Download Applied Statistics using Python MCQ and 2 marks and more Quizzes Applied Statistics in PDF only on Docsity!
ASP LAB
Applied Statistical Programming
Complete Learning Guide
Experiments 1 – 9 | Python | NumPy | SciPy | Scikit-learn
Beginner-Friendly • Dark Mode • Viva Q&A Included
Table of Contents
Experiment 1 Matrix Operations using NumPy
Experiment 2 Mean, Variance and Standard Deviation
Experiment 3 Data Visualization – Univariate & Bivariate
Experiment 4 Correlation and Regression Analysis
Experiment 5 Hypothesis Testing – t-Test & Chi-Square
Experiment 6 Analysis of Variance (ANOVA)
Experiment 7 Principal Component Analysis (PCA)
Experiment 8 K-Means Clustering
Experiment 9 Time-Series Trend Analysis
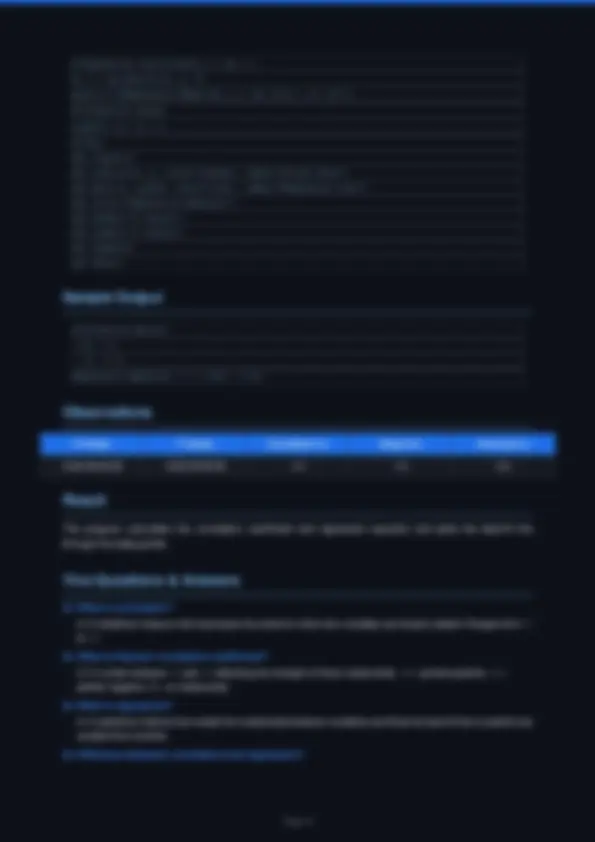
B = np.array([[9, 8, 7], [6, 5, 4], [3, 2, 1]]) print('Matrix A:', A) print('Matrix B:', B)
Basic operations
print('Addition (A+B):', A + B) print('Subtraction (A-B):', A - B) print('Element-wise Multiplication:', A * B) print('Element-wise Division:', A / B) print('Matrix Multiplication (Dot):', np.dot(A, B)) print('Transpose of A:', A.T)
Statistics
print('Mean of A:', np.mean(A)) print('Median of A:', np.median(A)) print('Std Dev of A:', np.std(A)) print('Variance of A:', np.var(A)) print('Row-wise Mean:', np.mean(A, axis=1)) print('Column-wise Mean:', np.mean(A, axis=0)) print('Max:', np.max(A), ' Min:', np.min(A))
Normalization
norm_A = (A - np.min(A)) / (np.max(A) - np.min(A)) print('Normalized A:', norm_A)
Linear Algebra
det = np.linalg.det(A) print('Determinant:', det) if det != 0: print('Inverse:', np.linalg.inv(A)) else: print('Singular matrix – no inverse') eigenvalues, eigenvectors = np.linalg.eig(A) print('Eigenvalues:', eigenvalues) print('Eigenvectors:', eigenvectors)
Step-by-Step Procedure
- Step 1: Open your Python IDE (Spyder/Jupyter).
- Step 2: Import numpy as np at the top of your file.
- Step 3: Create Matrix A and Matrix B using np.array([[...]]).
- Step 4: Perform addition (A+B), subtraction (A-B), element-wise multiplication (A*B) and division
(A/B).
- Step 5: Use np.dot(A, B) for true matrix multiplication.
- Step 6: Use A.T to find the transpose.
- Step 7: Compute statistical values: np.mean(), np.median(), np.std(), np.var().
- Step 8: Normalize the matrix using the min-max formula.
- Step 9: Compute the determinant with np.linalg.det() and inverse with np.linalg.inv().
- Step 10: Compute eigenvalues and eigenvectors with np.linalg.eig().
