Scarica Python notes luiss rossi e più Appunti in PDF di Elementi di Informatica solo su Docsity!
Riddle of Guarini: during 16th century Guarini elaborate this game. He wants to find the faster sequences of move, according to the starting sequence, that ends in the second configuration. The Nodes represent the moves to reach the solution. The position b.2 is impossible to reach from everyone. Edges are the combination of position, like I am in c.1 and I go to b.3. Graphs is the union of Edges and Nodes. Choice a direction and move all the horses to reach the second position. You have to do minimum 16 moves. Algorithmic method:
- Problem definition: someone elaborate a problem to solve.
- Find a good mathematical model: for the specifical problem
- Find an algorithm: to solve the problem
- Code the recipe in a computer programming language: write the algorithm
- Test the program against syntactical error: in case of error go to line 3/4 and correct
- Test solution against sematic errors: in case of error go to line 2 and correct Example: Guarini
- Problem definition: change position of horses
- Mathematical model: octagon nodes
- Algorithm: chose a direction and for each node move to next position
- Program:
- Test syntactical errors:
- Test sematic errors: Example: the input is (^) √𝑥, the output is y, and the relation is y^2 =x. The solution is yi is an approtiamion of √𝑥. Guess a value of g, and if is close to x stop, if not update it. If you want to let x=
An algorithm is a sequence of simple action, so are elementary instruction. It is, also, a flow control mechanism to determine the next instruction, so he repeat the instruction in case of error. The algorithm stops conditions. In other words, the algorithm is a process to solve a problem by breaking it down into elementary calculations. They are a finite sequence of instructions, understandable by a performer (it can be an automatic tool), which describes how to accomplish a task. In a program we insert the algorithm, so we write (for example): Editor : Console : In a program we can write arithmetic and logic instruction, the conditions, that can be True or False, and storing instructions. The program is the interpreter of the algorithm. A value is just a name. The Control Unit is the control of the program, and between the Logic Unit, compose the CPU, that read from the memory the instruction and data, and next write the result in the memory. The memory is a place where write data. Programming languages: we ha 3 types : o (^) Symbols: some symbols are +, =, *, while, print, … o Syntax rules: describe how combine symbols to get instructions and programs o (^) Semantic rules: describe the meaning of symbols, instructions, and programs Types of errors: : we ha 3 types :
- Syntax error: if the program is not syntactically correct it does not run, and you receive an error message
- Runtime error: errors that occur only when the program runs, also called exceptions
- Semantic error: the program runs successfully, no errors are displayed, but the product result is incorrect, identifying semantic errors can be very difficult. Comments: they are a useful tool for inserting notes into your code in natural language. Commenting is good practice for improving the readability of your code for your own benefit or for others. Comments are ignored , that is, they are not interpreted, by Python. Comments begin with the # pound sign and end at the end of the line. You can insert a comment at the beginning of a line or at the end of a line of code. All text in the line following the # pound sign is ignored and has no effect on the program. The # character insert in a string does not identify a comment but rather the pound sign. Tools: anaconda program contains python is not python. In command Prompts we can run the python program using the function \ProgramData\Anaconda3\python.exe and using the key 'invio' we run the program and we can write the python's line, and if you want to exit write exit(). In python there is a Console , on the right, that run directly the line, and an Editor , on the left, that permit to write a lot of line programs. A type is a to show what type of variable we have write, for example we write in the Editor : and we saw in the Console : We can also directly write all in the Console :
Python solve the operation is first elevation to power, after, multiplications and divisions, and at least additions and subtractions. Exercise: drawing a square of a given size and modify the "draw square" example so that only the perimeter of the square is shown. Jupyter permit to visual python code if you click on New and after on Python
- Using heading you can use # to create a title. Markdown is contain between and <\i>. Between 2 Dollars you can insert different equations. You have to choose a title to the notebook. Functions: int functions convert a string in an integral. Other functions are print , input , len(). To define a new function, we have to use def empty_name ( variable ) : and down, with indentation, ||||insert the code of the function. After to recall that function you can use her empty_name , and every time run all that code. return statement permit to consider, after, the result of the definition, so we have an output value to use after (print just show the variable). Exercise: define a function that print the max variable. If we use an input different from 2 numbers, like a string and a number, we get TypeError because that operator is not supported. If we use 2 strings that is correct because he consider the alphabetic order and the output is the older (first) letter. So, a precede b, that precede c and the others. The same for A, B, C. According to the code a > A , and 0 > a. If the string symbol is the same the code consider the successive symbol. To saw 2 string or number are equal we use the operator ==. If we want to compare a and b only in the case a and be are int, we have to compare the check of a and b and saw that are ==0, (that because if you compare to int you don't know previously if is a number) with function type().
