Download Projection Methods for Monotone Variational Inequalities: Fixed-Point Iteration - Prof. An and more Study notes Engineering in PDF only on Docsity!
Lecture 21
Algorithms for Monotone VIs
Projection Methods
November 17, 2008
Outline
- Projection Methods
- Basic Fixed-Point Iteration
- Extra-gradient Method
- Hyperplane Projection Method
Basic Fixed-Point Iteration
Throughout the rest, we assume that K ⊂ Rn^ is closed and convex, and
F : K → Rn^ is continuous mapping.
- We consider the “skewed” natural map F (^) K,Dnat(x) = x − ΠK,D[x − D−^1 F (x)],
where D is a symmetric and positive definite matrix.
- Such a matrix, induces and inner product and a norm in Rn: < x, y >D = xT^ Dy, ‖x‖ =
xT^ Dx.
- The skewed projection ΠK,D on K is just a projection with respect to
norm ‖ · ‖D,
x ˆ = ΠK,D[x] ⇐⇒ xˆ solves min y∈K ‖x − y‖^2 D.
Fact
The projection mapping x 7 → ΠK,D[x] is nonexpansive in the norm ‖ · ‖D
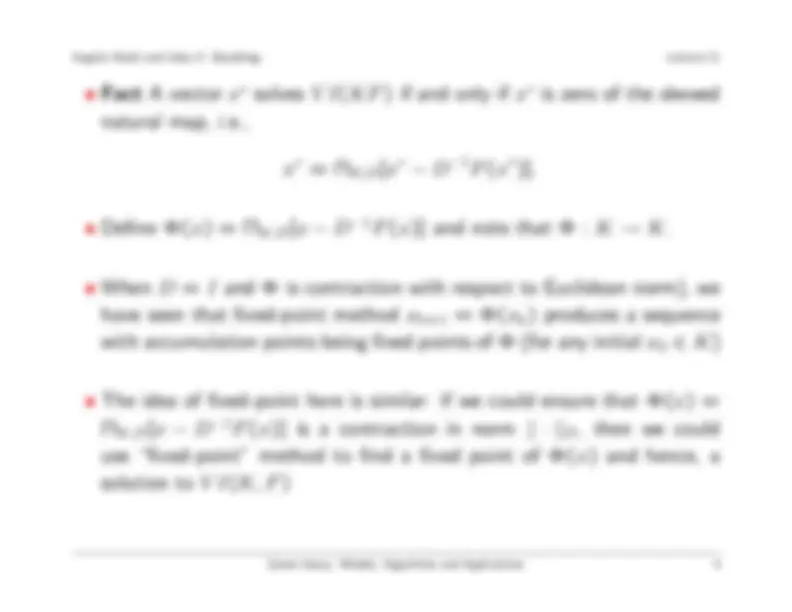
- Fact A vector x∗^ solves V I(KF ) if and only if x∗^ is zero of the skewed
natural map, i.e.,
x∗^ = ΠK,D[x∗^ − D−^1 F (x∗)].
- Define Φ(x) = ΠK,D[x − D−^1 F (x)] and note that Φ : K → K.
- When D = I and Φ is contraction with respect to Euclidean norm), we
have seen that fixed-point method xk+1 = Φ(xk) produces a sequence
with accumulation points being fixed points of Φ (for any initial x 0 ∈ K)
- The idea of fixed-point here is similar: if we could ensure that Φ(x) =
ΠK,D[x − D−^1 F (x)] is a contraction in norm ‖ · ‖D, then we could
use “fixed-point” method to find a fixed point of Φ(x) and hence, a
solution to V I(K, F )
Convergence for Strongly Monotone Mappings
Theorem 1 Let F : K → Rn. Suppose F is strongly monotone and
Lipschitz continuous on K,
(F (x) − F (y))T^ (x − y) ≥ μ‖x − y‖^2 , ‖F (x) − F (y)‖ ≤ L‖x − y‖^2.
Also, let
λmax < 2 μ L^2
λ^2 min,
where λmax and λmin are the largest and smallest eigenvalues of D.