- Step 11: Run the program and verify the output.
Observations
Operation Result Shape Key Function Addition A+B 3×3 A + B Subtraction A-B 3×3 A - B Element-wise Mult 3×3 A * B Matrix Mult 3×3 np.dot(A,B) Transpose 3×3 A.T Mean Scalar np.mean(A) Determinant Scalar np.linalg.det(A)
Result
The program successfully performs all matrix operations including addition, subtraction, element-wise and
dot-product multiplication, transpose, statistical calculations, normalization, determinant, inverse, and
eigenvalue decomposition using NumPy.
Conclusion
NumPy provides extremely efficient and concise tools for matrix operations that would otherwise require
many lines of manual code. These operations form the foundation of machine learning, image processing,
and engineering data analysis.
Real-World Applications
- Image processing (each image is a matrix of pixel values)
- Machine learning (weight matrices in neural networks)
- Computer graphics (transformation matrices for 3D rendering)
- Structural engineering (finite element analysis)
- Google PageRank algorithm (eigenvalue computation)
Viva Questions & Answers
Q: What is NumPy and why is it used?
A: NumPy (Numerical Python) is a library for numerical computing. It provides the ndarray object which
supports fast vectorized operations, making it much faster than Python lists for mathematical computations.
Q: Difference between a NumPy array and a Python list?
A: Python lists can hold mixed types and are slow for math. NumPy arrays hold a single data type, are stored
in contiguous memory, and support vectorized operations making them 50–100x faster.
Experiment 2 – Mean, Variance and Standard
Deviation
Aim
To write a Python program to compute mean, variance, and standard deviation of user-entered data using
NumPy.
Theory
These three measures are the most fundamental tools in descriptive statistics. They help summarize an
entire dataset with just a few numbers.
Mean (Average)
The mean is the sum of all values divided by the number of values. It represents the central value of the
dataset.
Mean ( μ ) = (x1 + x2 + ... + xn) / n
Variance
Variance measures how spread out the data is from the mean. A high variance means data points are
widely scattered; a low variance means they are clustered near the mean.
Variance ( σ ²) = Σ (xi - μ )² / n
Standard Deviation
Standard deviation is the square root of variance. It is in the same unit as the original data, making it more
interpretable.
Std Dev ( σ ) = √ Variance = √ ( Σ (xi - μ )² / n)
n Note: Standard deviation can NEVER be negative. It is always ≥ 0.
n Tip: If all values are identical, variance and std dev are both 0.
Materials Required
Program
import numpy as np
Get number of elements from user
n = int(input('Enter number of elements: '))
Collect data values
data = [] for i in range(n):
value = float(input(f'Enter element {i+1}: ')) data.append(value)
Convert to NumPy array
data = np.array(data)
Compute statistics
mean = np.mean(data) variance = np.var(data) std_dev = np.std(data)
Display results
print('\nData:', data) print('Mean:', mean) print('Variance:', variance) print('Standard Deviation:', std_dev)
Step-by-Step Procedure
- Step 1: Import NumPy.
- Step 2: Ask the user how many elements they want to enter.
- Step 3: Loop n times and collect each value into a list.
- Step 4: Convert the list to a NumPy array using np.array().
- Step 5: Call np.mean(), np.var(), np.std() on the array.
- Step 6: Print all results clearly.
Sample Output
Enter number of elements: 5 Enter element 1: 10 Enter element 2: 20 Enter element 3: 30 Enter element 4: 40 Enter element 5: 50 Data: [10. 20. 30. 40. 50.] Mean: 30. Variance: 200. Standard Deviation: 14.
Observations
Input Data Mean Variance Std Dev 10, 20, 30, 40, 50 30.0 200.0 14. 5, 5, 5, 5, 5 5.0 0.0 0. 1, 100 50.5 2450.25 49.
Result
Experiment 3 – Data Visualization (Univariate &
Bivariate)
Aim
To write a Python program for data visualization for univariate and bivariate datasets using Matplotlib.
Theory
Data Visualization converts raw numbers into graphical representations, making patterns, trends, and
outliers instantly visible.
Univariate Data
Univariate data has only ONE variable (e.g., heights of students). We visualize its distribution using
histograms, box plots, or bar charts.
Bivariate Data
Bivariate data has TWO variables (e.g., study hours vs marks). We look at the relationship between them
using scatter plots and line plots.
Plot Types
- Histogram — shows frequency distribution of a single variable
- Scatter Plot — shows relationship between two variables as dots
- Line Plot — shows trend over ordered data (e.g., time)
n Note: Always label your axes and give a title. A plot without labels is incomplete.
