



Sfide dell’analisi linguistica computazionale
nei contesti figurati
COMPRENSIONE
AUTOMATICA E
AMBIGUITA’
SEMANTICA
Carmela Cristiano






Studia grazie alle numerose risorse presenti su Docsity

Guadagna punti aiutando altri studenti oppure acquistali con un piano Premium

Prepara i tuoi esami
Studia grazie alle numerose risorse presenti su Docsity
Prepara i tuoi esami con i documenti condivisi da studenti come te su Docsity
Trova i documenti specifici per gli esami della tua università
Preparati con lezioni e prove svolte basate sui programmi universitari!
Rispondi a reali domande d’esame e scopri la tua preparazione
Riassumi i tuoi documenti, fagli domande, convertili in quiz e mappe concettuali
Studia con prove svolte, tesine e consigli utili
Togliti ogni dubbio leggendo le risposte alle domande fatte da altri studenti come te
Esplora i documenti più scaricati per gli argomenti di studio più popolari
Ottieni i punti per scaricare
Guadagna punti aiutando altri studenti oppure acquistali con un piano Premium
ricerca basata sul manuale di linguistica computazionale
Tipologia: Schemi e mappe concettuali
1 / 10

Questa pagina non è visibile nell’anteprima
Non perderti parti importanti!
Sfide dell’analisi linguistica computazionale nei contesti figurati
Carmela Cristiano
L’elaborato propone un esperimento di analisi attraverso l’utilizzo del software di linguistica computazionale READ-IT, applicato a testi provenienti da un contesto digitale contemporaneo: contenuti pubblicati sulla piattaforma Twitter, caratterizzati da una scrittura riflessiva ma spesso attraversata da linguaggio generazionale, ambiguità semantiche ed espressioni figurate.
Analizzare in modo critico come il sistema reagisce quando si confronta con strutture linguistiche non convenzionali. L’attenzione si concentra sulla possibile frattura tra: il riconoscimento automatico degli elementi formali del testo la reale costruzione del significato
Quali sono i confini dell’elaborazione automatica del linguaggio naturale?
DAL TESTO ALL’ALGORITMO
SEGMENTAZIONE AUTOMATICA DEL TESTO IN FRASI : errata in tutti i casi proposti.
Il sistema non è riuscito a disambiguare i sensi.
TOKENIZZAZIONE Questo task risulta essere il più efficace di tutti forse perché non richiede alcuna interpretazione del significato ma si limita ad operazioni formali sul testo.
Nonostante ciò nel caso di “ICE.” non ha riconosciuto il punto come segno di punteggiatura ma lo ha analizzato come appartenente alla sigla.
PoS Tagging , riconoscimento automatico delle parti del discorso.
Ambiguità : il modello analizza “finito” come verbo participio passato, ma in questo caso ha funzione di aggettivo
READ-IT è progettato per la valutazione della leggibilità di testi in lingua italiana. Sebbene l’interfaccia consenta la selezione tra Italiano e Inglese, il tentativo di analizzare un tweet in lingua inglese ha restituito il messaggio: “Connessione al server non disponibile”. Questo suggerisce che l’elaborazione sia supportata esclusivamente per l’italiano.
“m” → verbo feeling → verbo “rn” (right now) → due token differenti “latino” → analizzato come parola italiana
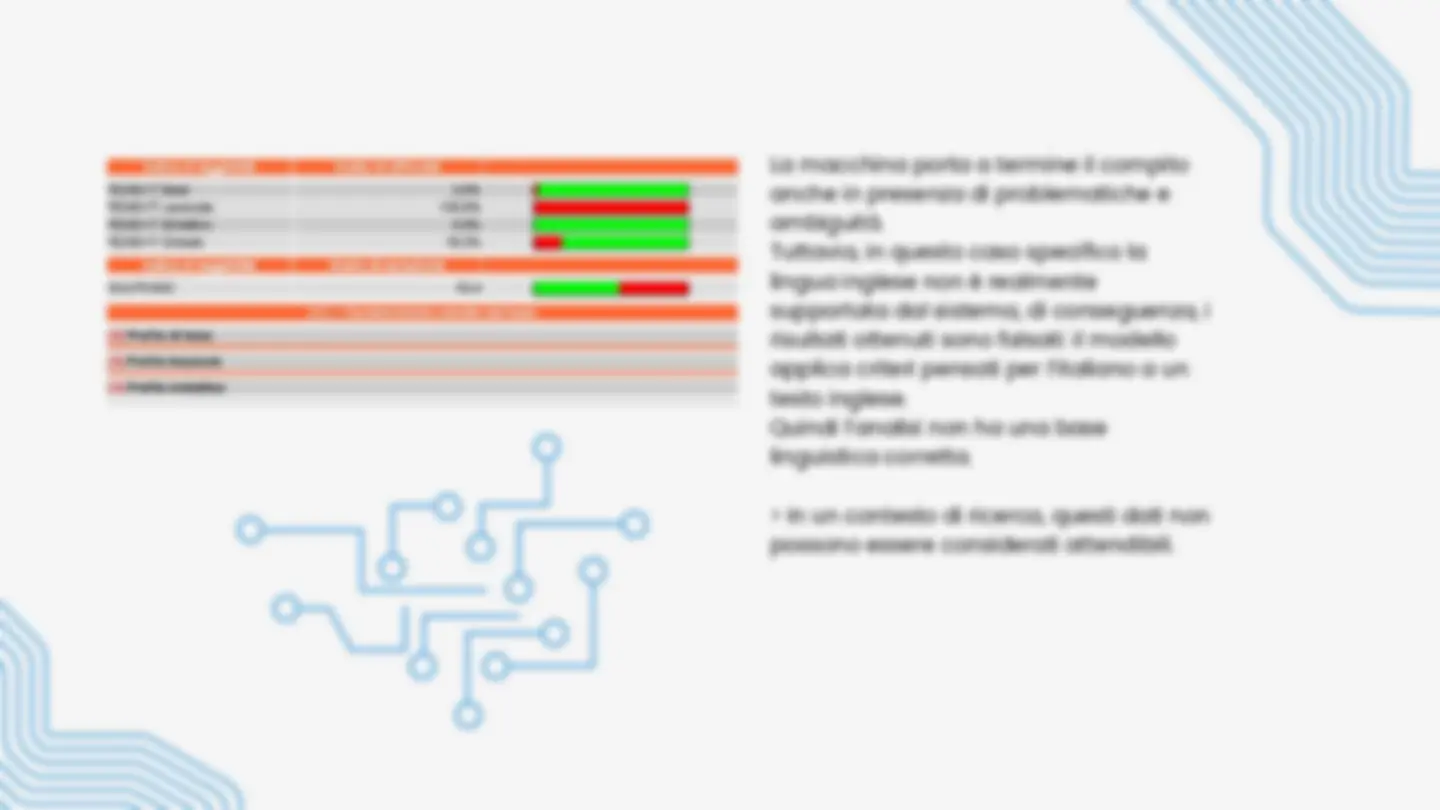
La macchina porta a termine il compito anche in presenza di problematiche e ambiguità. Tuttavia, in questo caso specifico la lingua inglese non è realmente supportata dal sistema, di conseguenza, i risultati ottenuti sono falsati: il modello applica criteri pensati per l’italiano a un testo inglese. Quindi l’analisi non ha una base linguistica corretta.
> In un contesto di ricerca, questi dati non possono essere considerati attendibili.