Scarica Trascrizioni Machine Learning e più Sbobinature in PDF di Machine learning solo su Docsity!
Trascrizioni Machine Learning
Gennaio 2023 - Leonardo Pera 681HHHINGINFOR
Lezione 1 - Introduzione a Big Data Analytics and Visualization Big Data Analytics: il fenomeno di Big Data Analytics è un fenomeno di mercato, uno dei player più importanti è SAS (servizi online e software multipiattaforma per analytics) tramite la sua piattaforma Viya. Questi analytics sono di supporto alle decisioni aziendali e sull’aspetto dell’automazione Un economista dice: “l’economia definita dai dati analitici è il riflesso di un mondo che cambia, dove i dati non possono esistere senza la loro funzione analitica”. Gli elementi minimi da tenere conto sono i dati, la messa in campo della piattaforma e la fascia di tools definita come “discovery”. Sui dati grazie alla piattaforma e attraverso analisi si scoprono nuovi pattern e nuove informazioni. I dati vanno raccolti sia che essi siano grandi o piccoli di grandezza mediante IoT e/o sistemi aziendali dedicati (CRM/ERP). I dati si raccolgono in Data Storage e vengono poi elaborati mediante la costruzione di un modello che viene eseguito e monitorato. Gli analitici vanno studiati “al volo”, la post-elaborazione non porta a dei risultati attendibili. Bisogna definire un linguaggio di programmazione e medianti quali tecniche di analitici si possono definire delle informazioni. Il tema del deployment va poi elaborato assieme allo sviluppo perchè non possiamo immaginare di elaborare e prendere dati casualmente, ma bisogna avere delle pipeline che generi delle risposte automatiche ed essere leggibili in forma di report o dashboard. L’ultimo tema è dei “talenti”, questo è un lavoro di team. Il tema del controllo va effettuato sui dati (data governance), sul modello usato (model governance) studiando il bias del modello stesso, perchè i modelli possono portare ad esclusioni di natura etica. Va poi controllato il deployment e infine la sicurezza e la privacy dei dati che viene basata sul GDPR del 2018. I dati si accumulano e non vengono mai cestinati, nel giro di 10 giorni mediante questi si duplicano e si ha bisogno di scalare le risorse, diventando grandi di pari passo alla necessità. L’ingegneria serve a rendere sistemi scalabili man mano che il fattore di scala aumenti. Introduzione alla data science: la data science è un modello logico. Per definire efficacemente bisogna definire il ruolo importante del data scientist: un data scientist è coinvolto negli aspetti algoritmici per sviluppare modelli dai dati. Un modello è un modo per guadagnare nuove informazioni da dati mai visti prima. Questo è fondamentale: in caso di analisi di dati passati non abbiamo bisogno del modello. Il modello deve provare a capire dati che arriveranno in futuro per renderli subito leggibili e nella tradizione della scienza occidentale il modello è quindi una ipotesi che verrà verificato. Possiamo dire che il data science è un ambito cross-funzionale che va dalla statistica, alla computer science, ai domini di business, capacità matematiche e di analisi logica dei problemi. Nel tempo sono nati altri aspetti della data science come il Data Enginnering e il DevOps. Il DevOps indica “sviluppo” e “operazioni” nello stesso momento ed è un modo di sviluppo IT che diventa essenziale su come evolve il lavoro del data scientist. Il processo KDD (estrazione conoscenza dai dati di base), secondo una catena del valore, ci conduce alla conoscenza come l’estratto più importante, una sorta di validazione di teoria del modello. Vanno selezionati i dati, pre-processati, trasformati, estratto un pattern e definita la conoscenza. Questo schema, vecchio di 30 anni, contiene informazioni utili tuttora. Possiamo quindi definire un tipico processo di data science in questi passi:
- Formulazione di ipotesi matematiche o in un linguaggio script dopo l’esplorazione dei dati;
- Caricamento e trasformazione dei dati importanti;
- Capire quali sono gli estratti (o “feature”) dei dati che sintetizzano i dati;
- Creare modello (ipotesi);
- Valutare correttezza modello (testing ipotesi);
- Lanciare in esecuzione il modello;
