


CMPSCI 689: Machine Learning
Sridhar Mahadevan
University of Massachusetts
CMPSCI 689 – p.1/26















Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Material Type: Assignment; Professor: Mahadevan; Class: Machine Learning; Subject: Computer Science; University: University of Massachusetts - Amherst; Term: Spring 2005;
Typology: Assignments
1 / 26

This page cannot be seen from the preview
Don't miss anything!
Sridhar Mahadevan
University of Massachusetts
Biology
: Brain, Development, Evolution, Genetics,
Neuroscience.
Information Theory
Coding Theory, Entropy.
Linguistics
: Grammars, Language acquisition
Mathematics
Calculus, Linear Algebra, Optimization
Psychology
: Analogy, Concept Learning, Curiosity,
Discovery, Memory, Reinforcement
Philosophy
: Causality, Induction, Theory Formation
Statistics
Probability Distributions, Estimation,
Hypothesis Testing.
CMPSCI 689 – p.5/
Parametric learning
The learner assumes that the data is coming from aspecific distribution
x
Examples: Multivariate gaussian, Hidden markovmodel, Dynamic Bayes Nets etc.
Nonparametric learning
The learner has no knowledge of the specificdistribution, but may make other assumptions (e.g,.stationarity).
Examples: Perceptron, Support Vector Machine,Kernel density estimation.
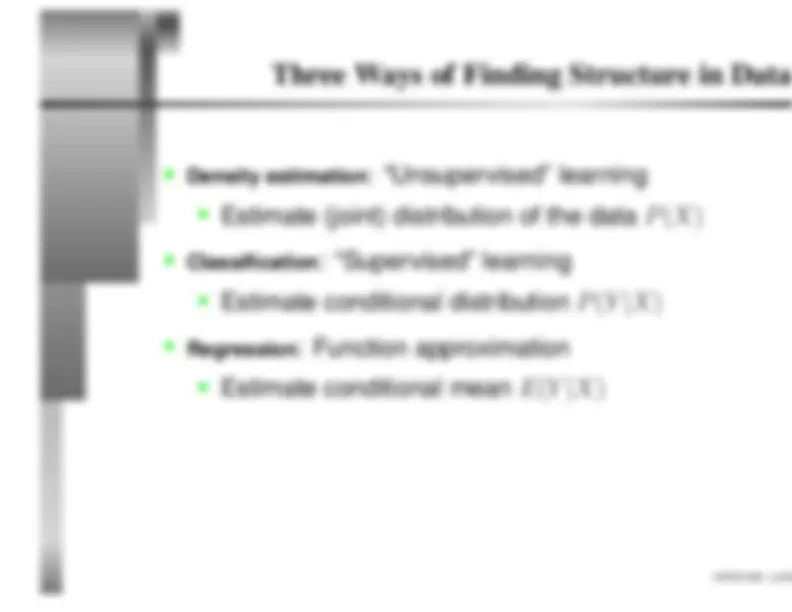
Density estimation
: “Unsupervised” learning
Estimate (joint) distribution of the data
Classification
: “Supervised” learning
Estimate conditional distribution
Regression
: Function approximation
Estimate conditional mean
is a vector space with a norm or
inner product defined on it. (a)
Euclidean distance:
d
x, x
m
i
x
i
x
mi
2
(b)
Mahalanobis distance: d
x, x
m
x
x
m
T
−
1
x
x
m
(c)
KL divergence:
d
p, q
x
p
x
) log
p
(
x
)
q
(
x
)
e.g., text, bioinformatics, sensor networks. (a) Define a
featurizer
φ
x
e.g. a
kernel
function
k
x, y
φ
x
φ
y
CMPSCI 689 – p.10/
T M
A web site is an
authority
if many sites link to it. A web site is a
hub
if it links to
many sites.
Google computes a ranking
x
1
,... , x
N
of authorities and
y
1
,... , y
M
of hubs.
Initialize
x
0 i
is the number of links pointing to
i
and
y
0 i
is the number of links going
out of
i
.
But, not all links should be weighted equally. For example, links from authorities (orhubs) should count more.
x
1 i
=
X
j links to i
y
0 j
=
A
T
y
0
and
y
1 i
=
X
i links to j
x
0 j
=
Ax
0
x
ki
=
A
T
A x
k
−
1
and
y
ki
=
AA
T
y
k
−
1
This is an iterative singular value decomposition (SVD), and Google
T M
is solving
the world’s largest SVD problem over a matrix
A
of size
4
billion by
4
billion!
CMPSCI 689 – p.11/
Posterior
Likelihood
Prior
Evidence
c
i
c
i
c
i
where the evidence(denominator) term can be computedas
i
c
i
c
i
“The countdown resumed Tuesday for the launch ofNASA’s controversial Cassini probe to Saturn afterengineers fixed a technical problem at the launch pad.NASA has rescheduled the beginning of the $3.4 billionmission....”Attributes:
a
1
“the”,
a
2
“countdown”, ...,
a
93
launch.
How many probabilities do we need? Assume a maximumdocument length of
words, and
possible categories.
Assuming
words in English, we get
million!!!
Word probabilities are
conditionally independent
given
the category.
Word probabilities are
marginally independent
of
location in the document.
a
i
c
j
a
k
c
j
This is called the “bag of words” representation in IR.
So, in our example, this means that number ofprobabilities needed is
CMPSCI 689 – p.16/
Bayesian methods require computing the
likelihood
function
x
y
and the
marginal
y
Exact
inference requires enumerating all the possible
hypotheses efficiently, e.g, Pearl’s belief propagationalgorithm or the sum-product algorithm.
Approximate
inference restricts the hypotheses
considered, e.g,. maximum likelihood or Monte-Carlomethods.
Primal Form:
Size of the hypothesis is proportional to number ofattributes.
Perceptron:
h
x
Sgn
i
w
i
x
i
Dual Form:
Kernel methods represent a hypothesis as a linearcombination of training examples h
x
i
α
i
x, x
i
An interesting
sparsity
property further reduces the
number of parameters to (sometimes)
constant
size!
See web page www-edlab.cs.umass.edu/cs
Instructor:
My office hours: T/Th 10:30-12, 204
Ed lab account on elnux*.cs.umass.edu (MATLAB,Bayes Net Toolbox)