Scarica Introduzione alla Programmazione Concorrente: Fork, Join e Semafori e più Appunti in PDF di Informatica solo su Docsity!
LA PROGRAMMAZIONE CONCORRENTE
Per programmazione concorrente s’intende l’insieme delle tecniche, delle metodologie e degli strumenti utili a realizzare l’esecuzione contemporanea (parallela) di più attività o processi in un sistema di calcolo.
Programma e processo.
Ricordiamo la differenza tra programma e processo. Il programma è costituito dall’insieme delle istruzioni ed è memorizzato su memoria di massa (ad esempio l’hard-disk). Il programma è un’entità statica.
Il processo ha origine dall’esecuzione di un programma mmmmmda parte di un esecutore, ossia il programma diventa un processo quando viene eseguito.
In altri termini, il processo è un’istanza di un programma in evoluzione, ossia l’istanza di un programma eseguito dal processore ( CPU ), quindi il processo deve risiedere nella RAM, la memoria centrale. Il processo è un’entità dinamica.
Multiprogrammazione.
Una delle funzioni del sistema operativo (S.O.) è quella di gestore del processore (CPU). In tale funzione uno degli obiettivi è l’ottimizzazione dell’utilizzo della CPU. L’ottimizzazione del tempo della CPU avviene grazie alla multiprogrammazione, ossia alla contemporanea presenza di più programmi (o meglio processi) nella memoria centrale ai quali il S.O. alternativamente assegna, per un determinato quanto di tempo, e revoca la CPU secondo opportune politiche di scheduling.
La multiprogrammazione, quale esecuzione alternata di processi diversi, è una forma di programmazione concorrente. Nota bene : una reale elaborazione contemporanea di più processi può avvenire solo in presenza di un’architettura hardware con più processori realizzando un vero e proprio parallelismo di esecuzione. [Anche i moderni computer con singolo processore multi-core, ossia un singolo processore suddiviso al proprio interno in 2 o 4 unità di elaborazione autonome, possono essere considerati da un punto di vista logico come un vero e proprio computer multiprocessore.] In una architettura monoprocessore il parallelismo, realizzato grazie alla multiprogrammazione, è solo virtuale. In una architettura monoprocessore parliamo più correttamente di interleaving.
ESEMPIO 1. Nei sistemi multiprocessore più processi vengono eseguiti simultaneamente su processori diversi e quindi possono ‘girare’ in parallelo, si sovrappongono nel tempo (overlapping).
Nel disegno mostriamo l’overlapping di due processi, uno identificato con PID 1256 ed un altro identificato con PID 1274, che vengono eseguiti in una architettura dotata di due processori, indicati come CPU 0 e CPU 1.
1256
1274
ESEMPIO 2. Nelle architetture con un singolo processore i processi sono alternati nel tempo, ma con velocità tali da dare l’impressione di avere un multiprocessore. Si definisce interleaving la situazione di alternanza casuale che possono avere i processi a causa delle diverse modalità di schedulazione.
Nel disegno mostriamo l’alternanza di due processi, uno identificato con PID 1256 ed un altro identificato con PID 1274, che vengono eseguiti dall’unico processore indicato come CPU 0.
1256
1274
Nel nostro corso abbiamo sempre fatto riferimento ad architetture monoprocessore, nota comunque che anche in caso di architetture multi-processore è necessaria una politica di scheduling in quanto il numero di programmi in esecuzione è di solito molto superiore al numero di processori.
Un'altra immagine che può aiutare a visualizzare il concetto di multiprogrammazione (o multi- processing) è la seguente:
I processi sono i programmi in evoluzione e per poter evolvere hanno bisogno delle risorse del sistema di elaborazione. Possiamo vedere il sistema di elaborazione proprio come composto da un insieme di risorse da assegnare ai processi affinché questi possano svolgere il proprio compito.
Una definizione di RISORSA è: Ogni componente dell’elaboratore, riusabile o meno, sia hardware, sia software necessario al processo o al sistema.
Essendo le risorse in numero limitato, i processi sono in competizione per poterle utilizzare: per esempio i processi competono per avere a disposizione la memoria RAM, per utilizzare l’interfaccia di rete, le stampanti ecc. I processi in particolare competono soprattutto per il processore che, nelle nostre architetture, è singolo e senza di esso nessun processo potrebbe evolvere.