- Monitorare il modello verificando le performance; Il lavoratore in ambito Data Science può analizzare ciò che accade in organizzazione: gli analisti di business (business significa l’attività svolta rivolta ad un obiettivo specifico) capiscono le esigenze e insieme ai Data Scientists studiano e analizzano i dati. Infine pubblicano i loro risultati a favore degli sviluppatori, che trasformano in codice informativo gli operativi e le procedure e a favore dei data engineers che cercano dati e li elaborano in una pipeline senza discontinuità per nutrire i modelli stabiliti. Si arrivano quindi ai DevOps ovvero persone dell’IT che svolgono funzioni aziendali e che sono sempre in evoluzione. Panorama tecnologico del Data Science: abbiamo bisogno di definire gli artefatti per ogni task e di standardizzare le procedure di un progetto. Infine dobbiamo sapere quali sono le infrastrutture e le risorse che abbiamo a disposizione per un progetto simile. Microsoft Azure, leader in questo ambito, è una piattaforma online cloud fuori dal paradigma della rete locale aziendale e di infrastrutture in-house. I linguaggi di programmazione per Data Science sono SQL, R, Python, Ruby e Scala. Ci sono ambienti di sviluppo integrato (IDE: SAS e Azure), lo strumento dei Notebooks (Apache Zeppelin, RStudio, Jupyter) che sviluppano la condivisione del codice e commenti in una maniera molto leggibile. Infine abbiamo già citato il cloud computing come AWS, Google Cloud, Azure, IBM Bluemix per quanto riguarda risorse e infrastrutture. I tools servono a sperimentare, creare attività riproducibili e per la condivisione e la collaborazione con i teams. Questi tools sono disponibili come computazioni on-demand, ambiti standardizzati in ambienti esistenti e garantire il controllo sugli accessi ai dati. Per mettere in produzione i processi si richiede una automazione di task ripetitivi (upload codici, upgrade procedure sui server, discovery dati) bisogna poi trovare il modo per monitorare le performance sui dati e allo studio di un miglioramento costante delle procedure. Lezione 2 - Introduzione al machine learning Introduzione al Machine Learning: alcune citazioni dall’ambito accademico dicono:
- Bill Gates: “un cambiamento epocale nella machine learning varrebbe 10 volte Microsoft”;
- Tony Tether, DARPA: “il machine learning è il nuovo Internet” ovvero una innovazione globale;
- (^) John Hennessy, Standford: “Il machine learning è il nuovo argomento caldo”;
- Prabhakar Raghavan, Yahoo: “Il web ranking oggi è soprattutto un argomento di ML”; Una definizione operativa data da Tom Mitchell definisce il ML come: “il campo del ML ha a che fare soprattutto con la domanda di costruire programmi per il computer che automaticamente migliorano con l’esperienza”. Oggi il programmatore scrive il programma e man mano lo migliora in fase operativa. Cos’è quindi il Machine Learning? E’ automatizzare programmi di computer creando tools di automazione spingendo il computer ad autoprogrammarsi e che attualmente la scrittura di software è il collo di bottiglia dell’automazione, quindi abbandonando la figura del programmatore e al suo posto lasciare che i dati facciano il proprio lavoro.
- (^) Classificazione: i dati sono pre-assegnati ad una classe e vogliamo capire che classe sia. Ad esempio il concetto della mail spam;
- Regressione : collezione di dati numerici e dalla collezione di dati passati si tenta di predire il corso di quelli futuri. Molto usato in ambito finanziario come gli stock prices e i costi delle case;
- (^) Clustering : i dati non sono etichettati ma possiamo dividerli in gruppi qualitativi diversi e altri misure di strutture inerenti nei dati. Ad esempio un dato in due stati diversi può dare due risultati diversi in base allo stato in cui si trova.
- Rule Extraction : estrazione di regole in forma IF-THEN; Approcci di apprendimento: come possiamo capire la struttura dei dati? Se abbiamo un poliedro possiamo spacchettare il poliedro in un altro modo e a rappresentarlo in un altro modo. In generale la struttura di un ML propone un modo per apprendere parametri di un modello che viene inserito e codificato nell’agente. Le tre fasi necessarie sono rappresentazione, valutazione e ottimizzazione.
Dai dati di training sono estratti dei vettori “features” e mediante un algoritmo di ML si trasferisce un modello parametrizzato concludendo l’intervallo di training. Nell’intervallo operativo, il modello deve essere pienamente efficace e dare una performance significativa e soddisfacente. I dati vengono quindi smistati in vettori “features” che inseriti nel modello vengono rappresentati e lavorati. Il metodo unsupervised è del tutto simile al precedente ma vengono definite tre zone precise: l’algoritmo ML è l’ottimizzazione, la creazione dei “feature vectors” sono la rappresentazione e l’output è la valutazione. Il training è il processo che consente al sistema di apprendere o di cambiare i suoi parametri più interni per ottimizzare la performance per svolgere l’attività. Esiste la regola del “ no free lunch ” ovvero che il set di dati di training e di testing devono venire dalla stessa distribuzione svolgendo alcune assunzioni (bias). Il sistema di dati universale è composto da due gruppi diversi: estraendo dei dati abbiamo un training set, ovvero un set osservato. In operazione, nell’utilizzo pratico, viene dato il testing set ovvero quello su cui noi andremo a verificare la performance, ovviamente peggiore del training set. I sistemi in test non sono comparabili con i sistemi in esercizio. I dati in acquisizione differiscono come:
- Supervised learning : si distinguono i gruppi raggruppando per semantica;
- Unsupervised learning : si distinguono i gruppi senza sapere le loro semantiche;
- Semi-supervised learning : non tutti i gruppi sono distinti correttamente ma il sistema deve comprendere come separarli correttamente; Il successo del ML dipende anche dall’algoritmo di apprendimento che controllano la ricerca per trovare e costruire strutture di conoscenza espresse da un modello. Gli algoritmi di ML devono estrarre informazioni utili da esempi che vengono forniti. Ci sono diversi fattori che dipendono dalle performance:
- Tipo di training svolto;
- La forma e la condizione di ogni conoscenza di sfondo che viene fornita al sistema;
- Il tipo di feedback provveduto;
- L’algoritmo di apprendimento usato; Due fattori importanti per definire le performance sono il modello e l’ottimizzazione. Bisogna definire il Feature Space : proprietà con i quali possiamo descrivere un problema; Bisogna definire una ipotesi : una funzione con la quale dare etichette ai possibili dati sconosciuti; Un insieme di più ipotesi e legate è detto Spazio delle Ipotesi. Altri termini:
• Esempio di training : che deve essere nella forma 𝑥, 𝑓(𝑥);
• Funzione target : 𝑓(𝑥);
• Ipotesi : funzione ℎ che può essere ritenuta simile a 𝑓 ;
• Concetto : funzione booleana. Un esempio è 𝑓(𝑥) = 1 chiamato come esempio positivo mentre
per 𝑓(𝑥) = 0 si hanno esempi negativi;
Il valore 𝜃𝑗 è uguale al valore 𝜃𝑗 di prova a cui viene sommato un termine. In pratica quando bisogna minimizzare 𝑗 si tenta un meccanismo interattivo dove ogni volta il parametro si adegua con un 𝛼 < 1 e quando si arriva a una convergenza discreta allora 𝛼 = 0. Quando abbiamo esempi multipli con tante righe non possiamo agire in questo modo ma dobbiamo usare un algoritmo che itera su tutti i possibili esempi. Allora la regola si amplia e assume importanza maggiore. 𝜃𝑗: = 𝜃𝑗 + 𝛼 ∑ 𝑖= 1 𝑚 (𝑦(𝑖)^ − ℎ𝜃(𝑥(𝑖)))𝑥𝑗 (𝑖) per ogni 𝑗 In questo caso non si tenta di risolvere contemporaneamente ma si svolge iterativamente per ogni elemento e singolo parametro. Questa regola è detta di batch gradient descent , ovvero variare il 𝜃 in base alla diminuzione della funzione costo e usando tutti i dati. Riprendiamo il problema: predire il costo della casa mediante due parametri. Nel training set avevamo dati e supponiamo anche una retta che è il valore ottimale. La funzione può presentare in questo caso un unico punto di minimo che viene scoperto con un numero finito di passi e da qualsiasi punto di parte corrisponde sempre al medesimo. Un altro tipo di regressione lineare comprende il stochastic gradient descent. La regola di update non contiene la sommatoria perchè possediamo un loop che richiama gli esempi uno alla volta. Loop { for i=1 to m {
𝜃𝑗: = 𝜃𝑗 + 𝛼(𝑦(𝑖)^ − ℎ𝜃(𝑥(𝑖)))𝑥𝑗
(𝑖) per ogni 𝑗 }} Arriveremo a una stima di 𝜃𝑗. Non consideriamo un calcolo fatto sugli esempi, questo tipo di operazione ci slega dalla dimensione del dataset. Questo approccio è il più diffuso perchè sebbene non dia garanzia di convergenza nel punto minimo esistente è più rapido non dipendendo dal numero di parametri. Formulazione generale: partiamo dalla definizione di due matrici. 𝑋 = 5 𝑥(+): 𝑥(.):
... 𝑥(,): 7 ∈ ℝ,;<^ 𝐲 = ⎣ ⎢ ⎢ ⎡ 𝑦(+) 𝑦(.) ... 𝑦(,)⎦ ⎥ ⎥ ⎤ ∈ ℝ, Abbiamo una matrice X ( design matrix ) che ogni riga corrisponde ad un esempio in una riga del database. Questa contiene ogni valore di input dal training set. Invece gli output li riportiamo come un vettore di m righe che contiene i valori target prelevati dal training set. Se stiamo in un sistema matriciale calcoliamo il gradiente esplicitamente: 𝛻𝜃𝐽(𝜃) = 𝛻𝜃 !(ℎ𝜃(𝑥(𝑖)) − 𝑦(𝑖)) 2 " = 𝑋 𝑇 𝑋𝜃 − 𝑋 𝑇 𝐲
ovvero il prodotto della matrice design trasposta moltiplicata per la matrice design stessa e il vettore 𝜃 meno la trasposta di X per il vettore 𝑦. Possiamo minimizzare il calcolo per trovare i punti stazionari e mettiamo la derivata pari a zero:
𝑇
𝑇
Questa è una formulazione importante dalla quali possiamo definire le equazioni normali: 𝜃 = (𝑋:𝑋)^5 +𝑋:𝐲 In ambito big data, l’inverso della matrice è dispendiosa a livello computazionale quindi si tende a non farlo. Per natura probabilistica è meglio usare altri tipi di algoritmi per non rifare il calcolo completamente. Interpretazione probabilistica: le variabili target e gli input hanno una relazione stocastica e bisogna inserire un termine chiamato rumore 𝜀(𝑖)^ che è una variabile randomica con una media zero e distribuzione gaussiana: 𝜀(𝑖)^ ∼ 𝑁( 0 , 𝜎^2 ) con media 0 e varianza 𝜎^2. 𝑦(𝑖)^ = 𝜃 𝑇 𝑥(𝑖)^ + 𝜀(𝑖) Quindi possiamo esprimere l’uscita come una regressione lineare con i parametri in ingresso e una somma randomica di rumore. Tutti i rumori sono indipendenti dall’altro statisticamente; Calcoliamo la probabilità dell’uscita 𝑦 i-esima dato l’ingresso x i-esimo e i parametri 𝜃.
