



ASSIGNMENT
ON
INT 312
(BIG DATA FUNDAMENTALS)
SET SB
SUBMITTED BY: SUBMITTED TO:
Cabinet Kumar Shah Prof. Mamoon Rashid
11812420 20574
A35 KOM59 School of CSE dept.









Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
this 1. As companies move past the experimental phase with Hadoop, many cite the need for additional capabilities, including _______________ a) Improved data storage and information retrieval b) Improved extract, transform and load features for data integration c) Improved data warehousing functionality d) Improved security, workload management, and SQL support View Answer 2. Point out the correct statement. a) Hadoop do need specialized hardware to process the data b) Hadoop 2.0 allows live st
Typology: Assignments
1 / 18

This page cannot be seen from the preview
Don't miss anything!
SET SB
Question 1
Question 2 Hadoop installation Show the steps and commands used in the installation of Apache Hadoop for one node cluster on your machine. Each step must be supported with screenshots of your machine with your name on terminal. Explain the functionality of each file used in the configuration of Apache Hadoop. Step 1 : if java version is not installed then we use below command $ sudo apt-get install openjdk-8-jdk
Step 2 : check java version. for that run this command $ java –version Step 3 : Run command $ readlink -f /usr/bin/java | sed "s:bin/java::" Copy the output after running this command
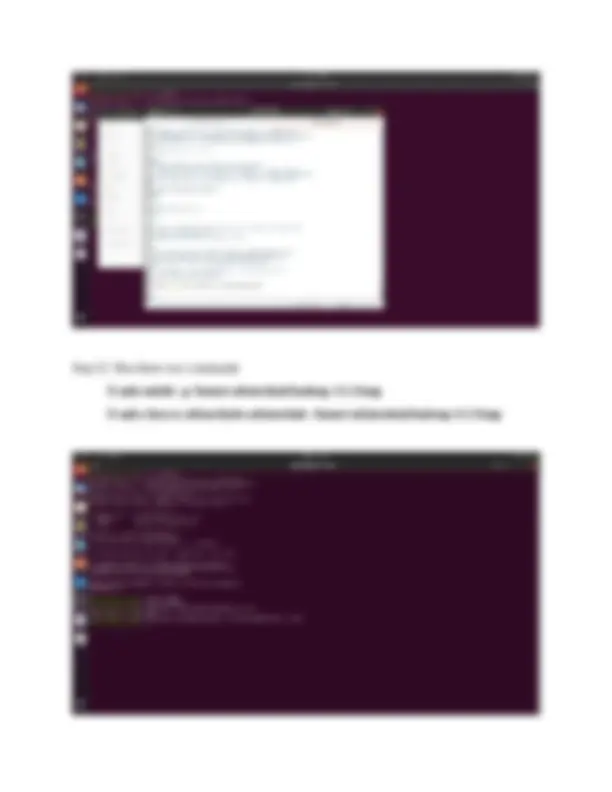
Step 6: Run the command $ ssh-keygen -t rsa -P "" Step 7 : Run the command $ cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
Step 8: Run the command $ ssh localhost Step 9: open bahsrc file with command $ gedit ~/.bashrc then paste the following below lines #HADOOP VARIABLES START export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd export HADOOP_INSTALL=/home/cabinetshah/hadoop-3.1. export PATH=$PATH:$HADOOP_INSTALL/bin export PATH=$PATH:$HADOOP_INSTALL/sbin export HADOOP_MAPRED_HOME=$HADOOP_INSTALL export HADOOP_COMMON_HOME=$HADOOP_INSTALL export HADOOP_HDFS_HOME=$HADOOP_INSTALL export YARN_HOME=$HADOOP_INSTALL export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib" #HADOOP VARIABLES END
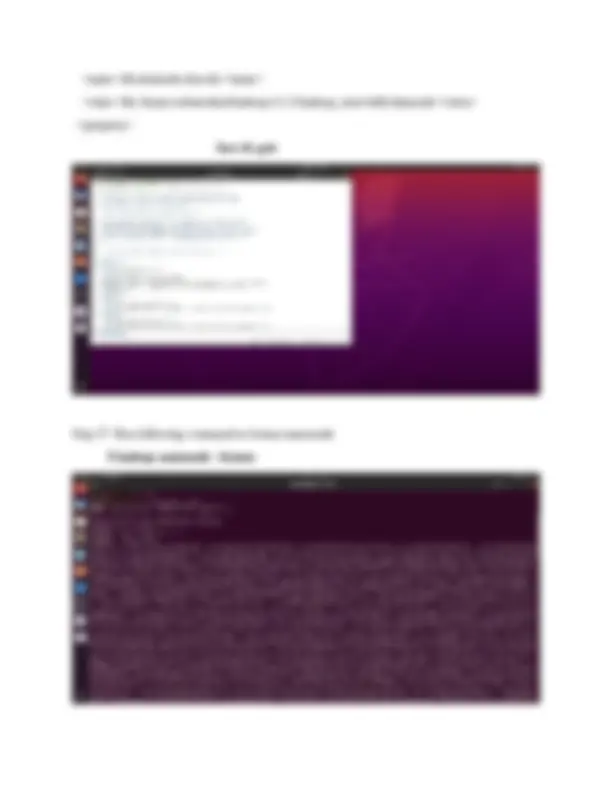
Step 12: Run these two commands $ sudo mkdir -p /home/cabinetshah/hadoop-3.1.3/tmp $ sudo chown cabinetshah:cabinetshah /home/cabinetshah/hadoop-3.1.3/tmp
Step 13: Goto hadoop 3.1.3 file etc folder hadoop folder open in texteditor core-site.xml file paste following lines inside core-site.xml file
Step 16: Goto hadoop 3.1.3 file etc folder hadoop folder open in texteditor hdfs-site.xml file paste following lines inside hdfs-site.xml file
Remarks : If we won’t get namenode after starting deamons then we just need to delete hadoop store folder & temp folder. And again we need to run all the command. We also need to check all those 4 files inside etc folder of hadoop 3.1.3 folder. Moreover we need to check bashrc file as well. Question 3
Command to move file from local to hdfs file system. Step 2 : hdfs dfs –moveFromLocal /home/cabinetshah/ /KOM59/ Command to change replication factor to 4. Step 3 : hdfs dfs –setrep –R 4 /KOM59/