Download BIG DATA ANALYTICS (BDA) and more Summaries Advanced Data Analysis in PDF only on Docsity!
Essential parts of a video lecture
**1. Objective
- Lecture Learning Outcomes
- Introduction to Hadoop
- Data: The Treasure Trove
- Why Hadoop?
- Why Not RDBMS?
- Reflection spot
- Lecture Outcome Revisited
- Lecture Level practice Problems (LLPs)
- Further Reading** 2
This is the introduction part of Hadoop where you can understand the concept of Hadoop and RDBMS
Objective
- Today, Big Data seems to be the buzz word! Enterprises, the world over, are beginning to realize that tiler, is a huge volume of untapped information before them in the form of structured, semi-structured, and unstructured data. This varied variety of data is spread across the networks.
- Let us look at few statistics to get an idea of the amount of data which gets generated every day, ever, minute, and every second.
- Every day: (a) NYSE (New York Stock Exchange) generates 1.5 billion shares and trade data. (b) Facebook stores 2.7 billion comments and Likes. (c) Google processes about 24 petabytes of data.
Introduction to Hadoop
- Every minute: (a) Facebook users share nearly 2.5 million pieces of content. (b) Twitter users tweet nearly 300,000 times. (c) Instagram users post nearly 220,000 new photos. (d) YouTube users upload 72 hours of new video content. (e) Apple users download nearly 50,000 apps. (f) Email users send over 200 million messages. (g) Amazon generates over $80,000 in online sales. (h) Google receives over 4 million search queries
- Every second:
- (a) Banking applications process more than 10,000 credit card transactions.
Introduction to Hadoop
Data: The Treasure Trove
- Ever wondered why Hadoop has been and is one of the most wanted technologies!! The key consideration (the rationale behind its huge popularity) is:
- Its capability to handle massive amounts of data, different categories of data — fairly quickly 1. Low cost Hadoop is an open-source framework and uses commodity hardware (commodity hard-ware is relatively inexpensive and easy to obtain hardware) to store enormous quantities of data**.
- Computing power:** Hadoop is based on distributed computing model which processes very large volumes of data fairly quickly. The more the number of computing nodes, the more the processing power at hand. 3. Scalability: This boils down to simply adding nodes as the system grows and requires much less administration
WHY HADOOP?
Reflection Spot - 1
Having discussed some content, here is reflection spot Question-1: Point out the correct statement. a) Hadoop is an ideal environment for extracting and transforming small volumes of data b) Hadoop stores data in HDFS and supports data compression/decompression c) The Giraph framework is less useful than a MapReduce job to solve graph and machine learning d) None of the mentioned
Answer:b
WHY HADOOP?
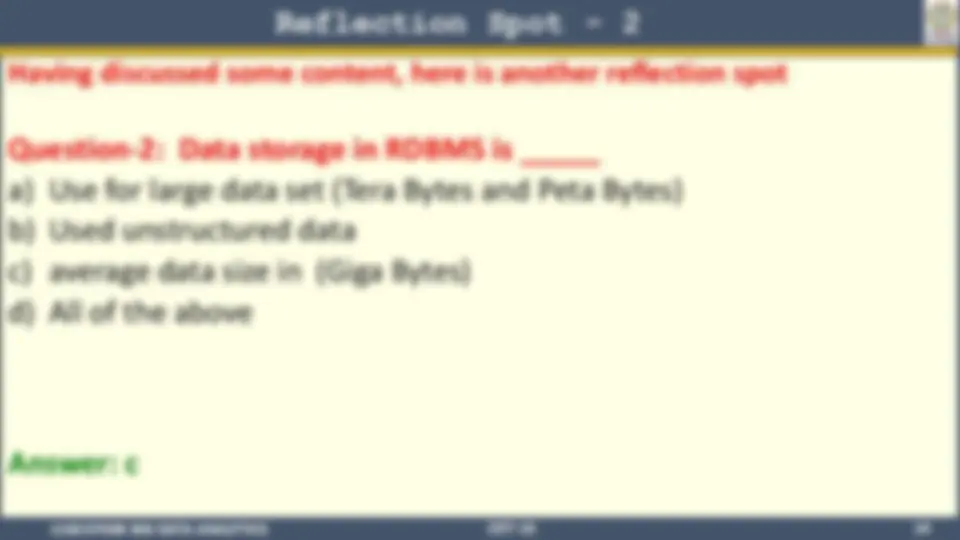
Reflection Spot - 2
Having discussed some content, here is another reflection spot
Question-2: Data storage in RDBMS is _____
a) Use for large data set (Tera Bytes and Peta Bytes)
b) Used unstructured data
c) average data size in (Giga Bytes)
d) All of the above
Answer: c
Lecture Outcome Revisited
Having completed the discussion on Introduction to Hadoop , now, students should be able to… LO1:Understand what is Hadoop? LO2: Understand the why Hadoop and not RDBMS?
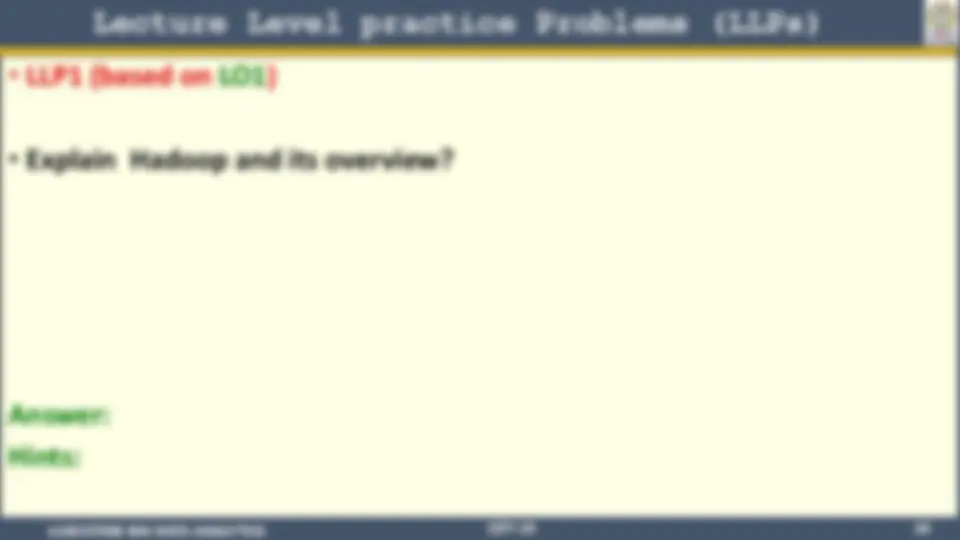
Lecture Level practice Problems (LLPs)
LLP2 ( based on LO2) Explain RDBMS? And compare RDBMS with Hadoop? Answer: Hints: