



Chapter 6
Bivariate Correlation & Regression
6.1 Scatterplots and Regression Lines
6.2 Estimating a Linear Regression Equation
6.3 R-Square and Correlation
6.4 Significance Tests for Regression Parameters




































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
The concept of regression analysis, focusing on the use of scatterplots and linear regression to identify the relationship between two variables, x and y. It covers the calculation of regression lines, prediction equations, and error terms, as well as the importance of the least squares criterion in determining the 'best fit' line. The document also discusses the concept of r-square and its role in measuring the proportion of variance in y that can be explained by its linear relationship with x.
Typology: Study notes
1 / 46

This page cannot be seen from the preview
Don't miss anything!
Visually display relation of two variables on X-Y coordinates
50 U.S. States Y = per capita income X = % adults with BA degree
Positive relation: increasing X related to higher values of Y
CT
MS
Use linear regression to estimate “best-fit” line thru points:
How can we use sample data on the Y & X variables to estimate population parameters for the best-fitting line?
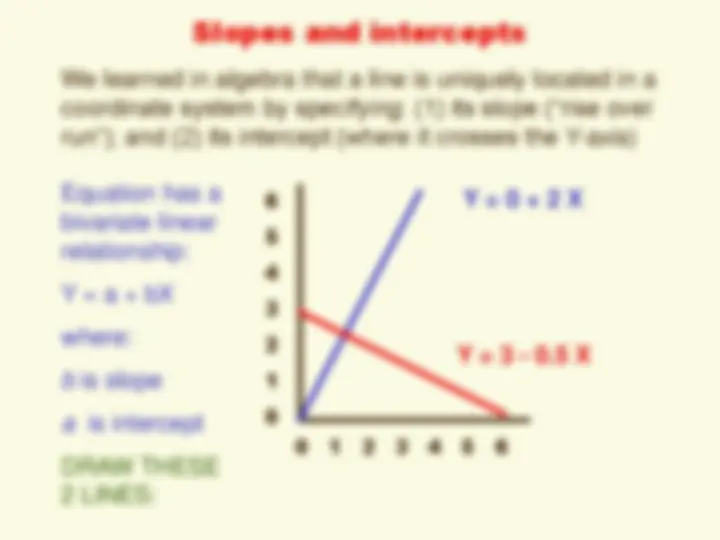
We learned in algebra that a line is uniquely located in a coordinate system by specifying: (1) its slope (“rise over run”); and (2) its intercept (where it crosses the Y-axis)
Equation has a bivariate linear relationship:
Y = a + bX
where:
b is slope
a is intercept
DRAW THESE 2 LINES:
0 1 2 3 4 5 6
6 5 4 3 2 1 0 Y = 0 + 2 X
Y = 3 - 0.5 X
The regression error, or residual, for the ith case is the difference between the value of the dependent variable predicted by a regression equation and the observed value of that case. Subtract the prediction equation from the linear regression model to identify the ith case’s error term
Yi a bYXXi ei
Yi a bYXXi ˆ^
i Yi ei Y ˆ
An analogy: In weather forecasting, an error is the difference between the weatherperson’s predicted high temperature for today and the actual high temperature observed today: Observed temp 86º - Predicted temp 91º = Error -5º
Scatterplot for state Income & Education has a positive slope
Ordinary least squares (OLS) a method for estimating regression equation coefficients -- intercept (a) and slope (b) -- that minimize the sum of squared errors
To plot the regression line, we apply a criterion yielding the “best fit” of a line through the cloud of points
OLS estimator of the intercept, a
The OLS estimator for the intercept (a) simply changes the mean of Y (the dependent variable) by an amount equaling the regression slope’s effect for the mean of X:
a Y bX
Two important facts arise from this relation:
(1) The regression line always goes through the point of both variables’ means!
(2) When the regression slope is zero, for every X we only predict that Y equals the intercept a , which is also the mean of the dependent variable!
a Y
X
Use these two bivariate regression equations, estimated from the 50 States data, to calculate some predicted values:
Xi = 12%: Y=____________ Xi = 28%: Y=____________
What predicted poverty % for: Xi = 55%: Y=____________ Xi = 70%: Y=____________
Every regression line through a scatterplot also passes
We can use this relationship to divide the variance of Y into a double deviation from:
(1) the regression line (2) the Y-mean line Then calculate a sum of squares that reveals how strongly Y is predicted by X.
In Income-Education scatterplot, show the difference between the mean and Illinois’ Y-score as the sum of two deviations:
IL
Yi Yi ˆ
Y ˆ i Y
Error deviation of observed and predicted scores
Regression deviation of predicted score Y from the mean
^ ( Y Y )^2 ( Y Y ˆ )^2 ( Y ˆ Y )^2 i i i i
Each result of the preceding partition has a name:
TOTAL sum of squares
REGRESSION sum of squares
ERROR sum of squares
SSTOTAL = SSERROR + SSREGRESSION
The relative proportions of the two terms on the right indicate how well or poorly we can predict the variance in Y from its linear relationship with X
The SSTOTAL should be familiar to you – it’s the numerator of the variance of Y (see the Notes for Chapter 2). When we partition the sum of squares into the two components, we’re analyzing the variance of the dependent variable in a regression equation.
Hence, this method is called the analysis of variance or ANOVA.
If we had no knowledge about the regression slope (i.e., bYX = 0 and thus SSREGRESSION = 0), then our only prediction is that the score of Y for every case equals the mean (which also equals the equation’s intercept a ; see slide #10 above).
But, if bYX ≠ 0, then we can use information about the i th case’s score on X to improve our predicted Y for case i. We’ll still make errors, but the stronger the Y-X linear relationship, the more accurate our predictions will be.
i
i i
i YX i
Find the R^2 for these 50-States bivariate regression equations
SSREGRESSION = 409. SSERROR = 342. SSTOTAL = 751.
R^2 = _________
SSREGRESSION = ______ SSERROR = 321. SSTOTAL = 576.
R^2 = _________
Here are some R^2 problems from the 2008 GSS
SSREGRESSION = 67, SSERROR = 2,861, SSTOTAL = _________
R^2 = _________
SSREGRESSION = 1,511, SSERROR = _____________ SSTOTAL = 10,502,
R^2 = _________