$%(& (")%'$(("))% )%^ + Nel meccanismo di stima della massima verosimiglianza definiamo: 𝐿(𝜃) = 𝐿(𝜃; 𝑋, 𝐲) = prob(𝐲|𝑋; 𝜃) Il meccanismo di massima verosimiglianza definisce che scelto un 𝜃 dobbiamo rendere la probabilità dei dati più alta possibile cioè in modo da massimizzare la verosimiglianza con l’uscita. Elaboriamo la funzione di verosimiglianza: 𝐿(𝜃) = 𝐿(𝜃; 𝑋, 𝐲) = prob(𝐲|𝑋; 𝜃) = ∏ )+ , prob(𝑦())|𝑥()); 𝜃) Se utilizziamo già le conoscenze regresse abbiamo la soluzione. La soluzione la esprimiamo per il logaritmo di 𝐿(𝜃). log𝐿(𝜃) = 𝑚log 1 √^2 𝜋𝜎^ − 1 𝜎. 1 2 ∑ )*+ , (𝑦())^ − 𝜃:𝑥())). Se noi utilizziamo il logaritmo abbiamo una forte semplificazione con due termini: lo scarto quadratico tra uscita target e uscita calcolata con funzione ipotesi e una costante. Ci siamo accorti che quel termine è la funzione di costo: log𝐿(𝜃) ≃ 𝐽(𝜃). La regressione a minimi quadrati corrisponde al principio di massima verosimiglianza ed entrambi conducono allo stesso valore di parametri 𝜃. Confermiamo quindi la validità delle equazioni normali.
Qui abbiamo per ogni fattore un componente del training set. Se sostituiamo la formulazione della probabilità del campione i-esimo nella classificazione binaria otteniamo:
prob(𝑦())|𝑥()); 𝜃) = @ℎ-(𝑥())) A
6 (%)
@ 1 − ℎ-(𝑥())) A
- 56 (%) Passando al logaritmo sostituiamo la fattorizzazione con una somma, questa espressione si deriva algebricamente:
log𝐿(𝜃) = ∑
&'( )
0 𝑦(&)logℎ* 2 𝑥(&) 4 + ( 1 − 𝑦(&))log 71 − ℎ* 2 𝑥(&) 489
Per un solo esempio, nel caso avessimo una sola riga, la derivata si riduce a:
∂log𝐿(𝜃)
Il loop viene svolto sulle righe della tabella e per ogni riga calcoliamo la variazione del 𝜃.
Loop { for i=1 to m {
𝑖= 1 𝑚
!𝑦(𝑖)^ − ℎ𝜃#𝑥(𝑖)$" 𝑥𝑗
(𝑖) }}
Simile al caso del LMS Update ma non uguale perchè ℎ𝜃(𝑥(𝑖)) è una funzione non lineare di
𝑇
Modelli lineari generalizzati: abbiamo visto:
- La regressione lineare dove si è introdotto il principio della variabile stocastica, l’uscita è vista come una variabile aleatoria condizionata dai parametri e dall’input. Questa variabile si
comporta come una distribuzione gaussiana con media 𝜇 e varianza 𝜎^2 ;
- La classificazione dove la variabile aleatoria di uscita si comporta come una variabile
Bernoulliana con media 𝜙.
Ci sono molti casi come i due citati che rientrano nella famiglia dei Modelli Lineari Generalizzati. Questa famiglia offre sviluppi eleganti matematicamente per trattare problemi di machine learning complessi. Ci concentriamo sulla famiglia esponenziale: una classe di distribuzione può essere
definita esponenziale e può essere scritta come: prob(𝑦; 𝜂) = 𝑏(𝑦)𝑒(=
':( 6 ) 5 >(=)) . La classe di distribuzioni che costituisce la famiglia esponenziale può essere scritta nella forma: la
probabilità dell’uscita y parametrizzata attraverso il parametro 𝜂 ha l’espressione riportata in
figura.
𝜂 si dice parametro canonico (o naturale) mentre la funzione b dipende dal valore dell’uscita y.
C’è di nuovo il parametro canonico come prodotto tra la sua trasposta ed un’altra funzione di y T
detta statistica sufficiente. 𝛼(𝜂) è detta funzione di Log partizione.