Materials Required
- Python 3.x
- NumPy — for data arrays
- Matplotlib — for plotting (pip install matplotlib)
Program
import numpy as np import matplotlib.pyplot as plt
--- Univariate Dataset ---
data = np.array([10, 15, 20, 25, 30, 35, 40])
Histogram
plt.figure() plt.hist(data, bins=5, color='steelblue', edgecolor='white') plt.title('Univariate Data - Histogram') plt.xlabel('Values') plt.ylabel('Frequency') plt.show()
--- Bivariate Dataset ---
x = np.array([1, 2, 3, 4, 5]) y = np.array([2, 4, 6, 8, 10])
Scatter Plot
plt.figure() plt.scatter(x, y, color='orange') plt.title('Bivariate Data - Scatter Plot') plt.xlabel('X values') plt.ylabel('Y values') plt.show()
Line Plot
plt.figure() plt.plot(x, y, color='green', marker='o') plt.title('Bivariate Data - Line Plot') plt.xlabel('X values') plt.ylabel('Y values') plt.show()
Step-by-Step Procedure
- Step 1: Import numpy and matplotlib.pyplot.
- Step 2: Create univariate dataset as a NumPy array.
- Step 3: Plot histogram using plt.hist() with appropriate bins.
- Step 4: Add title and axis labels; show the plot.
- Step 5: Create bivariate dataset (x and y arrays).
- Step 6: Plot scatter chart using plt.scatter().
- Step 7: Plot line chart using plt.plot().
- Step 8: Add titles and labels to all plots.
Observations
Plot Type Data Type Function Used Purpose Histogram Univariate plt.hist() Show frequency distribution Scatter Bivariate plt.scatter() Show relationship between variables Line Bivariate plt.plot() Show trends over ordered data
Result
The program successfully visualizes univariate data using a histogram and bivariate data using scatter and
line plots.
Conclusion
Experiment 4 – Correlation and Regression
Analysis
Aim
To write a program to calculate correlation coefficient, generate a regression equation, and graph to
visualize and predict data trends.
Theory
Correlation
Correlation measures the strength and direction of the linear relationship between two variables. The
Pearson Correlation Coefficient (r) ranges from -1 to +1.
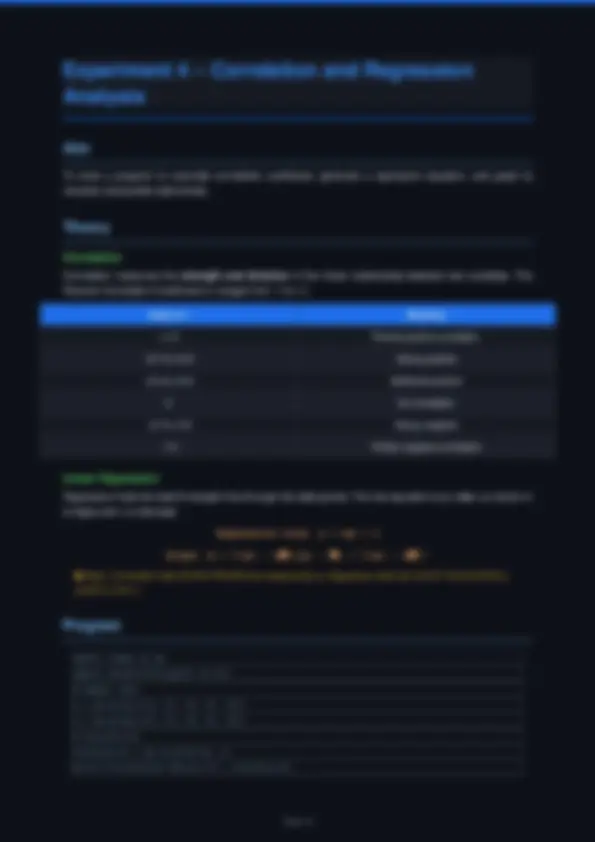
Value of r Meaning +1.0 Perfect positive correlation +0.7 to +0.9 Strong positive +0.4 to +0.6 Moderate positive 0 No correlation -0.7 to -0.9 Strong negative -1.0 Perfect negative correlation
Linear Regression
Regression finds the best-fit straight line through the data points. The line equation is y = mx + c where m
is slope and c is intercept.
Regression Line: y = mx + c
Slope: m = Σ (xi - x n )(yi - n ) / Σ (xi - x n )²
n Note: Correlation tells HOW STRONG the relationship is. Regression tells the EXACT EQUATION to
predict y from x.
