



Introduction to Neural Networks
and Machine Learning
Lecture 10: The Bayesian way to fit models
Docsity.com







Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
An introduction to the bayesian framework for model fitting in neural networks and machine learning. The bayesian approach assumes a prior distribution for all parameters and combines it with the likelihood term to obtain a posterior distribution. The example of coin tossing is used to illustrate the concept. The document also discusses the advantages of using a distribution over parameter values and the use of bayes theorem and maximum likelihood learning.
Typology: Slides
1 / 13

This page cannot be seen from the preview
Don't miss anything!
have a prior distribution for everything.
Some problems with picking the parameters that are most likely to generate the data
got 1 head?
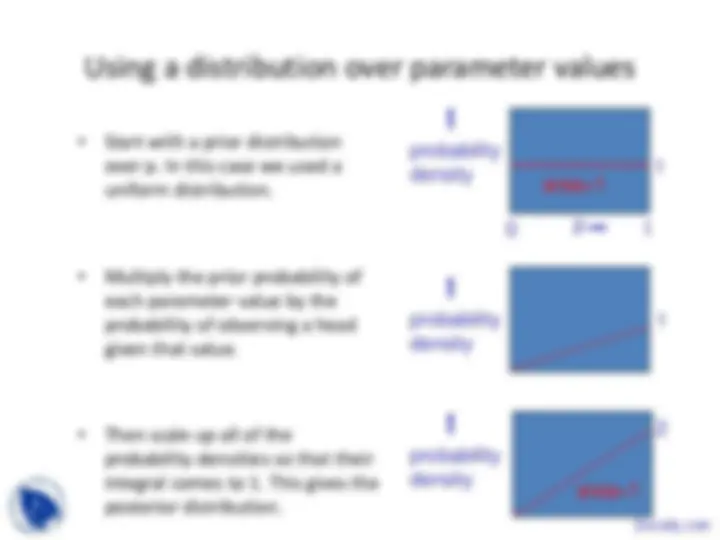
Using a distribution over parameter values
probability density
p
area=
area=
0 1
1
1
2
probability density
probability density
Lets do it another 98 times
probability density
p
area=
0 1
1
2
Bayes Theorem
∫
W
p W p D W
p D
p W p D W p W D
p D p W D p D W p W p D W
Prior probability of weight vector W
Posterior probability of weight vector W given training data D
Probability of observed data given W
joint probability
conditional probability
Why we maximize sums of log probs
p ( D | W ) p ( d | W ) c
= ∏ c
log p ( D | W ) log p ( d | W ) c
= ∑ c
A even cheaper trick
weight vectors
very widely used for fitting models in statistics.
log p ( D | W ) log p ( D | W ) c
= ∑ c
Supervised Maximum Likelihood Learning
squared errors is exactly the same as finding a W that maximizes the log probability that the model would produce the desired outputs on all the training cases.