Le risorse : si dividono in:
- prerilasciabili (o preempitive) , che possono essere sottratte ad un processo senza comprometterne l'esecuzione;
- non prerilasciabili (o non preempitive ), la cui sottrazione al processo che le sta utilizzando comporta il fallimento del processo stesso.
Esempio tipico di risorsa preemptive è la CPU. Esempi tipici di risorse non-preemptive sono la stampante e il masterizzatore: se interrompiamo il processo che le sta utilizzando, molto probabilmente viene danneggiato, se non del tutto compromesso, il lavoro in fase di svolgimento.
Risorse equivalenti, per esempio bytes della memoria, stampanti dello stesso tipo ecc., sono dette appartenere alla stessa classe CLASSE E ISTANZE Le risorse di una classe vengono dette istanze della classe; il numero di risorse in una classe viene detto molteplicità del tipo di risorsa. Per esempio, se il sistema dispone di tre stampanti dello stesso tipo, la molteplicità di questo tipo di stampante è 3, mentre ogni singola stampante rappresenta una istanza della classe “stampante del tipo XXX”. La molteplicità di una risorsa coincide con il numero di processi che possono usare concorrentemente la risorsa. Risorse di molteplicità finita necessitano di un accesso controllato. L'accesso si struttura in: ➢ un gestore della risorsa ➢ un protocollo di accesso alla risorsa
[Da inserire la sezione sui Thread]
[Eventualmente, per una introduzione al concetto si può anche consultare https://it.wikipedia.org/wiki/Processo(informatica)]_
ESEMPIO. Ordinamento totale e parziale Vediamo un esempio, dove il problema da risolvere è quello di valutare una espressione matematica: (2 * 6) + (1 + 4) * (5 - 2)
Le regole di precedenza in questo caso sono dettate dalla matematica, dove dapprima si devono eseguire le operazioni all’interno delle parentesi e successivamente si deve rispettare le precedenza degli operatori (/, *, + e -).
Rappresentiamo la soluzione con il grafo sequenziale a ordinamento totale
Inizio
Fine
Notiamo che non esiste l’obbligo di un ordinamento totale fra le operazioni da eseguire nelle parentesi: potremmo indifferentemente eseguire prima (1 + 4) piuttosto che (2 * 6) o viceversa senza compromettere il risultato finale.
Rappresentiamo la soluzione con il grafo a ordinamento parziale, dove introduciamo la parallelizzazione delle attività (che in questo caso sono tutte operazioni algebriche):
Per poter correttamente descrivere la concorrenza è necessario distinguere le attività che i processi eseguono in due tipologie: ◗ attività completamente indipendenti; ◗ attività interagenti.
PROCESSI INDIPENDENTI L’evoluzione di un processo non influenza quella dell’altro. I processi indipendenti sia che vengano eseguiti in sequenza che in parallelo non possono in nessun caso generare situazioni di funzionamento problematiche: l’unico vincolo è quello di rispettare per ogni processo l’ordine stabilito delle operazioni.
ESEMPIO Scomposizione in processi indipendenti
Consideriamo il seguente segmento di codice (in psedo-codifica):
Possiamo scomporre il programma in due segmenti completamente indipendenti:
Otteniamo due processi che eseguono ciascuno tre istruzioni che non hanno nulla in comune. Il grafo di precedenze può essere scomposto in due grafi completamente autonomi.
Processi interagenti Parliamo di processi interagenti quando due (o più) processi non possono evolvere in modo completamente autonomo perché devono interagire o volontariamente o involontariamente e quindi la rappresentazione nel grafo delle precedenze dovrà necessariamente avere degli elementi comuni.
È possibile classificare le modalità di interazione tra processi in base alla loro conoscenza o meno della presenza degli altri.
- processi totalmente ignari In questo caso i processi sono indipendenti e non sono stati progettati per lavorare assieme ma “evolvono” in un ambiente comune: interagiscono tra loro in competizione sulle risorse e si devono quindi sincronizzare. Questa situazione viene gestita dal sistema operativo, che deve essere arbitro della loro evoluzione effettuando la sincronizzazione all’accesso delle risorse ogni volta che i processi le richiedono.
ESEMPIO: Processi in competizione I processi sono in competizione per l’accesso a una stampante
oppure per l’utilizzo di una tabella di dati o di file che non può essere letta da un processo mentre viene modificata da un altro.