Program
import numpy as np import matplotlib.pyplot as plt
Sample data
x = np.array([10, 20, 30, 40, 50]) y = np.array([15, 25, 35, 45, 55])
Correlation
correlation = np.corrcoef(x, y) print('Correlation Matrix:\n', correlation)
Regression coefficients y = mx + c
m, c = np.polyfit(x, y, 1) print(f'\nRegression Equation: y = {m:.2f}x + {c:.2f}')
Predicted values
y_pred = m * x + c
Plot
plt.figure() plt.scatter(x, y, color='orange', label='Actual Data') plt.plot(x, y_pred, color='cyan', label='Regression Line') plt.title('Regression Analysis') plt.xlabel('X values') plt.ylabel('Y values') plt.legend() plt.show()
Sample Output Correlation Matrix: [[1. 1.] [1. 1.]] Regression Equation: y = 1.00x + 5.
Observations X Values Y Values Correlation (r) Slope (m) Intercept (c) 10,20,30,40,50 15,25,35,45,55 1.0 1.0 5.
Result
The program calculates the correlation coefficient and regression equation and plots the best-fit line
through the data points.
Viva Questions & Answers
Q: What is correlation?
A: A statistical measure that expresses the extent to which two variables are linearly related. Ranges from -
to +1.
Q: What is Pearson correlation coefficient?
A: A number between -1 and +1 indicating the strength of linear relationship. +1 = perfect positive, -1 =
perfect negative, 0 = no relationship.
Q: What is regression?
A: A statistical method that models the relationship between variables and finds the best-fit line to predict one
variable from another.
Q: Difference between correlation and regression?
Experiment 5 – Hypothesis Testing (t-Test &
Chi-Square)
Aim
To conduct hypothesis testing using the T-Test (for numerical data) and the Chi-Square Test (for
categorical data) using Python.
Theory
Hypothesis Testing is a statistical method to make decisions about populations based on sample data.
We test two competing claims:
- Null Hypothesis (H n ) : No significant difference exists (default assumption)
- Alternative Hypothesis (H n ) : A significant difference does exist
We use the p-value to decide. If p-value < 0.05 (significance level α), we reject Hn.
t-Test
Used to compare the means of two groups. If the p-value is below 0.05, the groups are significantly
different.
t = (x nn - x nn ) / √ (s²/n n + s²/n n )
Chi-Square Test
Used for categorical data to check if two variables are independent. We compare observed frequencies
with expected frequencies.
χ ² = Σ (Observed - Expected)² / Expected
n Note: p-value < 0.05 → Reject H n (significant difference exists)
n Note: p-value ≥ 0.05 → Fail to reject H n (no significant difference)
Program — t-Test
from scipy import stats n = int(input('Enter number of elements in each group: ')) group1 = [float(input(f'Group1 value {i+1}: ')) for i in range(n)] group2 = [float(input(f'Group2 value {i+1}: ')) for i in range(n)] t_stat, p_value = stats.ttest_ind(group1, group2) print('T-statistic:', t_stat) print('P-value:', p_value) if p_value < 0.05: print('Reject H0: Significant difference exists.') else: print('Fail to reject H0: No significant difference.')
Program — Chi-Square Test
import numpy as np from scipy.stats import chi2_contingency rows = int(input('Enter number of rows: ')) cols = int(input('Enter number of columns: ')) observed = [] for i in range(rows): row = [int(input(f'Value at ({i+1},{j+1}): ')) for j in range(cols)] observed.append(row) observed_array = np.array(observed) chi2, p, dof, expected = chi2_contingency(observed_array) print('Chi-Square Value:', chi2) print('P-value:', p) print('Degrees of Freedom:', dof) print('Expected Frequencies:\n', expected) if p < 0.05: print('Reject H0: Variables are dependent.') else: print('Fail to reject H0: Variables are independent.')
Observations
Test Statistic p-value Decision t-Test -0.54 0.60 Fail to reject Hn Chi-Square 7.64 0.105 Fail to reject Hn
Result
Hypothesis testing was successfully conducted using Python for both the T-Test and Chi-Square Test with
correct interpretation of p-values.
Viva Questions & Answers
Q: What is hypothesis testing?
A: A statistical procedure to test claims about a population using sample data. We decide whether to reject
the null hypothesis based on the p-value.
Q: What is a null hypothesis?
A: Hn is the default claim — typically 'no difference exists'. We only reject it if the data provides strong
evidence against it.
Q: What is a p-value?
A: The probability of getting results as extreme as observed, assuming Hn is true. A small p-value (< 0.05)
means the result is unlikely under Hn.
Q: What is a t-test?
