Download Analysis of Fork-Join Parallel Programs and more Slides Programming Languages in PDF only on Docsity!
A Sophomoric Introduction to Shared-Memory
Parallelism and Concurrency
Analysis of Fork-Join Parallel Programs
Outline
Done:
- How to use fork and join to write a parallel algorithm
- Why using divide-and-conquer with lots of small tasks is best
- Combines results in parallel
- Some Java and ForkJoin Framework specifics
- More pragmatics (e.g., installation) in separate notes
Now:
- More examples of simple parallel programs
- Arrays & balanced trees support parallelism better than linked lists
- Asymptotic analysis for fork-join parallelism
- Amdahl’s Law
Examples
- Maximum or minimum element
- Is there an element satisfying some property (e.g., is there a 17)?
- Left-most element satisfying some property (e.g., first 17)
- What should the recursive tasks return?
- How should we merge the results?
- Corners of a rectangle containing all points (a “bounding box”)
- Counts, for example, number of strings that start with a vowel
- This is just summing with a different base case
- Many problems are!
Reductions
- Computations of this form are called reductions (or reduces?)
- Produce single answer from collection via an associative operator
- Examples: max, count, leftmost, rightmost, sum, product, …
- Non-examples: median, subtraction, exponentiation
- (Recursive) results don’t have to be single numbers or strings. They can be arrays or objects with multiple fields. - Example: Histogram of test results is a variant of sum
- But some things are inherently sequential
- How we process arr[i] may depend entirely on the result of processing arr[i-1]
Maps in ForkJoin Framework
- Even though there is no result-combining, it still helps with load balancing to create many small tasks - Maybe not for vector-add but for more compute-intensive maps - The forking is O(log n) whereas theoretically other approaches to vector-add is O(1)
class VecAdd extends RecursiveAction { int lo; int hi; int[] res; int[] arr1; int[] arr2; VecAdd(int l,int h,int[] r,int[] a1,int[] a2){ … } protected void compute(){ if(hi – lo < SEQUENTIAL_CUTOFF) { for(int i=lo; i < hi; i++) res[i] = arr1[i] + arr2[i]; } else { int mid = (hi+lo)/2; VecAdd left = new VecAdd(lo,mid,res,arr1,arr2); VecAdd right= new VecAdd(mid,hi,res,arr1,arr2); left.fork(); right.compute(); left.join(); } } } static final ForkJoinPool fjPool = new ForkJoinPool(); int[] add(int[] arr1, int[] arr2){ assert (arr1.length == arr2.length); int[] ans = new int[arr1.length]; fjPool.invoke(new VecAdd(0,arr.length,ans,arr1,arr2); return ans; }
Maps and reductions
Maps and reductions: the “workhorses” of parallel programming
- By far the two most important and common patterns
- Two more-advanced patterns in next lecture
- Learn to recognize when an algorithm can be written in terms of maps and reductions
- Use maps and reductions to describe (parallel) algorithms
- Programming them becomes “trivial” with a little practice
- Exactly like sequential for-loops seem second-nature
Trees
- Maps and reductions work just fine on balanced trees
- Divide-and-conquer each child rather than array subranges
- Correct for unbalanced trees, but won’t get much speed-up
- Example: minimum element in an unsorted but balanced binary tree in O ( log n ) time given enough processors
- How to do the sequential cut-off?
- Store number-of-descendants at each node (easy to maintain)
- Or could approximate it with, e.g., AVL-tree height
Linked lists
- Can you parallelize maps or reduces over linked lists?
- Example: Increment all elements of a linked list
- Example: Sum all elements of a linked list
- Parallelism still beneficial for expensive per-element operations
b c d e f
front back
- Once again, data structures matter!
- For parallelism, balanced trees generally better than lists so that we can get to all the data exponentially faster O ( log n ) vs. O ( n ) - Trees have the same flexibility as lists compared to arrays
Work and Span
Let TP be the running time if there are P processors available
Two key measures of run-time:
- Work: How long it would take 1 processor = T 1
- Just “sequentialize” the recursive forking
- Span: How long it would take infinity processors = T
- The longest dependence-chain
- Example: O ( log n ) for summing an array
- Notice having > n /2 processors is no additional help
- Also called “critical path length” or “computational depth”
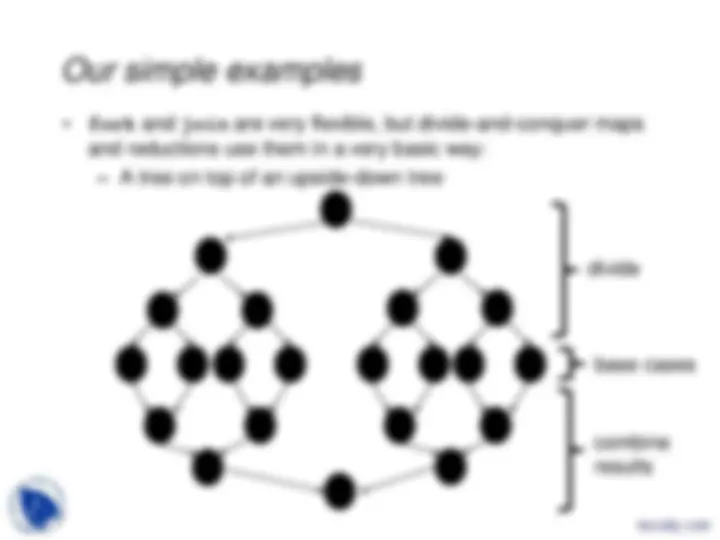
The DAG
- A program execution using fork and join can be seen as a DAG
- Nodes: Pieces of work
- Edges: Source must finish before destination starts
- A fork “ends a node” and makes two outgoing edges - New thread - Continuation of current thread
- A join “ends a node” and makes a node with two incoming edges - Node just ended - Last node of thread joined on
More interesting DAGs?
- The DAGs are not always this simple
- Example:
- Suppose combining two results might be expensive enough that we want to parallelize each one
- Then each node in the inverted tree on the previous slide would itself expand into another set of nodes for that parallel computation
Connecting to performance
- Recall: TP = running time if there are P processors available
- Work = T 1 = sum of run-time of all nodes in the DAG
- That lonely processor does everything
- Any topological sort is a legal execution
- O ( n ) for simple maps and reductions
- Span = T = sum of run-time of all nodes on the most-expensive path in the DAG - Note: costs are on the nodes not the edges - Our infinite army can do everything that is ready to be done, but still has to wait for earlier results - O ( log n ) for simple maps and reductions
Optimal TP: Thanks ForkJoin library!
- So we know T 1 and T (^) but we want TP (e.g., P =4)
- Ignoring memory-hierarchy issues (caching), TP can’t beat
- T 1 / P why not?
- T (^) why not?
- So an asymptotically optimal execution would be:
TP = O ((T 1 / P) + T )
- First term dominates for small P , second for large P
- The ForkJoin Framework gives an expected-time guarantee of asymptotically optimal!
- Expected time because it flips coins when scheduling
- How? For an advanced course (few need to know)
- Guarantee requires a few assumptions about your code…
Division of responsibility
- Our job as ForkJoin Framework users:
- Pick a good algorithm, write a program
- When run, program creates a DAG of things to do
- Make all the nodes a small-ish and approximately equal amount of work
- The framework-writer’s job:
- Assign work to available processors to avoid idling
- Let framework-user ignore all scheduling issues
- Keep constant factors low
- Give the expected-time optimal guarantee assuming framework-user did his/her job
TP = O ((T 1 / P) + T )