentono di identificare univocamente le tuple di una relazione.
CHIAVE
superchiave minimale. Togliendo anche uno solo degli attributi della superchiave ottengo delle tuple duplicate. In un'entità ci possono essere più chiavi.
CHIAVE ESTERNA
(Foreign Key)
colonna o gruppo di colonne in una tabella che contiene valori corrispondenti alla chiave primaria in un'altra tabella. es. studente, facoltà es. studente → facoltà es. studente: matricola, cognome, nome
ATTRIBUTI: proprietà che
caratterizzano le entità e le
associazioni. Sono da
considerarsi come delle variabili.
DOMINIO: insieme dei valori che può assumere l'attributo FORMATO: indica il tipo di valori che assume un attributo DIMENSIONE: quantità massima di caratteri o cifre inseribili OPZIONALITA': possibilità di esser valorizzato o meno NULL: valore nullo Appunti di PAOLA VILLCA
diventa
ENTITA'
ISTANZA
ATTRIBUTI
INSIEME DEI VALORI DEGLI
ATTRIBUTI
DOMINIO
COLONNE
TUPLA
RELAZIONE
REGOLE DI DERIVAZIONE
ASSOCIAZIONE 1� 1 si costruisce un'unica tabella che contiene gli attributi della prima e della seconda entità
ASSOCIAZIONE 1:N l'identificatore univoco dell'entità di partenza nell'associazione uno a molti diventa chiave esterna dell'entità di arrivo associata
ASSOCIAZIONE N:N
si rappresenta costruendo una nuova tabella composta dagli identificatori univoci delle 2 entità e dagli eventuali attributi dell' associazione la chiave della nuova relazione è formata dall'insieme di attributi che compongono le chiavi delle 2 entità, oltre agli attributi dell' associazione necessari a garantire l'unicità delle righe nella tabella ottenuta MODELLO RELAZIONALE MODELLO CONCETTUALE
DATABASE
DATI
i dati contenuti in una base dati devono essere SIGNIFICATIVI ed essere effettivamente UTILIZZABILI attraverso il DBMS
**- facilità di accesso ai dati
- eliminazione della ridondanza e inconsistenza** - integrità e sicurezza dei dati vengono organizzati in modo tale da poter definire delle relazioni
OPERAZIONI RELAZIONALI
CREAZIONE creare le tabelle (base di dati) MANIPOLAZIONE inserire dati INSERT modificare dati presenti UPDATE cancellare dati DELETE INTERROGAZIONE (Query) QUERY NIDIFICATA: serve per utilizzare nei criteri di una query i valori restituiti dalla sottoquery QUERY DI CREAZIONE: crea una nuova tabella, inserendo alcuni record provenienti dalla tabella scelta QUERY DI ELIMINAZIONE: per eliminare alcuni record da una tabella scelta QUERY DI ACCODAMENTO: per aggiungere ad una tabella alcuni record estratti da un'altra tabella QUERY DI AGGIORNAMENTO: per modificare alcuni valori di una tabella scelta QUERY A CAMPI INCROCIATI: per creare una tabella a doppia entrata da una tabella scelta
LINGUAGGI PER DATABASE^ SQL
DDL (data definition language): linguaggio per la descrizione dei dati, delle tabelle e delle viste DML (data Manipulation Data): linguaggio per il trattamento dei dati contenuti nel database DCL (Data Control Language): linguaggio per controllo degli accessi e permessi QUERY LANGUAGE: linguaggio per le interrogazioni alla base di dati
CARATTERISTICHE
linguaggio standard per la gestione di database relazionali colonne specificate con la DOT NOTATION LINGUAGGIO DICHIARATIVO: si dichiara cosa si vuole ottenere e non come ottenerlo IDENTIFICATORI: nomi di tabelle e di colonne VISIONE TABELLARE dei dati: opera su gruppi righe o sull'intera tabella operatori NOT, AND e OR nella scrittura delle condizioni assenza di informazioni = NULL Collezione di dati logicamente correlati e condivisi. I dati sono gestiti da un unico sistema (DBMS) che ne permette la gestione e ne regola gli accessi. da una base di dati, attraverso opportuni criteri di selezione, si possono estrarre le informazioni necessarie ad un determinato utilizzo. questo insieme di archivi integrati è condiviso da più utenti per più applicazioni e rimane memorizzato anche dopo la chiusura dell'applicazione. STUCTURED QUERY LANGUAGE
Appunti di PAOLA VILLCA
NORMALIZZAZIONE
COS'E'? è un processo con il quale le tabelle vengono trasformate affinché vengano eliminate la ripetizione dei dati e la ridondanza delle informazioni la relazione iniziale viene scomposta in più relazioni le relazioni complessivamente forniscono le stesse informazioni di partenza mantengono le dipendenze tra gli attributi: in ciascuna tabella ogni attributo dipende direttamente dalla chiave vengono evitati problemi di ridondanza e di inconsistenza dei dati non ci deve essere perdita complessiva delle informazioni COME FUNZIONA? le regole di normalizzazione sono definite per evitare inconsistenze ed anomalie a seguito di operazioni di aggiornamento dei dati PRIMA FORMA NORMALE
una tabella si dice in prima forma
nomale se e solo se tutti i suoi
attributi sono valori atomici.
Pertanto, né attributi né valori
possono essere possono essere
scomposti ulteriormente
SECONDA FORMA NORMALE
richiede che la tabella sia in prima
forma normale e che tutti gli
attributi non-chiave dipendano
dall'intera chiave e non solo da
una parte di essa
elimina la DIPENDENZA PARZIALE
degli attributi della chiave
TERZA FORMA NORMALE
richiede che la tabella sia già in
seconda forma normale e che tutti
gli attributi non-chiave dipendano
direttamente dalla chiave
elimina la DIPENDENZA TRANSITIVA
degli attributi dalla chiave
serve per certificare la qualità dello schema di un data base