We can use logical operator, and , to combine both operation. Other logical operators are or , if only one is True, not , that show the opposite of and, or. Strings: we can do operations on strings. The len() function count the numbers of letters of strings. If we need to know the position of the n characters of a string we can use a[]. The first position is 0 or - len() and the last is len()- 1 or - 1. +---+---+---+---+---+---+ | P | y | t | h | o | n | +---+---+---+---+---+---+ 0 1 2 3 4 5
- 6 - 5 - 4 - 3 - 2 - 1 Exercise: count the numbers of vocal in the string. A string's propriety is that, string are object that can't modify, it is a TypeError. If we want to modify the string, we have to create a new string with the characters that we want. We use ord('') and the result is a number because show the position of the character in table Unicode, and we use chr() that show the character of the position in table Unicode. The maximum is 111412. We can compute that. The output is D. To know if a character is or not a consonant, we can use that code. We can print a part of a string with a[i:j] , and in that we have to insert the position that we can print, from i to j, but j is not included. If the i is omitted he print from the position 0, and if the j is omitted, he print to last position.
We can use len() to know the numbers of item in the list. We can use [ position ] to know what item is in that position. We can use [:] to print from an item to another item. The position goes to 0 from n- 1. If we use [:5] we print from position 0 to 5, and if we use [3:] we print from position 3 to the last one. We can count also from last position starting to - 1 form - n. We can create a new list if we sum 2 lists. List operations: portions of the list can be accessed in the same way as strings, either by indexing the item, or by slicing with two indexes separated by :. The length of a list, the number of its elements, is provided by the function len(). Lists also support concatenation. You can test an item's membership in the list by using the in operator. There are some methods , that are specific function to use with specific list. .append() function that add a new item at the end of the initial list, not create a new list. .insert(,”) : inserts a new item at a given position. .index() : returns where a given item appears. .pop() : removes the last item in the list or the item at the specified location. .remove() : removes a given item from the list. .reverse() : returns items in opposite order. .sort() : returns items sequentially. del a[] : delete one or more element in a list. str() function transform the list t in a string. Range: the range function creates a list of consecutive integers. The range function has two arguments and returns a list that contains all integers from the first (included) through the second (excluded). If the first argument is not specified, the list will start at number 0. Exercise: Write a function that takes two strings a and b in input and, in the case all chars of b are contained in a in the same order they appear in b, prints a and b on two lines so that the chars of b are vertically aligned to the corresponding characters of a. If n and m are, respectively, the size of a and b and a≥b then the cost of the function chr_align() is linear in n in the worst case because the while block can be executed n times and the cost of a single run is constant. We can change a character in a string, that will be our output.
Calculate the computational cost of this functions. Is it the same? The first solution calculates the print function, the second do a calculation, but in the second case we have different operation. So that strings are immutable, and we have to create a new string, that have more costs. When size of a is close to n, we have to run a part of the code, and the cost of this instruction is not constant, because we have to create a new string to use, and that is more or less equal of the data we use, so is similar to n. So t=t+a[i] have cost not constant, that depends from input. The function maintains a string t that is updated on each iteration of the while loop. Since the update requires the creation of a new string of increasing size, this requires a linear number of operations that, in the worst case, can be repeated n times. Therefore, the overall cost of the function turns out to be quadratic in n , n^2. Consider the case a=b and |a|=|b|=n. When i=0 the block after while is a constant number because we have just to create a symbol in t. So when the cost of i=0 the cost is 1. When i=1 the cost is 2. When i=k the cost is k+1. When i=n- 1 the cost is n. So, the total cost of the while loop is the sum of all the cost value, that is n 2 (n^ +^1 ).^ The^ cost is similar to n^2 , so is quadratic. If we know the solution, we have to analyse that and we have to create a code that is the cheapest solution, in that case, that we can write. Is it possible to improve this solution? We can use list. t must be converted into a string before returning in output. The str() converts its input in a string. The cost of this function is linear. All the operation in while block require a constant number of step so have cost constant. In some python interpreter that function doesn’t work. So, we can use the string ''.join() , in the editor change return str(t) in return ‘’.join(t).
