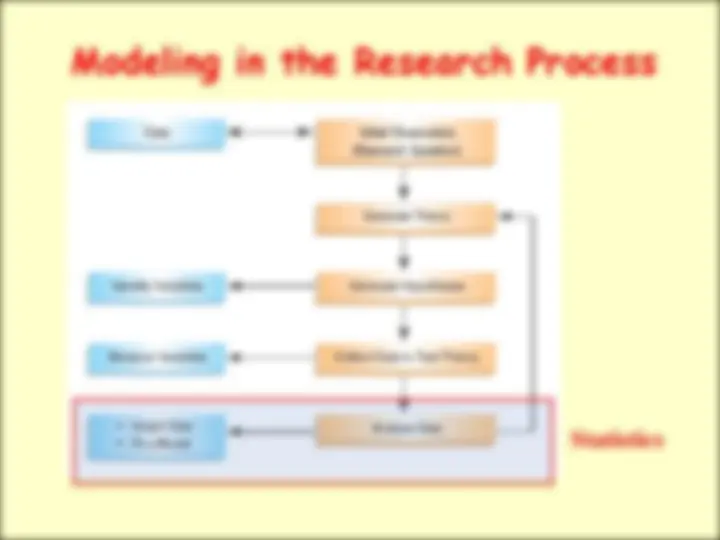
Download Assessing Variance Homogeneity and more Study notes Statistics in PDF only on Docsity!
Assessing Variance Homogeneity
Recommendations:
- Visualize data using scatterplots
- Use the Rule of Thumb: Variance Ratio (with 2 or more groups; compare largest / smallest) VR = Largest variance / Smallest variance If VR < 2, can assume homogeneity
- Levene’s Test OR Bartlett’s Test: Significant = Variances are not equal Non-Significant = Variances are equal
Use to determine which of the
two variances is larger; not just
whether they are the same.
var.test(exam ~ uni, alternative= 'two.sided’, conf.level=.95, data=rexam) F test to compare 2 variances data: exam by uni F = 1.5217, num df = 49, denom df = 49, p = 0. alternative h: ratio of variances not equal to 1 95 % confidence interval:0.8635 - 2. sample estimate: ratio of variances 1.
Variance Homogeneity- F Test
Assessing Variance Homogeneity
Bartlett’s Test:
The Bartlett's test is used to test if k samples have
equal variances (homogeneity of variances). The Bartlett's test is sensitive to departures from normality. That is, if your samples come from non- normal distributions, then a significant Bartlett's test may simply reflect the lack of normality (typeI error)
Dixon, W. J. and Massey, F.J. (1969). Introduction to
Statistical Analysis, McGraw-Hill, New York.
Variance Homogeneity – Bartlett’s Test
bartlett.test(exam ~ uni, data=rexam) Bartlett test of homogeneity of variances data: exam by uni Bartlett’s K-squared = 2.122, df = 1, p-value = 0. Bartlett test of homogeneity of variances data: numeracy by uni Bartlett's K-squared = 7.4206, df = 1, p-value = 0. bartlett.test(numeracy ~ uni, data=rexam)
Variance Homogeneity - Test
Levene's Test for Homogeneity of Variance (center = median) Df Fvalue Pr(>F) group 1 2.0886 0. 98 Total Degrees of Freedom = 100 - 1 (N – 1)
Exam Numeracy
Levene's Test for Homogeneity of Variance (center = median) Df Fvalue Pr(>F) group 1 5.366 0.02262 * 98 --- Signif. codes: 0 '’ 0.001 '’ 0.01 '’ 0.05 '.’
So, the Data are not Normal… Now What? Transform … and Verify
Logarithmic transformation fx = ln(x) OR log(x) ➢This transformation is useful when:
- High degree of variation within samples (e.g., Chl Conc.)
- Large outliers (tails) and lots of zeros ➢ Note: to log-transform data containing zeros, a small number should be added to all data points.
- With count data, add one, so that: fx = log(0+1) =
- With density data, add constant smaller than smallest possible sample, so that: fx = log(0+0.001) = - 3
Log Transformation
(x) f(x)
Log Transformation
Before After
Log Transformation (log(X
i
)): Reduces positive skew
Square Root Transformation
Square Root Transformation (√X
i
Reduces positive skew. Useful for stabilizing variance Before After
Data Transformations – For Proportions
Arcsine / Arcsine-squareroot transformation ➢This transformation is useful when dealing with proportional data (e.g., Percent Cover) ➢ Note: data must range between 0 and 1, inclusive. The constant 2 / pi scales the result of arcsin(x) [in radians] to range from 0 to 1, assuming that 0 < x < 1.
Reciprocal Transformation
Before After
(1 / X
i
): Dividing 1 by each value reduces the impact
of large scores. Beware: This transformation is non-monotonic, because it reverses the scores.
So, the Data
are not Normal…
Now What?
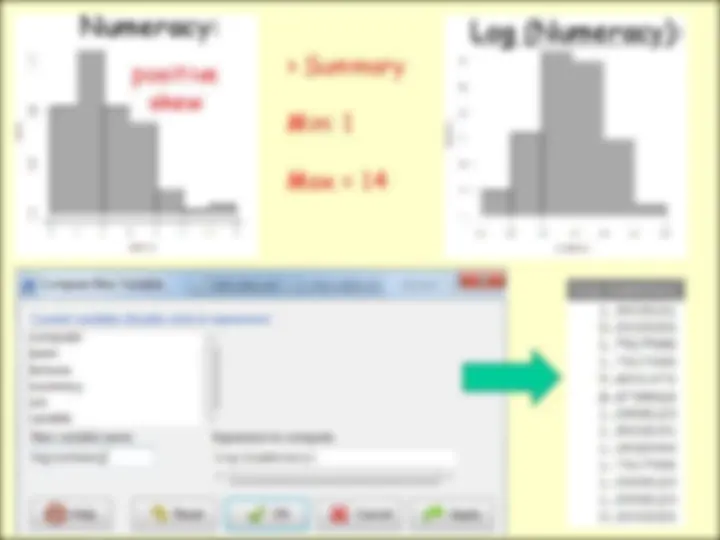
Transform the Data to Fix the Problems… in Rcmdr OR in R Data Manage variables in active data set Compute New Variable
Numeracy:
skewness skew.2SE 0.93271513942 1. kurtosis kurt.2SE 0.76349270501 0. S-W test (p < 0.001)
Log (Numeracy):
skewness skew.2SE 0.401220988 - 0. kurtosis kurt.2SE
- 0.275254548 - 0. S-W test (p = 0.003)
Take-home Lessons
Data transformations are one of the most difficult issues in parametric statistics:
- Conflicting advice: transform or not
- Conflicting results: various normality tests Recommendation: Select one approach that provides multiple evidence and come up with criteria before starting analysis Be as strict as you wish: one or more criteria But, if a test significant… cannot back-track