



11
1
Backpropagation
Docsity.com




















Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
An in-depth explanation of the backpropagation algorithm used in neural networks. It includes diagrams and formulas for calculating sensitivities, weight updates, and transfer function derivatives. The document also includes an example of function approximation using a sine wave network.
Typology: Slides
1 / 29

This page cannot be seen from the preview
Don't miss anything!
Docsity.co
1
2
3
Docsity.co
a
1 1
hardlim
1
0
(
)
=
1
2
a
2 1
hardlim
0
1
(
)
=
p
1
a
1 2
n
1
2
Inputs
p 2 - 1 a 1
1
n
1
1
a
2
1
n
2
1
1
1
AAAA
Σ
AA
Σ
AA
Σ
AA
1
AA AAAA
0
0
1
1 1
Individual Decisions
AND Operation
Docsity.co
3
4
a
3 1
hardlim
1 0
(
)
=
a
4 1
hardlim
0 1
(
)
=
p
1
a
1
4
n
1
4
Inputs
p
2
1
a
1
3
n
1
3
a
2
2
n
2
2
1
1
AAAA
Σ
AA
Σ
AA
Σ
AA
1
AA AAAA
0
0 1
1 1
Individual Decisions
AND Operation
Docsity.co
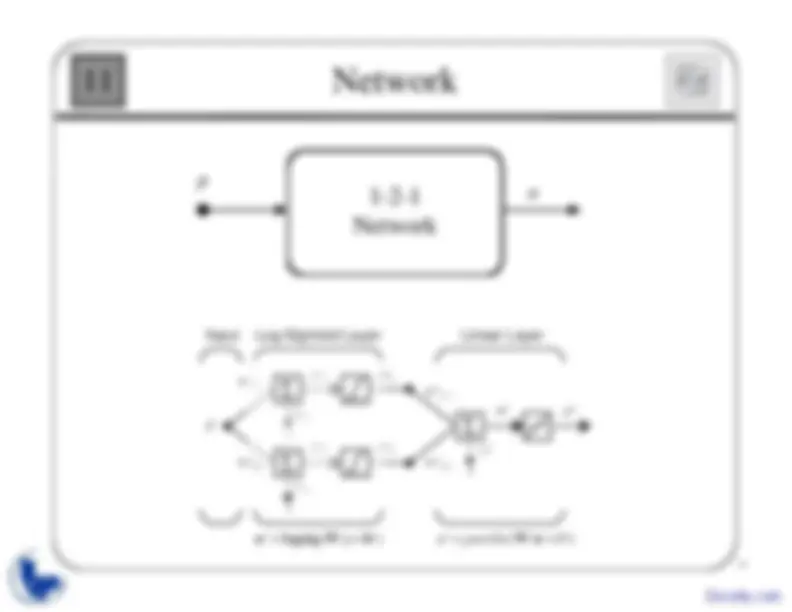
p
a
1 2
n
1
2
Input
w
1
1,
a
1
1
n
1
1
w
2
1,
b
1 2
b
1 1
b
2
a
2
n
2
1 1
1
AAAA
Σ
AAAA
Σ
AA
Σ
w
1
2,
w
2
1,
AAAA AAAA
Log-Sigmoid Layer
AA
Linear Layer
a
1
=
logsig
(
W
1
p
b
1
)
a
2
=
purelin
(
W
2
a
1
b
2
)
f
1
n
e
n
f
2
n
(
)
n
=
w
1 1
,
1
w
2 1
,