A further execution of the for loop move the maximum of a[:-1] (the "second" maximum of a) in the penultimate position of a. That work only in the case the maximum is in the position 0 or 1. The bubbolesort algorithm moving the maximum at the end of the list, if repeat n-1 times he orders the number from minimum to maximum. After j steps the last j positions of a contain the larger j items a in increasing order. They are already in their final position so it is useless compare pairs in positions ≥n-j. break close the loop. We can introduce a new parameter, so if he is in place is true, he is sort. Function parameter with a default value that will be used in the case the function is called without that argument. Sometimes n-1 steps are not necessary like for this example. We need a first step to move the maximum at the end of a and an additional step that verifies the sorting.
To saw if two variables are equal, we can use id() function. They are equal only in the case they are the same variable, not if they have the same value in the list, also if are in the same position. When j=0 the internal for loop run a linear number of instructions, n- 1 , so is the operation in the internal for loop. When j=1 the operation of the internal for loop run is n- 2. When j=c the operation of the internal for loop run is n-c. When j=n the operation of the internal for loop run is 1. If we want to sort according to another criterion, we can change the test. Function parameter with a default value that will be used in the case the function is called without that argument. In this case we sort the strings by increasing lengths. The function that attributes the value of the elements to be used in the test, that can be a function parameter. The identity function allows you to use the element's own values. The identity function take an input a value and return the same value. The identity function can be use as default value for the parameter f.
To assign to 2 variable an item each one we can write the name value, and after the equal we can write 2 items. The number of variable must be the same of the item. This is an unpacking. We can also assign 2 complex item. We can compare the variable. He compare the first item in the variables, but if they are equal, he compare the second item. He print True or False. If the size of the variable is different he consider bigger the value in the longest variable, if he arrive to compare that item. We can see Tuple as vector. We can create a list with a set of Tuple, and in that we can use the operation of the lists. Like index operator. We can assign a name of the Tuple, and order, in the console, that in the way we insert. The first character is the column, and the second is the line. We need to know how many place are, so the last position, and after that go to the successive line. So, first of all, we define the last column, that is the maximum plus one of the item. We define C like the maximum between first components, and R is the maximum between the second components. The goal is to write a program that uses the console as a two- dimensional space where to represent the points where the position (0,0) is the top left point. Computing the bounding box of P.
#get all the coordained for the item. Print from the left from the right and from the up to the bottom. We have to verify if P contain a point in that order. Consider all the point in the list. We fix the problem, that we find the point in P and name of this point is printed in the console and is it for all the point in P that is not correct, because we have to run the print line. We need a blank. A problem is that the blank and the single letters represent a line. To fix this, we have to use end=''. We have another problem that all symbols are in the same line. We have to go to the next line when we finish a loop. So, we insert print() to go in the next line. The list P is a list of points in a 2-d space. The first two components are the x and y coordinates, the third component (a letter) is the name of the point. The goal is to write a program that uses the console as a two-dimensional space where to represent the points where the position (0,0) is the top left point. We can also do in a different way. We can do an unpacking operation even in the for loop. We write a characters, col for the column, row for the line and n is the name. If the number of point are n, so we have col for column, row for the line and name is the name. The computational cost are the multiplication of nRC, so if R and C tend to n, the cost is n^3 , so it is cubic. To improve this cost we have to modify P. We can arrange assignment in P. If we sorted the item in the list, we could provide a faster algorithm because you follow a shorter order, so we can consider from the first to the last and at the same time we can control the character in the position of the rectangle. R+1 and C+1 are, respectively, the number of rows and columns of the rectangle that contains all points in P. Let us assume P contains n items. For each point in the rectangle of size R×C the algorithm travels all items of P of size n. This requires R×C×n. Assuming R and C linear in n, the cost of the algorithm is order of n^3.
If we consider to swich the value in the tuple, we can use a key function. We have to create the most efficient function. Considering a searching problem, that is define from a set of items, and have particular items. Given a list a (but also other data structures containing more items) and a value k answer true if k is in a. More preciselly, whether a contains at least an item equal k. To saw if k is in a, use the function in. The cost is linear like the number in a. We can sort() a. If a is sorted we can provide a sub-linear time algorithm called Binary search. We want to find a key in a, and a is sorted. We want to design a cost that is less than the linear one. We do k<a median value, k<c- 1 , and k>a median value, k>c+1. We iterate from o to c- 1 , and to c+1 to n- 1. A float number cannot is an index. We can use int() function to convert it in a integer. While true means forever. If k not in a, never end. We the sequence is empty we have to return false, we have check that. When r=l to define that we want not empty.