GLM – distribuzione di Bernoulli: è una funzione all’interno della famiglia esponenziale ma va
dimostrato. Partiamo dal concetto di Bernoulli con media “𝜙” e specifichiamo la distribuzione sopra
il valore di uscita y nell’insieme {0, 1} in modo che possa apparire nella forma di famiglia esponenziale:
prob(𝑦 = 1 ; 𝜙) = 𝜙
prob(𝑦 = 0 ; 𝜙) = 1 − 𝜙
Da questa espressione traiamo la seguente che include entrambi i casi: prob(𝑦; 𝜙) = 𝜙(^ ( 1 − 𝜙))(^ = 𝑒 +,-. + (^) )// 0 ( 1 ,-.()/) 0 La scriviamo in forma esponenziale mettendo exp fuori e log dentro. Nell’esponenziale abbiamo 2 termini importanti: prob(𝑦; 𝜂) = 𝑏(𝑦)𝑒(^2 " 3 (() 4 ( 2 )) = 1 𝑒 (,-. (^5) $#%# 6 ( 1 ,-.()*/)) . GLM – distribuzione Gaussiana: assumiamo che la varianza sia 1 quindi scriviamo:
prob(𝑦; 𝜇) =
? 5
.(^65 @)
A
? 5
.^6 # A
?@6 5
.@
A
Possiamo quindi scriverla come: prob(𝑦; 𝜂) = 𝑏(𝑦)𝑒(=
':( 6 ) 5 B(=))
. √.D
? 5 7 #^6
A
?@6 5 7 #@
A
Altri metodi sono: multinomiale, poisson, gamma e esponenziale, beta e di Dirichlet. Abbiamo un problema: costruire un modello che stimi il numero di clienti che arrivano nel nostro negozio (o sito web) in un certo lasso di tempo e vogliamo basarci su alcune caratteristiche certe come presenza o meno di promozioni, sconto, recenti pubblicità, meteo o altro. La soluzione: per un problema del genere il modello usato è la distribuzione di Poisson. La nostra y è una distribuzione di Poisson che evidenzia il numero di visitatori. La valorizzazione è discreta ma può essere non finita. Per fare questo applicheremo Modelli Lineari Generalizzati (GLM) per Poisson. Vediamo come costruire da zero un modello che risulti essere un modello generalizzato. Per derivare un modello GLM dobbiamo fare delle assunzioni (per cercare di ritrovare un problema già trattato):
1. Assumiamo che la funzione y che dipende da X e parametri 𝜃 e che sia appartenente alla
famiglia degli esponenziali;
- Assumiamo che dato x il nostro obiettivo è di predire il valore di T(y). Usiamo T(y) e non direttamente y per casi complessi come la classificazione multinominale in cui non si parla della funzione identità. Serve tirare dentro la funzione ipotesi h(x): definiamo la funzione ipotesi
come media del valore y dato x in input. ℎ(𝑥) = 𝐸[𝑦|𝑥].
Esempio: nel caso del nostro mercato immobiliare potremmo avere una pluralità di case al di sopra della soglia che hanno input di x completamente differenti ma stessa y. La media di tutti
questi casi è ℎ.
• 𝑔(𝜂) = 𝐸[𝑇(𝑦); 𝜂] dove g è la funzione di risposta canonica che dà la media di 𝑇 come una
funzione del parametro naturale 𝜂. L’inverso 𝑔−^1 è chiamato funzione di link canonico.
Lezione 5 - Fondamenti di Machine Learning - Parte III
Classificazione per casi multipli: nella situazione di casi multipli abbiamo bisogno di una funzione di risposta che possa prendere k valori discreti con k massimo valore che y può assumere. y si troverà in termini statistici come una distribuzione multinominale. La distribuzione multinominale può essere espressa come membro della famiglie esponenziali dei GLM. Softmax Regression – Notation: il primo passaggio da effettuare è definire le probabilità per la y
quando assume valori da 1 a k. Definiamo da 𝜙 1 a 𝜙𝑘− 1 , ci fermiamo a k- 1 perché queste sono
indipendenti e la k-esima sarà legata linearmente a queste. Abbiamo ora la possibilità di riferirci alla espressione canonica dei modelli GLM in questa espressione canonica dobbiamo introdurre la funzione T(y). T è definita come sufficient statistic ( statistica sufficiente ) di y che normalmente è una funzione reale di argomento y e normalmente è anche identica a y. Ma nel multinominale ha valore vettoriale di dimensione k, in questo vettore ci sarà un solo elemento diverso da 0 che corrisponde al valore che assume y.
La probabilità di y date le probabilità “𝜙” si
esprimono in forma sintetica:
prob(𝑦; 𝜙) = 𝜙+
+( 6 *+)
+( 6 *.)
... 𝜙H
+( 6 *H) è stata introdotta la funzione indicatore che indica che rimane selezionato solo il termine che assume valore 1 mentre gli altri hanno valore 0. Possiamo introdurre la funzione T al posto della funzione indicatore esprimendola in formato esponenziale ci permette di arrivare alla formula finale.
La 𝜂 è un vettore che ha argomenti logaritmo di una probabilità mentre la funzione 𝛼 di log
partizione dipende solo dalla k-esima probabilità (ovvero la somma delle probabilità precedenti). Questo ci consente di affermare che la funzione multi nominale è una funzione della famiglia GLM.
Link function: è la funzione che lega le 𝜙 alla 𝜂: 𝜂𝑖 = log 2
𝜙𝑖 𝜙𝑘
3 con 𝑖 = 1... 𝑘 e possiamo trovare
la funzione risposta che è l’inversa della funzione link che conduce dai valori de 𝜂 a 𝜙. Ogni
probabilità i-esima dipende dai valori del parametro canonico:
1 ! 𝑒𝜂𝑗 𝑘 𝑗= 1
𝑒𝜂𝑖 ! 𝑒𝜂𝑗 𝑘 𝑗= 1 possiamo ora identificare la funzione SoftMax. La funzione logistica è un caso specifico della softmax mentre la funzione Softmax è una generalizzazione. La funzione ipotesi è la
probabilità che y assume valore i avendo x e parametri 𝜃 quindi la possiamo scrivere come:
"$
% "$ &'( Possiamo scrivere che ogni termine del vettore può essere espresso dall’input con un prodotto
interno questo è ripetibile con tutti i k da 1 a k-1: 𝜂𝑖 = 𝜃𝑖
𝑇
𝑥 con 𝑖 = 1... 𝑘 − 1. I 𝜃 son a volte
chiamati features.
