



ii
In the name of ALLAH the most beneficent the ever merciful
docsity.com

















































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
This report is for final year project to complete degree in Computer Science. It emphasis on Applications of Computer Sciences. It was supervised by Dr. Abhisri Yashwant at Bengal Engineering and Science University. Its main points are: Buffer, Overflow, Communication, Ports, Protocol, Controlling, Data, Execution, Instructions, Shell, Code
Typology: Study Guides, Projects, Research
1 / 60

This page cannot be seen from the preview
Don't miss anything!
ii
iii
viii
Buffer overflow is a problem caused due to the unprotected memory in a program. Buffer overflow causes the unauthorized access for an attacker, arbitrary code could be run and a number of other security hazards are created. There is not a single method for the sake of detecting this problem in a program and requires a human expert for the detection of this problem. Every program has its own structure and memory space therefore there is no single security program that could be used to detect and exploit buffer overflow vulnerability. This project was selected due to the increasing risk of computer security. It was to learn understand and develop techniques that would help prevent vulnerabilities in software. Software industry needs to improve their quality for which a great need of training the programmers is needed. This thesis will help those programmers understand why their programs could be exploited and how to prevent this. This problem could be overcome by increasing the awareness of the programmers and providing them knowledge regarding security concerns. With this the programmers will stop the programming practice causing security problems in the field of computer security. After reading this thesis a programmer will get a good idea about how buffer overflow could be prevented and which type of security checks should be implemented.
This thesis carries a lot of knowledge regarding how programming could be done safely. The programmers will get the idea about why a program having no error could be vulnerable. This knowledge is a need for every programmer entering the filed of programming. Without this knowledge the programmer will be on the mercy of the hackers because of his ignorance of how his work could be exploited. This thesis also contains methods for the programmers on how to make their programs secure. The main focus of this thesis is Buffer overflow, buffer overflow is an attack in which a buffer is filled more than its own capacity and results in overwriting of other data present inside the memory. The data that is overwritten is controlled and therefore allows the alteration of the sequence of program execution. The field of computer security is very vast, buffer overflow is a small portion of it but buffer overflow itself is a grave problem in the filed of computer security. Buffer overflow is a problem related with the data and its storage. This problem will remain till data exchange remains and a lot of research is required to stop this problem. Here the first part is how could we detect a buffer overflow vulnerability and then if it exists then what is the severity of the problem. Detecting buffer overflow vulnerability is simple enough, in this process a buffer is continuously bombarded with a constantly growing chunk of data. A time will come when the buffer chunk is greater in size than the buffer and if not protected the buffer will overflow. This could be easily understood by considering the buffer as a glass and data as water, if the glass is continuously filled with water a time will come that the water will start spilling. The second portion is to detect the severity of the problem. This is a complex part and requires us to place our desired data inside the buffer. The level of severity is detected by the level of the payload that could be placed and the authority of the compromised program. But if a security has been implemented which stops the execution of the payload, then what should be the level of the attacker who can bypass the security of the buffer. The greater the level of the attacker the more security could be
pointing to that memory location containing that code, start the execution of that code resulting in a complete compromise of the vulnerable system. To meat with the challenges of computer security, security experts have developed ways by which they are trying to stop buffer overflow. But as the security experts are advancing so are the hackers, when ever a strategy is developed by the security experts to stop these attacks the hackers comes and develop new ways to bypass those security checks. One of the methods is to place garbage value after the buffer so when an attacker overflows the buffer and has placed his code, the program places a garbage value at the end of the buffer. Now what will happen is when the execution of the code placed by the attacker start, the execution will stop since the program execution will get stuck in the garbage values placed at the end of the buffer. Another way to stop buffer overflow is by placing a cookie at the end of the buffer and check the value of the cookie. Now when buffer overflow occurs, the value of the cookie will get changed since the data has been spilled out of the buffer. The program will continuously check the value of the cookie; when ever that changes the program execution will halt. This is the strategy being used by Microsoft in their control of buffer overflow for Windows operating system.