1
b
1 1
b
2 1
w
1 1
,
2
w
1 2
,
2
b
2
0
=
Docsity.co
0
1
2
0 1 2 3
Docsity.co
m
1
m
1
m
1
(
)
=
m
0 2
…
M
1
,
,
,
=
0
=
M
=
Docsity.co
1
1
{
,
}
,
,
,
F
(
)
E e
2
]
[
=
E
t
a
(
)
2
]
[
=
F
[
=
E
(
)
T
(
) ]
[
=
F ˆ
(
)
k
(
)
k
(
)
(
)
T
k
(
)
k
(
)
(
)
T
k
(
)
k
(
)
=
=
w
i
j
,
m
k
w
i j
,
m
k
α
w ∂
i
j
,
m
b
i m
k
b
i m
k
α
b
i m
Docsity.co
n
i m
w
i
j
,
m
a
j m
1
j
1
=
S
m
1
∑
b
i m
n
i m
w
i
j
,
m
a
j m
1
n
i m
b
i m
s
i m
n
i m
w ∂
i
j
,
m
s
i m
a
j
m
1
b
i m
s
i m
Docsity.co
w
i j
,
m
k
w
i j
,
m
k
α
s
i m
a
j m
1
b
i m
k
b
i m
k
α
s
i m
m
k
1
(
)
m
k
(
)
T
=
m
k
1
(
)
m
k
(
)
α
m
=
s
m
n
m
n
1 m
n
2 m
n
S
m
m
Docsity.co
11
s
m
n
m
n
m
1
n
m
T
n
m
1
F
˙
m
n
m
W
m
1
T
n
m
1
m
m
m
m
1
M
M
1
→
→
→
→
Docsity.co
s
i M
n
i M
t
a
T
t
a
n
i M
t
j
a
j
2
j
1
=
S
M
∑
n
i M
t
i
a
i
a
i
n
i M
M
2
M
M
(
)
(
)
=
a
i
n
i M
a
i M
n
i M
f
M
n
i
M
n
i M
f
˙
M
n
i
M
s
i M 2 t i a i
f
M
n
i M
Docsity.co
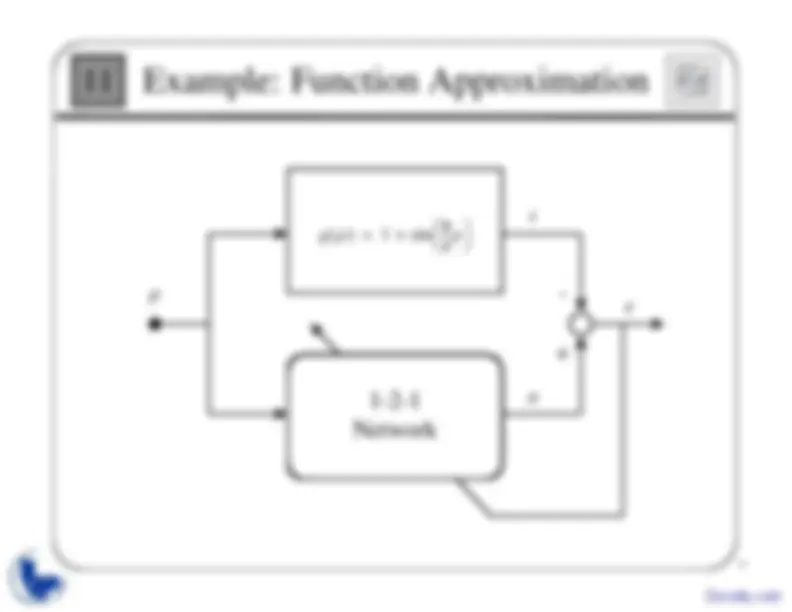
g p
4 --π
p
sin
t
a
e
p
Docsity.co
p
a
1 2
n
1
2
Input
w
1
1,
a
1
1
n
1
1
w
2
1,
b
1 2
b
1 1
b
2
a
2
n
2
1 1
1
AAAA
Σ
AAAA
Σ
AA
Σ
w
1
2,
w
2
1,
AAAA AAAA
Log-Sigmoid Layer
AA
Linear Layer
a
1
=
logsig
(
W
1
p
b
1
)
a
2
=
purelin
(
W
2
a
1
b
2
)
a
p
Docsity.co