Andiamo ad elaborare la funzione ipotesi ℎ che è il valor medio della statistica sufficiente dato dal
valore dell’input e valore dei parametri 𝜃: ℎ(𝑥) = 𝐸[𝑇(𝑦)|𝑥, 𝜃].
Quando usiamo la Softmax function possiamo trasformare queste probabilità in funzione degli 𝜂
possiamo quindi applicarlo al caso della ottimizzazione dei parametri quando abbiamo un training set. Il training set è un insieme di coppie ingresso uscita che producono m campioni. Dopo il training set si passa ad esprimere il Log Likelyhood (somiglianza logaritmica).
log(𝐿(𝜃)) = log( prob(𝑦|𝑥; 𝜃)) = log ∏
)*+ ,
prob(𝑦())|𝑥()); 𝜃)
"'( )
log( prob(𝑦(")|𝑥("); 𝜃) = ∑
"'( )
log(𝜙" ) = ∑
"'( )
log ∏
,'( %
"$(")
##^ "$(") %
((-(!)',)
Arriviamo quindi al log delle “𝜙” con la Softmax function diventa come in figura per esprimere la
ricerca del miglior 𝜃 per massimizzare la Log Likehood. Utilizziamo la tecnica del gradiente e il
metodo della gradient discent. Generalizzazione della funzione di perdita: nel supevised learning definiamo dei dati di input x
appartenenti a 𝑅
𝑛 e dei target y appartenente a Y ed una funzione di perdita. Nel caso della
regressione lineare 𝑦 ∈ ℜ, nella regressione logistica abbiamo una classificazione binaria;
tipicamente y appartiene all’insieme {1,1} e nella classificazione multiclasse y appartiene a {1,2, … , k} per un numero k massimo di classi da riconoscere. Le funzioni di perdita sono in generale
spesso presente un prodotto scalare tra i 2 vettori < 𝑥, 𝑧 >. Dato il feature mapping, definiamo
kernel come prodotto tra i due mapping dei valori di input: 𝐾(𝑥, 𝑧) =< 𝜙(𝑥), 𝜙(𝑧) >=
𝜙(𝑥):𝜙(𝑧). Ora passeremo a sostituire con 𝐾 dove troviamo un prodotto interno del tipo<
𝑥, 𝑧 >con gli stessi argomenti.
Rischio Empirico: proviamo a sviluppare il tema del Rischio Empirico. Prima lo abbiamo descritto
in termini di 𝜃 e poi ci siamo accorti che possiamo trasferirlo nei parametri incogniti 𝛼 ed abbiamo
introdotto un 𝜆 non negativo.
𝐽(𝜗) = 𝐽N(𝛼) =
)*+ ,
𝐿 j𝜙(𝑥())):^ ∑
7 *+ ,
𝛼 7 𝜙(𝑥(^7 ), 𝑦()))k^ +
lm ∑
)*+ ,
𝛼)𝜙(𝑥(^7 ))ml
. .
Facendo il trasferimento dalle x alle 𝜙(𝑥) usando le feature mapping abbiamo l’espressione
sopra. Introducendo il kernel dove invece abbiamo il feature mapping là dove c’era il prodotto interno tra 2 feature mapping abbiamo l’espressione qui sotto:
𝑖= 1 𝑚
𝐿 E ∑
𝑗= 1 𝑚
𝛼𝑗𝐾(𝑥(𝑖), 𝑥(𝑗)), 𝑦(𝑖)F +
𝑖,𝑗= 1 𝑚
E’ più sintetica ∑
𝑗= 1 𝑚
𝛼𝑗𝐾(𝑥(𝑖), 𝑥(𝑗)) non è che la matrice i,j sostituibile con [𝐾(𝑥()), 𝑥(^7 ))]), 7 *+...,.
Questa ha tutti i possibili prodotti interni dei mapping dei 2 elementi del training set di tipo input.
Dato il vettore di mapping “𝜙” possiamo computare il kernel 𝐾(𝑥, 𝑧) e poi passare al calcolo del
rischio empirico. Il calcolo del kernel può essere semplice mentre il mapping potrebbe essere più complesso, si possono incontrare degli algoritmi dove non è necessario fare il mapping in maniera esplicita. Questo ci consente di fare apprendimento in spazi altamente dimensionali e non dobbiamo per questo introdurre esplicitamente il mapping.
Esempi di kernel: kernel Minimo con𝑥 ∈ ℜ:
𝐾(𝑥, 𝑧) = 𝑚𝑖𝑛(𝑥, 𝑧) è il minimo tra i due
valori passati. Kernel Gaussiano o Radial Basis Function
(RBF) con x appartenente a ℜ
𝑛 : nell’esponente troviamo la norma euclidea quadrata della differenza tra i due input x e z argomenti del kernel.