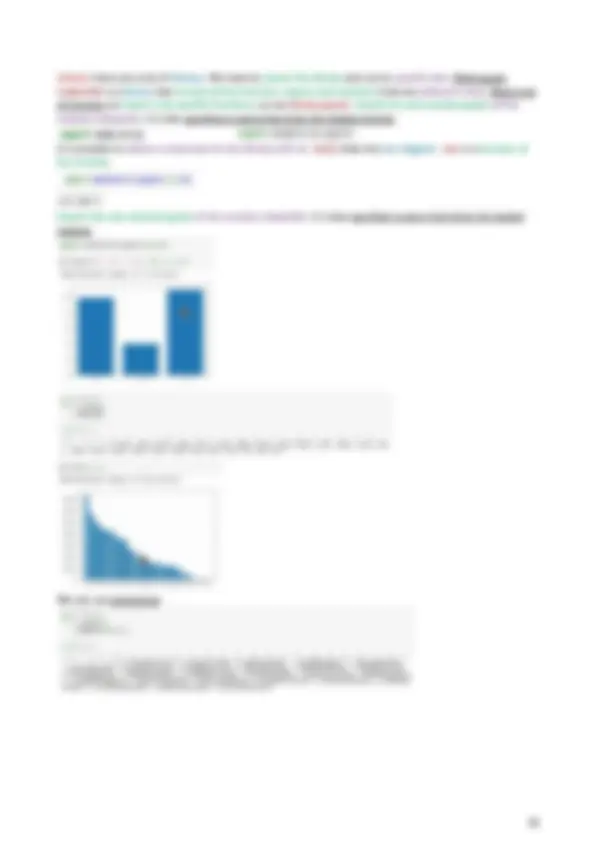
The computational cost deepens. The cost in the in while function is C, so the cost is t*C. In a general step of while loop the searching space is the subsist bounded by the indices l and r (at the first step this covers the whole list). If k is in the middle of this subsist the algorithm ends returning success, otherwise the searching space is updated and the algorithm will iterate on the left of the middle point, in the case k is smaller than the middle point, or on the right. At each step the searching space (the subsist) becomes smaller and smaller, in the case k∉a this will become empty (r < l). The computational cost is logarithmic because the algorithm will remove the step of the original items. Assume that we have 2 steps of items in 2 lists. We want to compute c=a∩b, so the intersection of a and b. For each item x in a that we can print if x is in b, so use the function .append(). The block of the while loop (lines 6--12) contains a constant number of elementary instruction so its computational cost i constant. Let t be the number of times the test in the while condition is true (in the worst case), the computational cost of the function is order of t. Computing t. In the worst case the size of the searching space (the interval between l and r) will bacame a small constant c , so t will be the number of steps before r will become close to l. The size of the space is halved with each step so at step 1 the size of the searching space is n= len(a). At step 2 is n/2. At step 3 is n/4 and in general at step i it is equal to n/2(i−1). At step t, the last one, this is equal to 𝑛 2 𝑡−^1 that is 2 𝑡−^1 ≈ c𝑛^ ⇒ t − 1 ≈ log 2 (c𝑛). In conclusion, the computational cost of the binary search algorithm is order of log(n) in the worst case. The cost of c is linear. Assuming that |a|,|b|≈n, the cost is n^2. If b is sort, the operation if x in b have a logarithmic cost.
We can use len() to know how many key and value (not the sum) are in the dictionary. We can also use .key() or .value() to know the key or the value. We can return the size of the dictionary, that is the number of pairs. We can use in to show if an element is in dictionary, or key or value. These methods return the list set of keys and the set of values as lists. The in statement returns True if the item is a key of the dictionary. Try to design a function that take an input of dictionary an object and that function in the case of the object is a key return a value, otherwise returns False. The method of dictionary .get return the value. The get() method works as follows, so in case its input is a key of the dictionary it returns the corresponding value, otherwise returns None. It is also possible define a second parameter that will be returned in the case the first one is not a key of the dictionary. All that operation requires a computational cost. The computational cost of the previous operations (add a new pair, updating, deleting, len(), get() and in) can be assumed constant. More precisely it is true that, assuming n be len(d), a sequence of n operations over d requires linear cost (in n), then it follows that, averaging over n, the cost of a single operation is constant. Is it possible to design a new algorithm for intersection problem with a linear cost? Exercise: a is a list containing numbers and strings, write a program that sorts a so that: ▪ strings precede numbers ▪ numbers are sorted in ascending order ▪ strings are sorted by increasing lengths
The first solution In n is the size of the list, the computational cost of this solution is order of n(log(n)) but requires the creation of two auxiliary lists. Is it possible to create a temporary list? The second solution By using f as key function in the sort method all the strings will precede all the numbers (because in case of strings the first item of the return value is smaller). In case of tie in the first item of the output pair are used the second items, that is the length of the strings or the value of the number.