Download assignment 2- 1649-pass and more Assignments Information Technology in PDF only on Docsity!
ASSIGNMENT 2 FRONT SHEET
Qualification BTEC Level 5 HND Diploma in Computing Unit number and title Unit 19: Data Structures and Algorithms Submission date Date Received 1st submission Re-submission Date Date Received 2nd submission Student Name Trần Văn Tưởng Student ID GCH Class GCH1107 Assessor name Đỗ Hồng Quân Student declaration I certify that the assignment submission is entirely my own work and I fully understand the consequences of plagiarism. I understand that making a false declaration is a form of malpractice. Student’s signature Tưởng Grading grid P 4 P 5 P 6 P 7 M 4 M 5 D3 D
Summative Feedback: Resubmission Feedback:
Grade: Assessor Signature: Date: Internal Verifier’s Comments: IV Signature:
- I. Design and implementation of Stack ADT and Doubly Linked List ADT (P4)
- Stack ADT
- 1.1. Definition
- 1.2. Operation
- Doubly Linked List ADT
- II. Application(p4)
- III. Implement error handing and report test result(p5)
- Error handing
- Testing plan
- Evaluation
- IV. Discuss how asymptotic analysis can be used to assess the effectiveness od an algorithm(P6)
- Big-O Notation
- Little O Notation
- Big-Ω Notation
- Little Omega Notation
- Big-Theta Notation
- How these notations relate to the ideas of best, average and worst-case performance and example
- 6.1. Worst Case Analysis (Mostly used)
- 6.2. Best Case Analisis
- 6.3. Average Case Analysis
- 6.4. Example
- with an example(p7) V. Determine two ways in which the efficiency of an algorithm can be measured, illustrating your answer
- References
- Figure 1:Push operation................................................................................................................................................ Contents of figures
- Figure 2:Implementation push
- Figure 3:Pop operation
- Figure 4:Implementation pop
- Figure 5:Peek operation................................................................................................................................................
- Figure 6:Implementation peek
- Figure 7:isEmpty operation...........................................................................................................................................
- Figure 8:Size operation
- Figure 9:Search operation.............................................................................................................................................
- Figure 10:Implementation search.................................................................................................................................
- Figure 11:addFirst operation
- Figure 12:Implementation addFirst
- Figure 13:addLast operation
- Figure 14:Implementation addLast...............................................................................................................................
- Figure 15:addIndex operation
- Figure 16:Implementation addIndex
- Figure 17:removeFirst operation
- Figure 18:Implementation removeFirst
- Figure 19:removeLast operation
- Figure 20:Implementation removeLast
- Figure 21:removePosition operation
- Figure 22:Implementation removePosition
- Figure 23:size operation
- Figure 24:search operation
- Figure 25: Implementation search
- Figure 26:Implementation undo redo
- Figure 27: Undo Redo Stack
- Figure 28:Error handling
- Figure 29:Test case
- Figure 30:Constant time complexity
- Figure 31:Linear time complexity
- Figure 32:Logarithmic time complexity
- Figure 33:Example 2....................................................................................................................................................
I. Design and implementation of Stack ADT and Doubly Linked List ADT (P4)
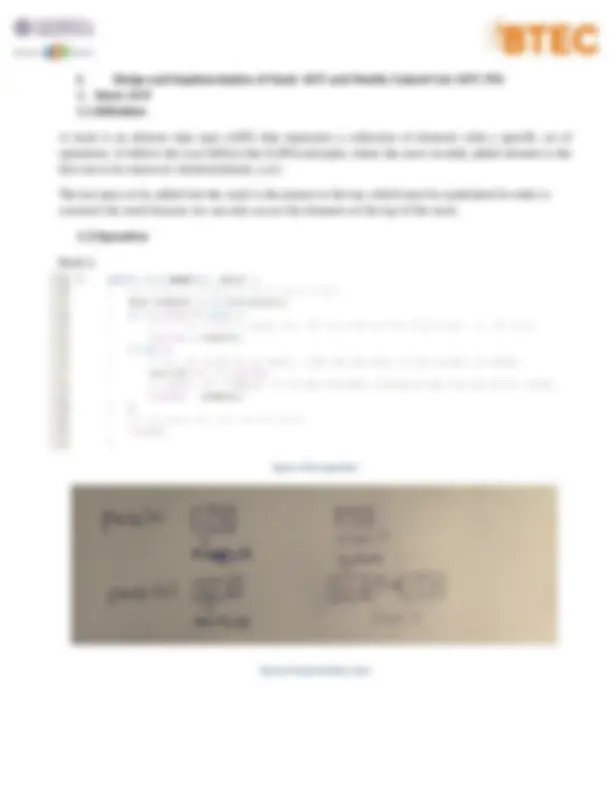