Then, the mapping ΠK,D[x − D−^1 F (x)] is contraction in ‖ · ‖D with
contraction factor
η = 1 − L
2 λmax λ^2 min
( 2 μλ^2 min L^2 −^ λmax
) .
Therefore, the sequence {xk} converges to the unique solution of V I(K, F ).
Proof: For any two vectors x, y in K, we have
‖ΠK,D[x − D−^1 F (x)] − ΠK,D[y − D−^1 F (y)]‖^2 D ≤ ∥∥x − D−^1 F (x) − (y − D−^1 F (y))∥∥^2 D.
Why? By expanding the last term, we have
‖ΠK,D[x − D−^1 F (x)] − ΠK,D[y − D−^1 F (y)]‖^2 D ≤ ∥∥x − y‖^2 D − 2(F (x) − F (y))T^ (x − y) + ‖F (x) − F (y)‖^2 D− 1.
Using the strong convexity, we have
(F (x) − F (y))T^ (x − y) ≥ μ‖x − y‖^2 ≥ μ λmax
‖x − y‖^2 D. (1)
From
‖F (x) − F (y)‖^2 D− 1 ≤ 1 λmin
‖F (x) − F (y)‖^2
and Lipschitz continuity of F , we obtain
‖F (x) − F (y)‖^2 D− 1 ≤ L
2 λ^2 min
‖x − y‖^2 D (2)
Co-coercive Mapping
The projection method can be used to solve V I(K, F ) with co-coercive
mapping. The reason why this work is that the (Euclidean) projection
is co-coercive, and when F is co-coercive, then the τ -natural mapping
x 7 → ΠK [x − τ F (x)] is also co-coercive for some range of values of τ.
In particular, we have the following results
Lemma 1 Let F : K → Rn^ be co-coercive with constant c. If 0 < τ < 4 c,
then F K,τnat (x) = ΠK [x − τ F (x)] is co-coercive with constant 1 − 4 τc.
Proof: See Lemma 12.1.7 of FP-II.
Convergence for Co-coercive Mapping
Theorem 2 Assume that V I(K, F ) has a solution. Let F : K → Rn^ be
co-coercive with constant c. Consider the projection method
xk+1 = Π[xk − τ F (xk)],
where τ < 2 c. Then, the sequence {xk} converges to a solution of
V I(K, F ).
Proof We have for a fixed point x∗^ of F Knat (also a fixed point of F K,τnat for
any τ > 0 ),
‖xk+1 − x∗‖^2 ≤ ‖Π[xk − τ F (xk) − Π[x∗^ − τ F (x∗)]‖^2 ≤ ‖xk − x∗^ − τ (F (xk) − F (x∗))‖^2 = ‖xk − x∗‖^2 − 2 τ (F (xk) − F (x∗))T^ (x − x∗)
implying F (xk) → F (x∗).
(This also implies that {F (x∗) | x∗^ ∈ SOL(K, F )} is a singleton - why
would this be expected). In view of the preceding two relations, it follows
that
dist(xk, SOL(K, F )) → 0.
Note, also that (3) implies that the scalar sequence {‖xk − x∗‖} is nonin-
creasing for any fixed point x∗. Therefore, the scalar sequence {‖xk − x∗‖}
is convergent for any fixed point x∗. This, and dist(xk, SOL(K, F )) → 0
imply that {xk} is convergent and its limit point is in SOL(K, F ).
The proof in the FP-II is given in Lemma 12.1.15 for the case when
- τ is varying and τkF (xk) is replaced with F k(xk), where all V I(K, F k)
have the same solution set.
- K = Rn
- Assuming that each mapping F k^ : Rn^ → Rn^ is co-coercive with ck, and
the following condition is satisfied: infk ck > 1 / 2.
Extra-Gradient Method
The name of method comes from its equivalent version in optimization
(F = ∇f (x)).
It has two projection steps
zk+1 = ΠK [x − τ F (xk)], xk+1 = ΠK [xk − τ F (zk+1)]
The main iterate is xk+1. The extra-iterate zk+1 is used to construct the
direction for moving away from xk.
