



Advanced Databases
Stratis D. Viglas
University of Edinburgh
Stratis D. Viglas (University of Edinburgh) Advanced Databases 1/1



































































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
The attica database system. ▻ Home-grown RDBMS, written in Java. ▻ Visit inf.ed.ac.uk/teaching/courses/adbs/attica to download the system and the API ...
Typology: Study notes
1 / 721

This page cannot be seen from the preview
Don't miss anything!
University of Edinburgh
Introduction Overview
Introduction Overview
I (^) Data model, evaluation model
I (^) Indexes, multidimensional data
I (^) Join evaluation algorithms, execution models
I (^) Cost models, search space exploration, randomised optimisation
I (^) Locking and transaction processing
Introduction Overview
I (^) Home-grown RDBMS, written in Java I (^) Visit inf.ed.ac.uk/teaching/courses/adbs/attica to download the system and the API documentation I (^) All programming assignments will be using the attica front-end and code-base
I (^) No discussion
Introduction Relational databases overview
Introduction Relational databases overview
I (^) A (name, value) pair
I (^) A set of attributes
I (^) A set of tuples with the same schema
SID 123-ABC
SID 123-ABC
Name Mary Jones
... ...
Year 4
SID 123-ABC
Name Mary Jones
... ...
Year 4 456-DEF John Smith ... 3 ... ... ... ... 999-XYZ Jack Black ... 4
Introduction Relational databases overview
Page
Platter
Track
Disk drives are organised in records of 512 bytes The DB (and the OS) I/O unit is a disk page (typically, 4,096 bytes long) Pages (and records) are stored on tracks Tracks make up a platter (or a disk) Platters make up a drive The same tracks across all platters make up a cylinder The disk head (arm) reads the same block of all tracks on all platters
Introduction Relational databases overview
I (^) The head would fly at Mach 800 I (^) At less than one centimeter from the ground I (^) And count every blade of grass I (^) Making fewer than 10 unrecoverable counting errors in an area equivalent to all of Ireland
(^1) Source: Matthieu Lamelot, Tom’s Hardware.
Introduction Relational databases overview
I (^) A header I (^) Data (i.e., tuples) I (^) Padding (maybe)
I (^) Either interleave tuples of multiple relations, or I (^) Keep the tuples of the same relation clustered
Header Relation 1 Relation 2 Relation 3 Relation 2 Relation 3 Relation 1 Relation 2 Relation 3 Padding
Interleaved tuples
Header Relation 1
Relation 1 Padding
Relation 1 Relation 1 Relation 1 Relation 1 Relation 1 Relation 1 Relation 1
Clustered tuples
Introduction Relational databases overview
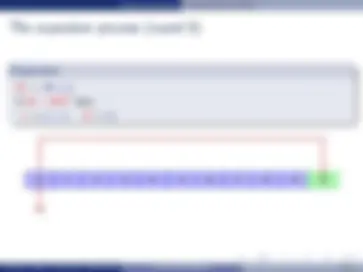
I (^) If unclustered, worst case scenario: read X blocks I (^) Clustered: read X /Y blocks
I (^) Reduces unnecessary arm movement
Unclustered storage
Clustered storage
Introduction Relational databases overview
I (^) Checks to see if the page is in the buffer pool; if so it returns it I (^) If not, it checks whether there is room in the buffer pool; if so it reads it in and places it in the available room I (^) If not, it picks a page for replacement; if the page has been “touched” it writes the page to disk and replaces it I (^) In all three cases, it updates the reference count for the requested page I (^) If necessary, it pins the new page I (^) It returns a handle to the new page
Introduction Relational databases overview
I (^) Variant: clock replacement
Storage and indexing Overview
Storage and indexing Overview
I (^) Forget whatever you’ve learned about indexing, searching and sorting in main memory (well, almost.. .)
I (^) The main idea is to minimise disk I/O and not number of comparisons (i.e., complexity) I (^) Just an idea: comparing two values in memory costs 4. 91 · 10 −^8 seconds; Comparing two values on disk costs 18. 2 · 10 −^5 seconds ( orders of magnitude more expensive.)