1. Stack ADT 1.1.Definition A stack is an abstract data type (ADT) that represents a collection of elements with a specific set of operations. It follows the Last-InFirst-Out (LIFO) principle, where the most recently added element is the first one to be removed. (GeeksforGeeks, n.d.) The last piece to be added into the stack is the pointer to the top, which must be maintained in order to construct the stack because we can only access the elements on the top of the stack. 1.2.Operation Push (): Figure 1 :Push operation Figure 2 :Implementation push
Figure 6 :Implementation peek isEmpty (): Figure 7 :isEmpty operation Size (): Figure 8 :Size operation Search (): Figure 9 :Search operation
Figure 10 :Implementation search
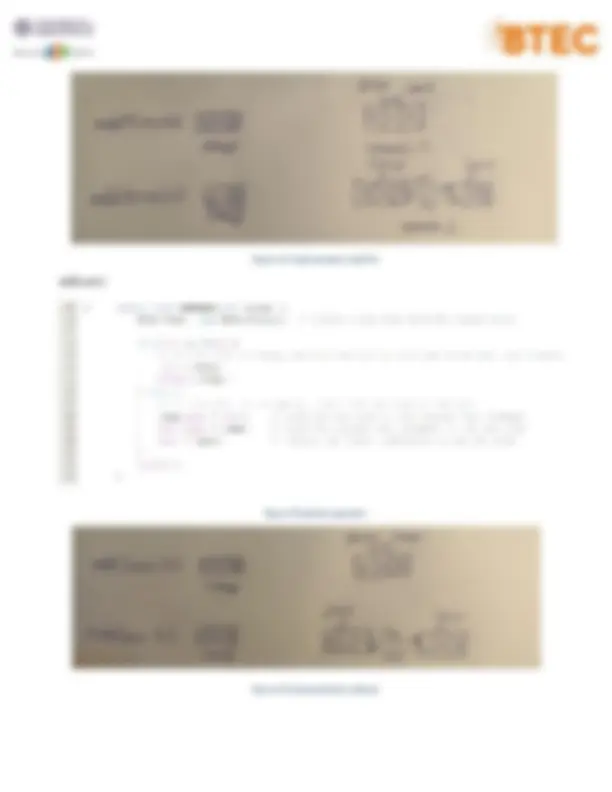
2. Doubly Linked List ADT 2.1.Definition A doubly linked list is a sophisticated kind of linked list where each node in the series has a pointer to both the preceding and subsequent nodes. Thus, a node in a doubly linked list is made up of three components: node data, a pointer to the node after it in the sequence (called the next pointer), and a pointer to the node before it (called the prior pointer). The graphic depicts an example node in a doubly linked list. 2.2.Operation addFirst(): Figure 11 :addFirst operation
addIndex(): Figure 15 :addIndex operation Figure 16 :Implementation addIndex
removeFirst(): Figure 17 :removeFirst operation Figure 18 :Implementation removeFirst removeLast(): Figure 19 :removeLast operation
Search(): Figure 24 :search operation Figure 25 : Implementation search II. Application(p4)
1. Undo-Redo feature Stack base undo redo Figure 26 :Implementation undo redo
Figure 27 : Undo Redo Stack
4 Peek() Data validatio n MyStack[] Peek() Return - 1 The same as expecte d output Passe d 5 Search() Normal MyStack: [2,3,2,1] Search(2) Return index 3 The same as expecte d output Passe d 6 Search() Data validatio n MyStack:[a,b,c] search(a) return index 0 The system is stopped Falied 7 Doubly Linked List ADT: MyLinkedLi st addFIrst() Normal MyLinkedList: [1,2,3,4,5,2] addFirst(0) MyLinkedList: [0,1,2,3,4,5,2] Size = 7 The same as expecte d output Passe d 8 addLast() Normal MyLinkedList: [1,2,3,4,5,2] addLast(0) MyLinkedList: [1,2,3,4,5,2,0] Size = 7 The same as expecte d output Passe d 9 addIndex() Normal MyLinkedList: [0,1,2,3,4,5,2,0] addIndex(value 10, position 2) MyLinkedList: [0,1,10,2,3,4,5,2, 0]; Size = 9 The same as expecte d output Passe d 10 removeFirst() Normal MyLinkedList: [0,1,10,2,3,4,5, ,0] removeFirst() MyLinkedList: [1,10,2,3,4,5,2,0] Size = 8 The same as expecte d output Passe d 11 removeLast() Normal MyLinkedList: [1,10,2,3,4,5,2, ] removeLast() MyLinkedList: [1,10,2,3,4,5,2] Size = 7 The same as expecte d output Passe d 12 removePositio n() Normal MyLinkedList: [1,10,2,3,4,5,2] removePosition( 3 ) MyLinkedList: [1,10,2,4,5,2] Size = The same as expecte d output Passe d 13 Search() Normal MyLinkedList: [1,10,2,4,5,2] Return index 5 The same as Passe d
Search(2) expecte d output 14 Search() Data validatio n MyLinkedList: [a,b,c] Search(a) Return index 0 The system is stopped Failed 15 Stack based Undo-redo Undo() Normal undoStack = [1,2,3] undo() Return 3 undoStack = [1,2] redoStack = [3] The same as expecte d output Passe d 16 Normal undoStack = [1,2] undo() Return 2 undoStack = [1] redoStack = [3,2] The same as expecte d output Passe d 17 Normal undoStack[] undo() Return - 1 The same as expecte d output Passe d 18 Redo() Normal undoStack= [1] redoStack= [3,2] redo() undoStack = [1,2]; redoStack = [3]; The same as expecte d output Passe d 19 Normal undoStack= [1,2] redoStack= [3,2] redo() undoStack = [1,2,3] redoStack = [] The same as expecte d output Passe d 20 Normal undoStack= [1,2,3] redoStack=[] redo() Return - 1 The same as expecte d output Passw d Figure 29 :Test case
3. Evaluation After 20 test plans, 18 out of 20 test plans were successful, indicating that the majority of the stack operations, doubly linked list operation and undo-redo operation are functioning correctly.
