


563 L06.1 Fall 2010
ECE 563
Advanced Computer Architecture
Fall 2010
Lecture 7: Vector Processors
























Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Advanced Computer Architecture. Fall 2010. Lecture 7: Vector Processors ... Styles of Vector Architectures ... Vector equivalent of load-store architectures.
Typology: Slides
1 / 32

This page cannot be seen from the preview
Don't miss anything!
Fall 2010
Fall 2010
Fall 2010
Vector Processing
Vector processors have high-level operations thatwork on linear arrays of numbers: "vectors"
Fall 2010
Properties of Vector Processing
Each result independent of previous result
Vector instructions access memory with knownpattern
Reduces branches and branch problems inpipelines
Single vector instruction implies lots of work (
~
loop)
Fall 2010
Components of Vector Processor
Vector Register
: fixed length bank holding a single
vector
Vector Functional Units (FUs)
: fully pipelined, start
new operation every clock
Vector Load-Store Units (LSUs)
: fully pipelined unit
to load or store a vector; may have multiple LSUs
Scalar registers
: single element for FP scalar or
address
Cross-bar to connect FUs , LSUs, registers
Fall 2010
“DLXV” Vector Instructions
Fall 2010
Cray-1 (1976)
Single PortMemory16 banks of64-bit words
8-bit SECDED 80MW/sec dataload/store320MW/secinstructionbuffer refill
4 Instruction Buffers
64-bitx
NIP LIP
CIP
(A
0
)
( (A
h
) + j k m )^64 T Regs
(A
0
)
( (A
h
) + j k m ) 64 B Regs
S0S1S2S3S4S5S6S7 A0A1A2A3A4A5A6A
S
i T
jk A
i
B
jk
FP AddFP MulFP RecipInt AddInt LogicInt ShiftPop Cnt
S
j S
i S
k
Addr AddAddr Mul
A
j
A
i
A
k
V0V1V2V3V4V5V6V
V
k
V
j
V
i
V. Mask V. Length
64 Element
Vector Registers
12 FUs
8 scalar Registers 8 address Registers
Fall 2010
Scalar Registers
Vector Registers
Memory
Vector Register
Fall 2010
Vector Instruction Set Advantages
Fall 2010
clock) to execute elementoperations
pipeline because elements invector are independent (=> nohazards!)
Six stage multiply pipeline
563 L06.
Fall 2010
1
2
3
4
5
6
7
8
9
A B C D E
F
Base
Stride
Vector Registers
Memory Banks
Address Generator
Bank busy time
: Cycles between accesses to same bank
563 L06.
Fall 2010
Lane
Functional Unit
Vector
Registers
Memory Subsystem
Elements0, 4, 8, …
Elements1, 5, 9, …
Elements 2, 6, 10, …
Elements 3, 7, 11, …
563 L06.
Fall 2010
load
Vector Instruction Parallelism
example machine has 32 elements per vector register and 8 lanes
load
mul mul
add add
Load Unit
Multiply Unit
Add Unit
time
Instruction
issue
Complete 24 operations/cycle while issuing 1 short instruction/cycle
Fall 2010
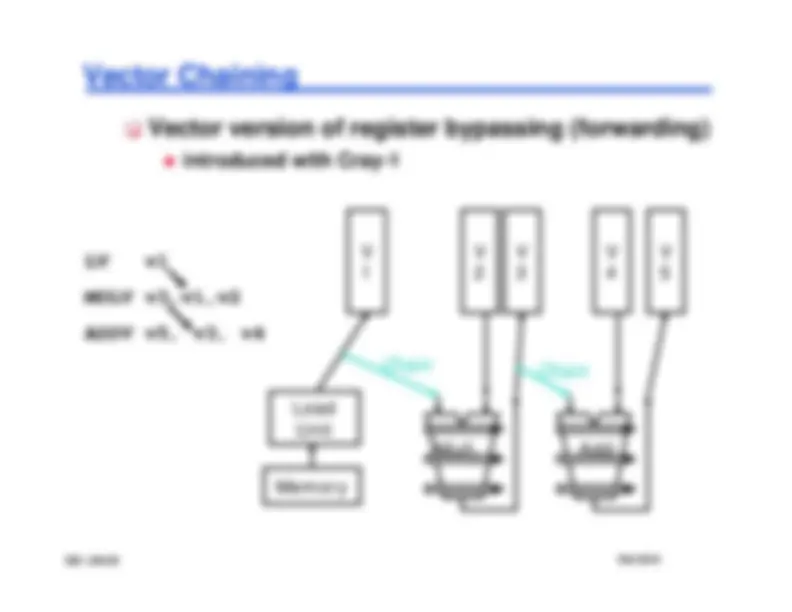
Vector Chaining
Vector version of register bypassing (forwarding)
Memory
Load Unit
Mult.
Chain
Add
Chain