



2-Hardware Design Basics of
Embedded Processors
(cont.)
1
Docsity.com













Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
These are the Lecture Slides of High Performance Embedded Systems Design which includes Performance Analysis, Digital Camera Case Study, Simple Digital Camera, Requirements Specification, Design, Four Implementations, Custom, Standard, Memory etc. Key important points are: Basics, Hardware Design, Combinational Logic, Sequential Logic, Custom Single Purpose, Single Purpose Processor, Inputs, Controller and Datapath, Templates, Algorithm
Typology: Slides
1 / 21

This page cannot be seen from the preview
Don't miss anything!
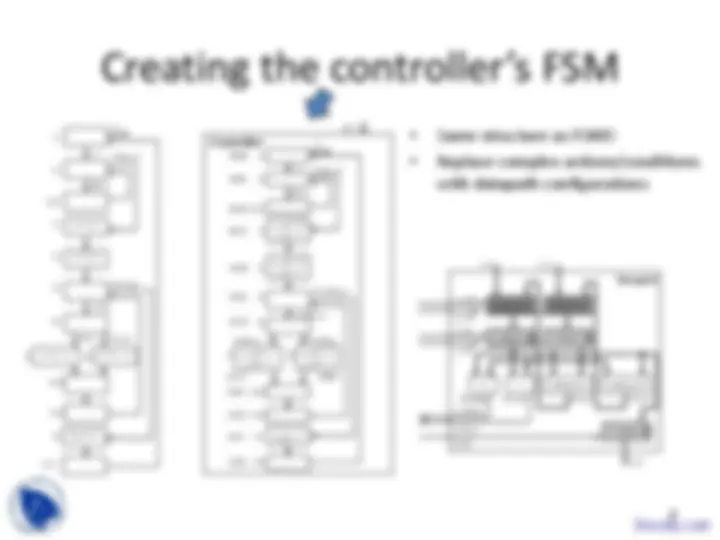
machine with datapath
conversion
Assignment statement
a = b
next statement
Loop statement
while (cond) {
loop-body- statements
}
next statement
Branch statement
if (c1)
c1 stmts
else if c c2 stmts
else
other stmts
next statement
sources
control input and output
7: y = y -x 8: x = x - y
x!=y
5: !(x!=y)
x<y !(x<y)
3: x = x_i
4: y = y_i
!go_i
!(!go_i)
d_o = x
subtractor subtractor 5: x!=y 6: x<y 8: x-y 7: y-x
x_i y_i
d_o
0: x 0: y
9: d
n-bit 2x1 n-bit 2x
x_sel
y_sel x_ld
y_ld
x_neq_y
x_lt_y d_ld
5: x!=y
7: y = y -x 8: x = x - y
x!=y
5: !(x!=y)
x<y !(x<y)
3: x = x_i
4: y = y_i
!go_i
!(!go_i)
d_o = x
y_sel = 1 y_ld = 1
7: x_sel = 1 x_ld = 1
x_neq_y
!x_neq_y
x_lt_y !x_lt_y
d_ld = 1
x_sel = 0 3: x_ld = 1
y_sel = 0 4: y_ld = 1
!go_i
!(!go_i)
go_i
subtractor subtractor 5: x!=y 6: x<y 8: x-y 7: y-x
x_i y_i
d_o
0: x 0: y
9: d
n-bit 2x1 n-bit 2x
x_sel
y_sel x_ld
y_ld
x_neq_y
x_lt_y d_ld
5: x!=y
example
Inputs Outputs
RT-level custom single-purpose processor
design (cont’)
rdy_in rdy_out
data_hi data_lo
data_out_ld^ data_hi_ld data_out data_lo_ld
clk
to all registers
data_out
Bridge