Buffer overflow was selected because it may cause a process to crash or produce incorrect results. This vulnerability could be exploited by inputs specifically designed to execute malicious code or to make the program operate in an unintended way. As such, buffer overflows cause many software vulnerabilities and form the basis of many exploits. Sufficient bounds checking by either the programmer or the compiler can prevent buffer overflows. Contrary to popular belief, it is nearly impossible to determine if vulnerabilities are being identified and released at an increasing or decreasing rate. One factor may be that it is increasingly difficult to define and document vulnerabilities. Buffer overflow vulnerabilities make up about 20 percent of all vulnerabilities identified. This type of vulnerability is considered a subset of input validation vulnerabilities which account for nearly 50 percent of vulnerabilities. Buffer overflows are the most feared of vulnerabilities from a software vendor’s perspective.
Table 1 Vulnerability Counts by Mitre. Vulnerability Type 2004 2003 2002 2001 Input Validation Error 438 (54%) 530 (53%) 662 (51%) 744 (49%) Boundary Condition Error 67 (8%) 81 (8%) 22 (2%) 51 (3%) Buffer Overflow 160 (20%) 237 (24%) 287 (22%) 316 (21%) Access Validation Error 66 (8%) 92 (9%) 123 (9%) 126 (8%) Exception Condition Error 114 (14%) 150 (15%) 117 (9%) 146 (10%) Environment Error 6 (1%) 3 (0%) 10 (1%) 36 (2%) Configuration Error 26 (3%) 49 (5%) 68 (5%) 74 (5%) Race Condition Error 8 (1%) 17 (2%) 23 (2%) 50 (3%) Design Error 177 (22%) 269 (27%) 408 (31%) 399 (26%) Other 49 (6%) 20 (2%) 1 (0%) 8 (1%)
Buffer overflow vulnerability is a great cause for Internet worms, automated tools to assist in exploitation, and intrusion attempts. With the proper knowledge, finding and writing exploits for buffer overflows is not an impossible task and could be done easily by simply knowing how the buffer overflow works. If the vulnerability was a remotely exploitable buffer overflow, then the exploit would attempt to overrun a vulnerable target’s bug and spawn a connecting shell back to the attacking system. Using secure programming and scripting languages are the only true solution in the fight against software hackers and attackers. Buffer overflow vulnerability account for approximately 20 percent of all vulnerabilities found and exploited. Buffer overflow vulnerabilities are dangerous since most of them allow attackers the ability to control computer memory space or inject and execute arbitrary code.
Our primary interest, of course, is the stack. Let’s look at this data structure a bit closer and see how it relates to and interfaces with the registers. We are forced to look at a little assembly language code at this point, but as you shall see, it is really not all that
popped from the stack, the stack pointer is incremented to point to the previous value on the stack. So why a stack does let a buffer overflow to occur, the answer is simple this is because there is no memory partition in the stack. If we look at it closely we will find that the stack is a large memory location which a program uses and reserves a portion for an operation but cant stop an event if it tries to use more than the reserve portion from the stack. This is what causes the buffer overflow, suppose a program allocates 100 memory spaces for some data to be placed in the stack but if the data is greater than 100 a buffer overflow will occur. Since 100 memory spaces were allocated and a data having size greater than 100 came then memory spaces after the reserved memory locations are overwritten. The data that was overwritten was supposed to run the program properly but since they were changed, the program will now run in another sequence according to the data places instead of the original data. Now if this strategy is used by an attacker and while overwriting the attacker places the data he desires to alter the sequence of the program execution then the attacker will be able to control the program execution sequence.
In this section we will discuss the parameters that constitute the requirements to perform a buffer overflow. Since remote buffer overflow is one in which a buffer at a remote system is overflowed there fore a mean of communication with the remote system is required. So to communicate with the remote system a protocol is required, so first a brief introduction of protocols is given.