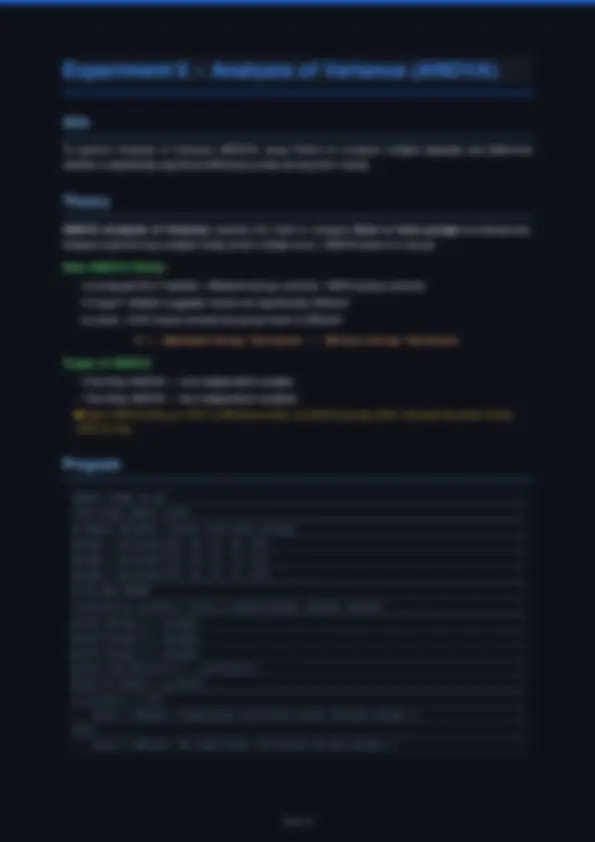
Experiment 6 – Analysis of Variance (ANOVA)
Aim
To perform Analysis of Variance (ANOVA) using Python to compare multiple datasets and determine
whether a statistically significant difference exists among their means.
Theory
ANOVA (Analysis of Variance) extends the t-test to compare three or more groups simultaneously.
Instead of performing multiple t-tests (which inflates error), ANOVA does it in one go.
How ANOVA Works
- It computes the F-statistic = Between-group variance / Within-group variance
- A large F-statistic suggests means are significantly different
- p-value < 0.05 means at least one group mean is different
F = (Between-Group Variance) / (Within-Group Variance)
Types of ANOVA
- One-Way ANOVA — one independent variable
- Two-Way ANOVA — two independent variables
n Note: ANOVA tells you THAT a difference exists, not WHICH groups differ. Use post-hoc tests (Tukey
HSD) for that.
Program
import numpy as np from scipy import stats
Sample datasets (scores from three groups)
group1 = np.array([85, 88, 90, 92, 86]) group2 = np.array([78, 80, 82, 79, 81]) group3 = np.array([90, 92, 94, 91, 93])
One-Way ANOVA
f_statistic, p_value = stats.f_oneway(group1, group2, group3) print('Group 1:', group1) print('Group 2:', group2) print('Group 3:', group3) print('\nF-Statistic:', f_statistic) print('P-Value:', p_value) if p_value < 0.05: print('\nResult: Significant difference exists between groups.') else: print('\nResult: No significant difference between groups.')
Sample Output
F-Statistic: 42. P-Value: 3.479e- Result: Significant difference exists between the group means.
Observations
Group Values Mean Group 1 85, 88, 90, 92, 86 88. Group 2 78, 80, 82, 79, 81 80. Group 3 90, 92, 94, 91, 93 92.
Result
The program successfully computes the F-statistic and p-value. Since p-value ≈ 3.48×10nn < 0.05, we
conclude that a significant difference exists between the group means.
Viva Questions & Answers
Q: What is ANOVA?
A: ANOVA (Analysis of Variance) is a statistical test that compares the means of three or more groups to
determine if at least one group mean is statistically different from others.
Q: Why is ANOVA used instead of multiple t-tests?
A: Using multiple t-tests increases the chance of Type I error (false positive). ANOVA controls this error rate
by testing all groups simultaneously.
Q: What is the F-statistic?
A: F = Between-group variance / Within-group variance. A large F means the group means differ more than
we'd expect by chance.
Q: What is the null hypothesis in ANOVA?
A: Hn: All group means are equal. Hn: At least one group mean is different.
Q: What is between-group variance?
A: The variability between the group means — how much the group averages differ from the overall average.
Q: What is within-group variance?
A: The variability of data points within each group around their own group mean. Also called residual or error
variance.
Q: What are the assumptions of ANOVA?
A: Normality (data in each group is normally distributed), Homogeneity of variance (equal variances across
groups), Independence of observations.
Q: Where is ANOVA applied in engineering?
A: Comparing material strengths from different manufacturers, testing different machine settings, quality
comparison across multiple production lines.