- processi indirettamente a conoscenza uno dell’altro è questa la situazione nella quale i processi sono a conoscenza dell’esistenza degli altri ma non ne conoscono il nome (o il ◀ PID ▶) e non possono comunicare direttamente tra loro ma devono cooperare per qualche motivo e possono scambiarsi i dati utilizzando risorse comuni, come aree di memoria condivisa. Il sistema operativo deve offrire dei meccanismi di sincronizzazione che rendano possibile la Cooperazione.
Esempio 2. Sia data la seguente espressione. Realizzare il grafo delle precedenze secondo il massimo
grado di parallelismo Espressione: (A * B) + (C + A) * ( D - C) Simulare la lettura delle variabili A,B,C,D.
Inizio
Leggi B
C + A
Y * Z
Fine
Leggi A Leggi C^ Leggi D
X^ A * B^ D^ -^ C
W
Y^ Z
X + W
ESERCIZIO 1. Data la seguente espressione algebrica (a + b) * (c + d) − e/f realizza il grafo
delle precedenze che esprima il massimo grado di parallelismo.
LA DESCRIZIONE DELLA CONCORRENZA L’esecuzione di un processo non sequenziale richiede un sistema specifico che permetta la codifica e l’esecuzione dei programmi, cioè necessita di: ◗ un elaboratore non sequenziale; ◗ un linguaggio di programmazione non sequenziale.
L’elaboratore non sequenziale è una macchina che deve essere in grado di eseguire più operazioni contemporaneamente e, come abbiamo detto, sostanzialmente questo si può ottenere in due modi differenti: ◗ architettura parallela, cioè sistemi multiprocessori; ◗ sistemi monoprocessori multiprogrammati.
Per scrivere programmi non sequenziali (o concorrenti) è inoltre necessario avere a disposizione dei particolari costrutti che permettano la descrizione delle attività parallele.
I linguaggi di programmazione concorrenti di alto livello contemplano nuove istruzioni come il costrutto fork-join e cobegin-coend, che permettono di dichiarare, creare, attivare e terminare processi sequenziali.
Le istruzioni fork e join furono introdotte nel 1963 per descrivere l’esecuzione parallela di segmenti di codice mediante la scomposizione di un processo in due processi e la successiva “riunione” in un unico processo.
In rifermento al grafo delle precedenze, la fork corrisponde alla biforcazione di un nodo in due rami: l’esecuzione di una fork coincide con la creazione di un processo che inizia la propria esecuzione in parallelo con quella del processo chiamante.
La join è l’istruzione che viene eseguita quando il processo creato tramite la fork, ha terminato il suo compito, si sincronizza c on il processo che lo ha generato e termina la sua esecuzione.
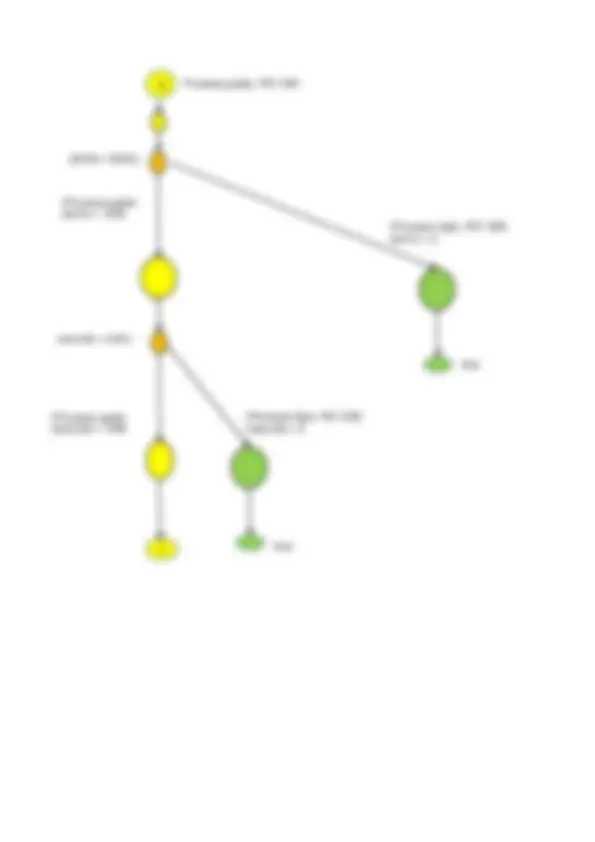
Il programma completo è rappresentato nel
diagramma a lato
Se ipotizziamo che ogni nodo sia una routine, possiamo meglio comprendere il funzionamento della istruzione fork con il seguente schema, dove sono messi in evidenza i due processi:
◗ P1 esegue la Routine A;
◗ con la fork attiva il processo 2 e in parallelo si eseguono la routine B e la routine C;
◗ P1 attende con la join la terminazione di P2;
◗ P1 esegue la routine C.