The process of transfering data from one system to the other is a complex process. Therefore a set of rules are defined for this trnasmission to be possible. These rules are collectively called as protocol. A communications protocol is the set of standard rules for data representation, signaling, authentication and error detection required to send information over a communications channel. For example a simple communications protocol adapted to voice communication is the case of a radio dispatcher talking to mobile stations. The communication protocols for digital computer network
communication have a lot implemented in them due to which reliable interchange of data over an imperfect communication channel can take place. A protocol needs to be specified in such a way, that engineers, designers, and in some cases software developers can implement or use it. Its design needs to facilitate routine usage by humans. Protocol layering accomplishes these objectives by dividing the protocol design into a number of smaller parts, each of which performs closely related sub-tasks, and interacts with other layers of the protocol only in a small number of well- defined ways. Protocol layering allows the parts of a protocol to be designed and tested without a combinatorial explosion of cases due to which the design remains relatively simple. The implementation of a sub-task on one layer can make assumptions about the behavior and services offered by the layers beneath it. Thus, layering enables a "mix-and-match" of protocols that permit familiar protocols to be adapted to unusual circumstances.
Despite the hardware ports used to interface systems with the network there are software ports. These software ports are virtual ports due to which different processes could use the hardware port simultaniously. Each process has there for a different software port but same hardware port. The most common of these are TCP and UDP ports which are used to exchange data between computers on the Internet. In the TCP and UDP protocols used in computer networking, each header in the data packet has a special port number. This port number is then used t specify the process that it was intended. Ports are typically used to map data to a particular process running on a computer. In both TCP and UDP, each packet header will specify a source port and a destination port. These port numbers are 16-bit unsigned integer i.e. ranging from 0 to
This chapter discusses the detection and exploitation of buffer overflow vulnerability. A step by step approach is used in order to explain the process of exploitation. The chapter starts with the most basic level of exploiting a buffer. Then the method by which the program sequence is altered is shown. Next is the portion in which techniques are shown by which commands could be sent on the remote system. A simulation of a remote buffer overflow follows. The last portion shows the exploitation of a remote system.
For a buffer overrun attack to be possible and be successful, the following events must occur, and in this order:
This process is the longest; in this process a program containing a buffer is tested. A program normally contains a number of buffers since almost all the programs have some means of exchanging data from their environment. In this process first of all the program is started and then given a large array of characters. With the array being given continuous checking of the sequence of the program execution is being checked. A time comes when an error message from the operating system is displayed. This is the time when the inputting of the array is stopped.
Now what is done is that since a random length of value was being entered, there fore a precise amount of characters are to be taken to get the exact length of characters that will cause a buffer overflow. Slowly the length decreases and a time will come when the error message will stop. The last value that caused a buffer overflow will be taken as the length of array that causes the buffer to overflow. This method could me better described as hit and trial method. This is because no such thing as a fixed length of buffer exists. Every program has a different length of buffer and each buffer inside a program could be of different size. This is why this method was used instead of a fixed means for detecting the length of the array that causes a buffer to overflow.
Now once the size of the array that causes the buffer to overflow is determined, the data that is being sent is controlled. This is a simple task which includes the knowledge of the operating system that what is the structure of the memory of the buffer and at which location what data is present. In Windows operating system the return address is placed just after the buffer. Now when buffer overflow occurs and the memory location at which the return address was placed is altered the sequence of the program execution is changed. Now to get the program to perform the tasks it was not supposed to perform the address of the location at which the instructions that are to be executed are present is placed at the location of the return address.
These instructions could be present inside the program itself or these instruction could be implanted with the data that was sent inside the buffer. The instructions that are sent as data inside that array that causes the buffer to overflow are in the form of shell codes. The shell code is assembly instructions that are modified to be sent across networks. This code is modified and has a bit of restrictions like it doesn’t have ―00‖ in it or there are no spaces. So if these instructions are to be executed their address is to be places at the location at which the return address is present.