𝜏 è un parametro libero definito come
larghezza di banda e deve essere positivo. Con 𝜏 piccolo ci troviamo con un kernel circa nullo a
meno che la x è molto vicina a z. Se x è molto vicina a z il kernel è circa 1 (il massimo). Con 𝜏
molto grande il kernel ha un andamento morbido, quando la applichiamo nelle predizioni, la
somma di più predizioni che hanno la forma RBF con 𝜏 grande, conduce ad avere molti termini
che determinano il valore finale.
Applicazione pratica di RBF in un caso di classificazione: 𝑦 = ∑
)*+ ,
La predizione ha questa forma (analogo del “𝜙” per x): la somma è dominata dal Kernel che ha
maggiore valore ovvero quello che ha 2 argomenti più vicini tra loro. Nel caso della classificazione binaria abbiamo le x che appartengono al piano cartesiano, il caso positivo lo indichiamo con croci, negativo con pallini. Vogliamo minimizzare il rischio dopo aver deciso quale funzione di perdita abbiamo. Decidiamo di avere un training set m di 200 campioni, lamba inverso 1/m quindi vediamo
cosa accade in simulazioni numeriche con larghezze di banda diverse 𝜏 da 0.1 a 3.2.
Introduciamo il concetto di Superficie di Decisione per ℜ
2 se è una curva, è definita così ovvero
quando la previsione è 0: ∑
𝑖= 1 2
𝐾(𝑥(𝑖), 𝑥)𝛼𝑖 = 0 quindi ∑
𝑖= 1 2
𝐾(𝑥(𝑖), 𝑥)𝛼𝑖 > 0 è una regione con casi
positivi. Implicitamente stiamo assumendo che se la previsione è positiva siamo nella regione dei casi positivi se è negativa siamo nella regione dei casi negativi.
Il rischio empirico ha la seguente forma: 𝐽𝜆(𝛼) =
𝑖= 1 𝑚
[ 1 − 𝑥(𝑖)𝐾
(𝑖)𝑇
𝛼]+ +
𝜆 2
Va ottimizzato per definire 𝛼 ottimale. La matrice K è
definita come tutti i possibili incroci tra i vettori del
training set e input ed anche 𝛼 sono vettori nello spazio
𝑚 . Non guardiamo il colore ma croci positivi e pallini per i negativi cerchiamo di distinguere attraverso la forma di previsione al kernel la zona dove si trovano i campioni positivi dalla zona dove si trovano i campioni negativi.
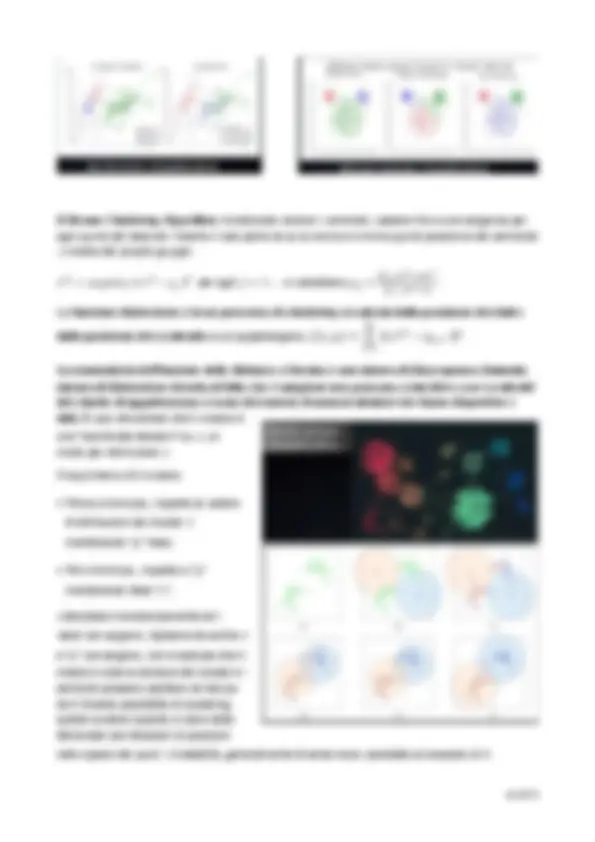
Nella prima figura con 𝜏 = 0. 1 non è soddisfacente
perché la linea è frastagliata e con lacune all’interno con
𝜏 = 0. 2 è più morbida la frontiera tra le regioni ma ci
sono degli errori (positivi in area negativa e viceversa). Per definire quanto sia buona questa classificazione bisogna introdurre delle forme di metro (prossime lezioni). Avendo degli errori la funzione di perdita non è nulla ma ha un certo valore. Alzando ulteriormente la larghezza di banda, la frontiera diventa sempre più morbida e aumentano gli errori. Qui un esempio di classificatore ottimale che minimizza il rischio e usa larghezza di banda che determina le figure di metro migliori. E ’una deformata di una sinusoide.
rete neurale. La rete neurale scoprirà features complesse utili per predire l’output ma difficili da assegnare ad una comprensione umana. Il layer di input lo indichiamo con 𝑥𝑖 con𝑖 = 1... 𝑛. Lo stato interno è l’insieme dei neuroni nascosti nel nostro caso ridotto ad uno stato solo e tre neuroni con le loro uscite chiamate attivazione “a i-esima” Il labelling dei layer nel nostro caso va da 0 a 2: 0 (stato input), 1 (stato interno) e 2 (stato uscita).