- The advantage of taking an extra step is that the algorithm performs
better than the projection method
- The convergence analysis still requires F to be Lipschitz
- It can be used to solve V I(K, F ) with a pseudo-monotone map F
- We will study it as applied to a monotone V I(K, F )
By the monotonicity of F and x∗^ ∈ SOL(K, F ), it follows
(F (zk+1)−F (x∗))T^ (zk+1)−x∗) ≥ 0 =⇒ F (zk+1)T^ (zk+1−x∗) ≥ 0.
Hence, F (zk+1)T^ (zk+1 − xk+1) + F (zk+1)T^ (xk+1 − x∗) ≥ 0 implying that
F (zk+1)T^ (zk+1 − xk+1) ≥ F (zk+1)T^ (x∗^ − xk+1)
Using this relation in (4), we see
‖xk+1 − x∗‖^2 ≤ ‖xk − x∗‖^2 − ‖xk+1 − xk‖^2 + 2τ F (zk+1)T^ (zk+1 − xk+1).
By writing xk+1 − xk = (xk+1 − zk+1) + (zk+1 − xk) and expanding the
squared-norm of this term, and then combining the terms that are in the
inner product with zk+1 − xk+1, we obtain
‖xk+1 − x∗‖^2 ≤ ‖xk − x∗‖^2 − ‖xk+1 − zk+1‖^2 − ‖zk+1 − xk‖^2 +2(xk+1 − zk+1)T^ (xk − τ F (zk+1) − zk+1).
We can further write [by adding and subtracting τ F (xk)]
(xk+1 − zk+1)T^ (xk − τ F (zk+1) − zk+1) = (xk+1 − zk+1)T^ (xk − τ F (zk) − zk+1) +τ (xk+1 − zk+1)T^ (F (xk) − F (zk+1))
Since xk+1 ∈ K and zk+1 = ΠK [xk − τ F (xk)], the first term on the right
hand side is nonnegative (by projection property). Thus, by using this and
Lipschitz continuity of F , we have
(xk+1 − zk+1)T^ (xk − τ F (zk+1) − zk+1) ≤ τ (xk+1 − zk+1)T^ (F (xk) − F (zk+1)) ≤ τ L‖xk+1 − zk+1‖ · ‖xk − zk+1‖ ≤ 12 (‖xk+1 − zk+1‖^2 + τ 2 L^2 ‖xk − zk+1‖^2 )
Convergence of Extra-Gradient Method
Theorem 4 Let F be monotone and Lipschitz continuous over K with
constant L. Let SOL(K, F ) be nonempty. Then, with τ < L^1 , the se-
quence {xk} generated by the extra-gradient method converges to a solu-
tion of V I(K, F ).
Proof The line of proof relies on the basic iterate relation, and follows a line
of analysis similar to that of Theorem for co-coercive map and projection
method. See FP-II Theorem 12.1.11.
For the estimate in basic relation to result in convergence, we need τ < 1 L.
- In practice, often L is not available
- We can use diminishing step τk at iteration k, with ∑ k τk = +∞
- But the convergence will slow down
- We next consider a modification of the method not relying on the
Lipschitz continuity
Hyperplane Projection Method
Like the extra-gradient method, this method generates an extra-iterate
yk = ΠK [xk − τ F (xk)]. However, the use of this point in constructing the
new iterate is different.
In particular, Armijo search rule is used to determine a point zk defining a
hyperplane
Hk = {x ∈ Rn^ | F (zk)T^ (xk − zk) = 0},
which separates xk^ strongly from the solution set SOL(K, F ) [for contin-
uous monotone map, this set is closed and convex - possibly empty].
In particular, zk is such that, for some positive scalars t, σ, τ ,
F (zk)T^ (xk − zk) ≥ tkσ τ
‖yk − xk‖^2 ,
which strongly separates xk from SOL(K, F ) whenever yk 6 = xk in view of
0 ≥ F (x∗)T^ (x∗^ − zk) ≥ F (zk)T^ (x∗^ − zk) for all x∗^ ∈ SOL(K, F ).