


B.B. Karki, LSU
0.1
CSC 3102
Algorithm Design Techniques
Brute force
Divide-and-conquer
Decrease-and-conquer
Transform-and-conquer
Space-and-time tradeoffs
Dynamic programming
Greedy techniques









Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Material Type: Assignment; Professor: Karki; Class: ADV DATA STRUCTURES; Subject: Computer Science; University: Louisiana State University; Term: Unknown 1989;
Typology: Assignments
1 / 16

This page cannot be seen from the preview
Don't miss anything!
2
3
n
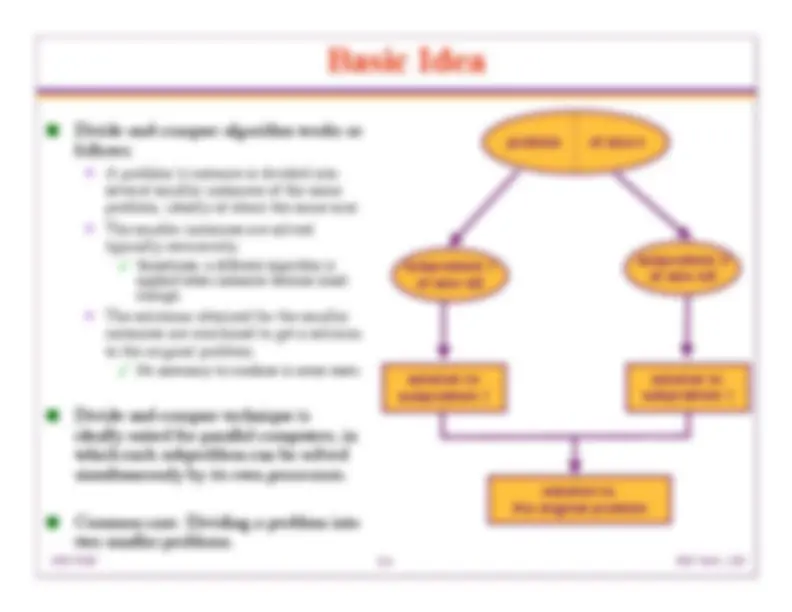
Divide-and-conquer algorithm works as follows: A problem’s instance is divided into several smaller instances of the same problem, ideally of about the same size. The smaller instances are solved typically recursively. Sometimes, a different algorithm is applied when instances become small enough. The solutions obtained for the smaller instances are combined to get a solution to the original problem. No necessary to combine in some cases. Divide-and-conquer technique is ideally suited for parallel computers, in which each subproblem can be solved simultaneously by its own processors. Common case: Dividing a problem into two smaller problems. problem of size n subproblem 1 of size n/ subproblem 2 of size n/ solution to subproblem 1 solution to subproblem 1 solution to the original problem
A problem’s instance of size n is often divided into two instances of size n /2. In general, an instance of size n can be divided into several instances of size n / b , with a of them needing to be solved ( a ≥ 1, b ≥ 2). If n is a power of b , say, n = bk , the recurrence relation for running time is T(n) = a T(n/b) + f(n), called the general divide-and-conquer recurrence Where f ( n ) is a function that accounts for the time spent on dividing the problem into smaller ones and on combining their solutions. Master Theorem: If f ( n ) ∈ Θ( nd ) where d ≥ 0 in recurrence equation, then Analogous results hold for the big-oh and big-omega notations. It can only establish solution’s order of growth to within an unknown multiplicative constant but solving a recurrence equation with a specific condition can actually yield an exact answer. € T ( n ) ∈ Θ( n d ) a < b d Θ( n d log n ) a = b d Θ( n log b a ) a > b d
Merges two sorted arrays using two pointers (array indices) i and j by comparing the elements currently pointed. The smaller of them is added to a new array being constructed. Algorithm Merge ( B[0.. p - 1], B[0.. q - 1], A[0.. p + q - 1] ) //Merges two sorted arrays into one sorted array //Input: Arrays B[0 ..p - 1] and C[0 ..q - 1] both sorted //Output: Sorted array A[0.. p + q - 1] ) of the elements of B and C i ← 0; j ← 0; k ← 0 while i < p and j < q do if B[ i] ≤ C[ j] A[ k] ← B[ i]; i ← i + 1 else A[ k] ← C[ j]; j ← j + 1 k ← k + 1 if i = p copy C[j.. q - 1] to A[ k.. p + q - 1] else copy b[ i.. p - 1] to A[ k.. p + q - 1]
For simplicity, assume that n is a power of 2 so the recurrence relation for the number of keys comparisons is C ( n ) = 2 C ( n /2) + C merge( n ) for n > 1, C (1) = 0. each C ( n /2) corresponds to one of two subarrays after dividing the array of size n. Both subarrays have the same size of n /2. The worst-case efficiency: The number of key comparisons performed during the merging state: C worst( n ) = n - 1 So the worst-case recurrence becomes C worst( n ) = 2 C worst( n/ 2) + n - 1 for n > 1, C worst(1) = 0. Using Master Theorem: a = 2, b = 2 and d = 1 so a = bd^ and hence C worst( n ) ∈ Θ( n log n ) For n = 2 k , one can actually find the exact solution C worst( n ) = n log 2 n - n + 1 The time efficiency is in Θ( n log n ) in all cases, with the number of key comparisons being very close to the theoretical minimum. It’s principal drawback is a significant extra storage requirement.
Select a pivot: Simply chose subarray’s first element, p = A [ l ] Use median-of-three partitioning Achieve a partition by the left-to-right and right-to-left scans. The left-to-right scan starts with the second element, skips over elements that are smaller than pivot, and stops on encountering the first element greater than or equal to the pivot. The elements smaller than the pivot are in the first part of the subarray. The right-to-left scan starts with the last element of the subarray, skips over elements that are larger than the pivot and stops on encountering the first element smaller than or equal to the pivot. The elements larger than the pivot are in the second part of the subarray. Three scan situations: If scanning indices i and j have not crossed, i.e., i < j , exchange A [ i ] and A [ j ], and resume the scans incrementing i and decrementing j , respectively. If the scanning indices have crossed over, i.e., i > j , we have partitioned the array after exchanging the pivot with A [ j ]. If, the scanning indices stop while partitioning to the same element, i.e., i = j , the value they are pointing must be equal to p. Thus we have partitioned the array.
An example of quicksort: An array of size n = 8 is (5, 3, 1, 9, 8, 2, 4, 7). See figure 4.3 in the text book. Use a pivot = A [0] = 5 , the first element of the array. Algorithm Partition ( A[ l, r] ) //Partitions a subarry using its first element as a pivot //Input: A subarray A[ l, r] of A[0 ..n - 1], defined by its // left and right indices l and //Output: A partition of A[ l, r] with the split position // returned as this function’s value p ← A[ l]; i ← l; j ← r + 1 repeat repeat i ← i + 1 until A[ i] ≥ p repeat j ← j - 1 until A[ j] ≤ p swap ( A[ i], A[ j]) until i ≥ j swap( A[ i], A[ j] ) // undo last swap when i ≥ j swap( A[ l], A[ j]) return j
worst
worst
worst
worst
2
Maximize the area of the triangle with the line as its base. Determine the sign of the determinant formed by three points P 1 (x1,y1), P 2 (x2,y2) and P 3 (x3,y3) to decide whether or not the third point P 3 is to the left of the line. x1 y1 1 x2 y2 1 x3 y3 1
2