Fork
LA FORK-JOIN IN C
Il costrutto fork-join in linguaggio C: le istruzioni fork() e wait()
In Linux tutte le operazioni vengono svolte dai processi che possono generare ulteriori processi ( child process ): ogni processo ha un padre, tranne il processo di partenza, che in generale è init.
Se un processo figlio “perde” il padre per qualunque motivo diviene anch’esso figlio di init.
Le istruzioni fork e join di sono realizzate in linguaggio C mediante due funzioni: 1) Fork La sintassi dell’istruzione è la seguente: int fork();
che per essere eseguita necessita dell’inclusione della seguente libreria: # include <stdlib.h>
La funzione fork serve per creare un processo figlio identico al processo padre e tutti i segmenti del padre sono duplicati nel figlio al momento della fork. All’atto della creazione del nuovo processo il sistema assegna al processo figlio un PID. Il PID del processo figlio viene restituito come parametro al processo padre. Mentre la funzione ritorna 0 al processo figlio. In caso di errore, cioè nel caso in cui non si fosse creato un nuovo processo, viene ritornato -1. Per terminare l’esecuzione di un processo si richiama la funzione exit:
void exit(int stato);
2) Wait L’istruzione che permette ad un processo padre di attendere e leggere lo stato di terminazione del processo figlio è la system call wait() che ha la seguente sintassi:
int wait(int *retval);
Il valore di ritorno è il PID del processo figlio terminato, mentre il parametro retval è l’indirizzo della variabile che conterrà il valore di terminazione impostato dalla funzione exit() del figlio. Il valore contenuto dalla variabile viene letta mediante la macro
int WEXITSTATUS( retval ) [ Vedremo degli esempi .] Oltre alla funzione wait il linguaggio C mette a disposizione una istruzione più completa per attendere la terminazione di un processo, la funzione: int waitpid(int pid, int *retval, int opzioni);
che ha tre parametri: 1 pid: serve a indicare quale processo si deve aspettare, e può assumere valore: ◗ < - 1 ; ◗ - 1; ◗ 0 ; //in questa sintesi non specifichiamo il significato di questi valori che esulano dai nostri scopi ◗ > 0: specifica il valore di PID del processo figlio di cui il processo padre attende la terminazione.
2 retval: permette di memorizzare il valore di ritorno del processo che si sta attendendo; 3 opzioni: è utilizzato per specificare opzioni avanzate che esulano dai nostri scopi (per noi vale sempre 0).
Altre due utili funzioni sono: int getpid() la quale ritorna il PID del processo che la esegue e int getppid() che ritorna il PID del processo padre di chi la esegue.
ESEMPI ed ESERCIZI
Vediamo alcuni esempi dell’azione della funzione fork() Esempio/esercizio 1.
Programma fork1.c
Una possibile rappresentazione tramite il grafo delle precedenze per comprendere l’evoluzione dei flussi di esecuzione è:
A
primo = fork();
B (^) C
D
//Processo padre //primo = PID del //processo figlio
//Processo figlio //primo = 0
E
Start
End End
A rappresenta la sequenza: #include <stdio.h> #include <stdlib.h> int main(){ int primo; printf( "1) prima della fork \n" );
B e C rappresentano entrambi la sequenza: printf( " 2) dopo della fork \n" ); if (primo == 0) //ricordiamo che la fork() crea un processo figlio //identico al processo padre E rappresenta la sequenza: printf( " 3) sono il processo figlio\n" ); exit(1); //la condizione if (primo == 0) //è vera per il figlio e falsa per il padre D rappresenta la sequenza: else printf( " 3) sono il processo padre\n") ;