3. Big-Ω Notation Omega notation is a mathematical notation used in computer science to describe the asymptotic lower bound of an algorithm's running time. This means that the Omega notation for an algorithm describes the minimum amount of time it will take to run, regardless of the input. The Omega notation is similar to Big O notation, but it is used to describe the best-case running time of an algorithm, rather than the worst-case running time. This means that the Omega notation for an algorithm describes the lower bound on the amount of time it will take to run, regardless of the input. Mathematical Representation of Omega notation: Ω(g(n)) = {f(n): there exist positive constants c and n0 such that 0 ≤ cg(n) ≤ f(n) for all n ≥ n0} The Omega notation is written as Ω(f(n)), where f(n) is a function that describes the running time of the algorithm. For example, if the running time of an algorithm is Ω(n), then this means that the algorithm's running time is at least n for all inputs of size n. (GeeksforGeeks, 2023) 4. Little Omega Notation When describing the asymptotic efficiency of an algorithm, one uses the small ω notation. When n is outside of N, it is written ω(f(n)) (sets other than the set of natural numbers, N, are used occasionally). The set of functions {g(n):∀c∈N, c>0, ∃n0∈N ∀n≥n0, 0≤cf(n)≤g(n)} is represented by the expression ω(f(n)). To put it simply, functions that are bounded cf(n) populate this collection. A lower bound that is asymptotic is this. This constraint is not asymptotically tight because it holds for all values of c. This needs to be contrasted with the large omega symbol. Instead of writing h(n)∈ω(f(n)), we write h(n)=ω(f(n)) for set membership. (Watson ,2023) 5. Big-Theta Notation Theta notation is a mathematical notation used to describe the tight bound or average-case scenario of an algorithm's time complexity or space complexity. It provides a way to analyze and compare the average behavior of different algorithms. In Theta notation, the complexity of an algorithm is represented as Θ(g(n)), where "g(n)" is a mathematical function that defines both the upper and lower growth rates of the algorithm. It signifies that the algorithm's running time or space complexity grows at the same rate as the function g(n), up to a constant factor. Mathematical Representation of Theta notation:
Θ (g(n)) = {f(n): there exist positive constants c1, c2 and n0 such that 0 ≤ c1 * g(n) ≤ f(n) ≤ c2 * g(n) for all n ≥ n0} Note: Θ(g) is a set The above expression can be described as if f(n) is theta of g(n), then the value f(n) is always between c1* g(n) and c2 * g(n) for large values of n (n ≥ n0). The definition of theta also requires that f(n) must be non- negative for values of n greater than n0. (GeeksforGeeks, 2023)
6. How these notations relate to the ideas of best, average and worst-case performance and example 6.1.Worst Case Analysis (Mostly used) We determine the upper bound on an algorithm's execution time in the worst-case scenario. The scenario that results in the execution of the greatest number of operations must be identified. The worst-case scenario for linear search is when the element (x) that has to be sought does not exist in the array. The search() function compares x, in the absence of x, one by one with each element of arr[]. As a result, the linear search's worst-case time complexity would be O(n) (GeeksforGeeks, 2023). 6.2.Best Case Analisis We determine the lower constraint on an algorithm's execution time in the best-case analysis. We need to identify the scenario that necessitates the execution of a minimum number of operations. The best case scenario in the linear search issue is when x is found at the initial location. In the optimal scenario, there are always the same number of operations—it is not based on n. Thus, in the optimal scenario, temporal complexity would be Ω(1) (GeeksforGeeks, 2023). 6.3.Average Case Analysis We determine the computing time for each and every input in the average case analysis by taking into account every potential input. Divide the total number of inputs by the sum of all the calculated values. The distribution of cases must be understood (or predicted). Let us assume uniform distribution for all situations (including the case of x not being present in the array) in the linear search problem (GeeksforGeeks, 2023). 6.4.Example Figure 30 :Constant time complexity