Esempio: neurone output:𝑦 = 𝑎 1
[)] L’uscita finale y è l’attivazione allo stato 2 del neurone 1 (unico nell’esempio). Nel layer dello stato interno le attivazione dello stato interno [1] può essere indicato con “𝑎𝑖” con i che va da 1 a 3 (i 3 neuroni): hidden layer:𝑎" [(] with𝑖 = 1.. 3. L’input è nello stato [0] e ha le attivazioni da 1 a 4 dato dai 4 input size, bedrooms, zipcode e wealth: input layer:𝑎" [ 0 ] with𝑖 = 1.. 4. L’uscita di un neurone è chiamata attivazione : 𝑎 = 𝜎(𝑧) con 𝑧 = 𝑤:𝑥 + 𝑏. Introduciamo un vincolo su come viene calcolata l’attivazione diciamo che l’ attivazione è una funzione non lineare di z dove z è una combinazione lineare di tra pesi e input del neurone più un parametro additivo. Esempi:
- Rectifier Linear Unit : unita lineare rettificata (vedi linea del mercato immobiliare con discontinuità per prezzi > 0);
- Sigmoid o Logistic Function (vedi classificazione binaria);
- Tangente iperbolica : funzione esponenziale nota; Nel caso della classificazione binaria abbiamo usato la funzione logistica ma abbiamo anche usato 𝑧 = 𝜗:𝑥 l’espressione z come combinazione lineare dei pesi dei parametri con gli input. Ricordarsi sempre che la linearità c’è da qualche parte nei meccanismi di machine learning ma nell’insieme la funzione di input/output non è lineare altrimenti sarebbe tutto riconducibile ad una regressione lineare. Abbiamo ora bisogno di esprimere matematicamente l’attivazione del layer interno indicizzato con la label 1. Nella prima riga indicizzato in parentesi quadra [1] che indica il layer, nel nostro caso etichettato come interno, il pedice della “a” è 1 per indicare il neurone 1, nel neurone 1 del layer 1 utilizziamo una funzione non lineare z: 𝜎(𝑧 1 [ 1 ] ) come riga 1 della matrice W dopo trasposta va a moltiplicare gli input del neurone e sommato
ad un termine additivo, stessa cosa per gli altri 2 neuroni del layer 1: 𝑧 1 [ 1 ] = 𝑊 1 [ 1 ]𝑇 𝑥 + 𝑏 1 [ 1 ] . Attivazione dello stato di uscita. L’attivazione nel layer [2] dell’unico neurone di uscita (nel nostro esempio) è dato dalla non
linearità applicata alla variabile interna 𝑧 1 : è
una combinazione lineare tra la matrice pesi dello stato [2] e la prima riga ed il vettore “a”. Il vettore “a” è la concatenazione delle uscite delle attivazioni del layer [1] dei 3 neuroni. Per calcolare l ’ uscita del neurone dello stato di output occorre l ’ attivazione dei neuroni dello stato precedente. L ’ attivazione dell ’ unico neurone di output è la predizione della Rete Neurale, è la variabile che dovremo cercare di adattare ai
casi reali. Nel mercati immobiliare avremo il prezzo 𝑎[^2 ], questo prezzo avrà dietro dei parametri
(valori di variabili di input) e dovremmo cercare di adattare la situazione interna della rete e i parametri messi in gioco in modo che il prezzo sia il più vicino possibile a quello reale misurato. Rete Neurale FeedForward: noi abbiamo costruito un layer come un insieme di neuroni che prendono input dalle attivazioni di un altro layer. I layer sono ordinati dall’ingresso verso l’uscita. Possiamo introdurre quanti layer vogliamo all’interno della rete. Il layer di input è prestabilito dal numero in input nel training set nell ’ esempio sono 4 quindi dobbiamo avere 4 unità formali. In uscita a seconda di quante variabili dobbiamo predire avremo neuroni corrispondenti con qualche eccezione per il caso della classificazione. Nel mezzo possiamo costruire un numero di strati che vogliamo ma anche in numero di dimensione che vogliamo. Ogni layer può prendere input solo dallo stato precedente da qui il nome di FeedForward Neural Network. Vettorizzazione: il modo di base per calcolare tutte le attivazioni dal layer di ingresso al layer di uscita è di usare dei loop. Nelle reti neurali questa modalità non può essere utilizzata per un motivo di efficienza del calcolo ed anche storicamente si è visto che la prima onda delle reti neurali negli ‘80/90 ha risentito delle inefficienze fatte in questi termini. Quindi serve vettorializzare il calcolo : dobbiamo partire dal presupposto che le applicazioni di deep learning reali hanno requisiti computazionali molto alti e i codici eseguiti sarebbero molto lenti se usassero loop. Le reti moderne di deep learning e i data set sarebbero non trattabili se utilizziamo i cicli for: la vettorizzazione trae vantaggio dall’algebra matriciale e fornisce dei pacchetti di calcolo numerico che si basa sull’algebra lineare e che sono molto ottimizzati. La vettorizzazione ottimizza il calcolo ed il tempo di risposta delle reti neurali