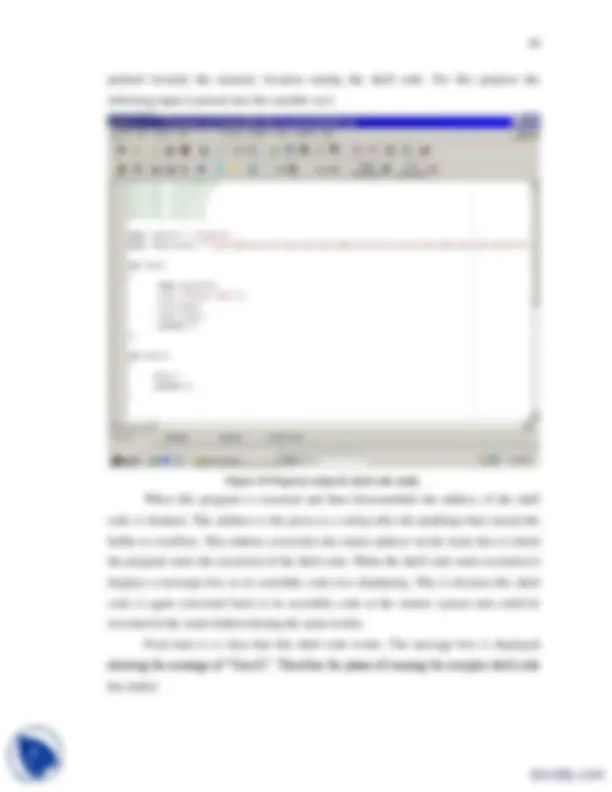
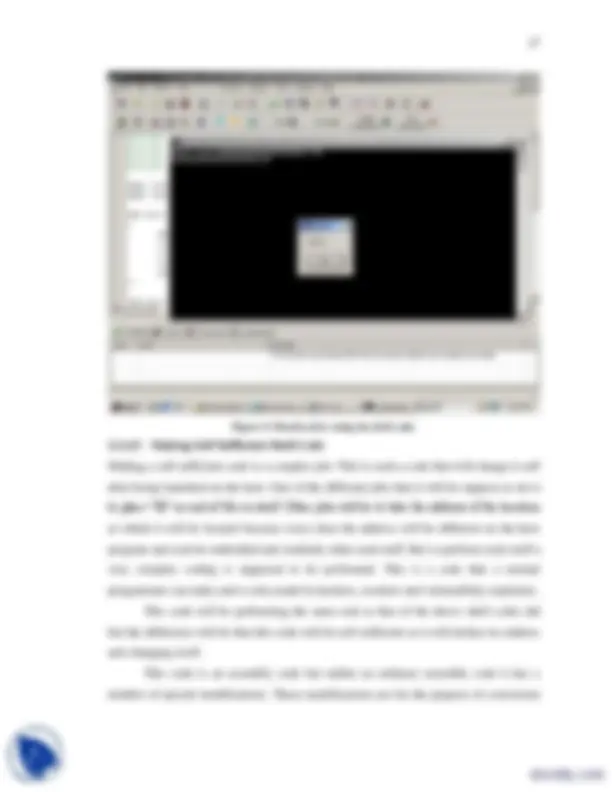
When the user enters his name in this program the buffer in this program overflows and the portion of that name that overwrites the return address will become the next memory address that will be accessed for the sake of program execution. This will be a random process because the user name could have any random name. But if we look at it closely this doesn’t seem a random process, the reason is simple and that is that for a specific name each time the same memory is accessed. From here we get the conclusion that the execution of the program could be steered according to the value that is used in the process of buffer overflow. So the program that shows all this is: #include<iostream.h> #include<conio.h> void main() { char str[2]; cout<<"Please enter your name:"; cin>>str; cout<<"The name u entered is:"<<str; getch(); } In figure 2 the buffer overflowed and the Windows operating system showed an error message that illegal memory location is being accessed:
Figure 2 Buffer overflow shown.
The following literature needs to be studied before performing a bypass:
2.2.2.1 Register
The x86 architecture has a number of different types of registers, which include general purpose, segment, index and control registers. Following are the different registers: General purpose registers are used for arithmetic and data movement. Each register can be addressed as either a 16 or 32 bit value. EAX (accumulator)-The extended accumulator register is used for word divide, word multiply and word I/O. The AL (Lower part of EAX) is used for byte divide, byte multiply, byte input and output, translate and decimal arithmetic. Where as AH (Higher part of lower two bytes) is used only of byte multiply and bytes divide. EBX (base)-The extended base register is used only for translation. Here the translation refers to the translation of memory addresses. It can also be combined with SI and DI for combined indexing. ECX (counter)-The extended counter register is used for counting and loops. This registers automatically increments in a loop instruction. EDX (data)-The extended data register is used for word multiply, word divide and indirect input and output operations.
Segment registers are used for base locations for program instructions, data and stack. All references to memory involve a segment register used as a base location. CS (code segment)-The processor uses CS segment for all accesses to instructions referenced by instruction pointer (IP) register. CS register cannot be changed directly. The CS register is automatically updated during far jump, far call and far return instructions.