


Name: Jyoti Yadav
Designation: Assistant Professor
Department: Management And Commerce
Department
Subject: Business Statistics
UNIT - 1
















Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
A well detailed notes of business organization unit 1
Typology: Study notes
1 / 24

This page cannot be seen from the preview
Don't miss anything!
Statistics is a branch of mathematics dealing with the collection, analysis, interpretation, presentation, and organization of data. In the Indian context, statistics plays a vital role in economic planning, policymaking, agriculture, industry, and social development.
of Indian Statistics. About P.C. Mahalanobis Feature Details Full Name Prasanta Chandra Mahalanobis Born 29 June 1893 Famous For Mahalanobis Distance, Large-Scale Sample Surveys Founder of Indian Statistical Institute (ISI), Kolkata Key Contribution Designed India’s Second Five-Year Plan Position Member of the Planning Commission of India Recognition National Statistics Day is celebrated on 29th June in his honour
The word statistics is derived from the Latin word status or the Italian Statista , meaning "statesman". Professor Gottfried Achenwall popularized the term in the 18th century to describe data related to the political and economic state of a region. Initially used for state records like census and wealth, its scope later expanded to a wide range of data-based analysis.
In Simple Words Statistics is the science of collecting, organizing, analysing, and interpreting numerical data to support decision-making or draw conclusions.
In organizations, statistics assists in monitoring employee performance and organizational growth for informed decision-making.
3. Social Sciences Statistics supports the analysis of both qualitative and quantitative data to interpret social behaviour and predict trends. 4. Commerce and Accounts It is essential in managing finances, cost-benefit analysis, and investment planning to ensure economic efficiency. 5. Industries From production to employee welfare, statistical data helps industries optimize resources and reduce unnecessary expenses. 6. Sciences and Mathematics Statistics provides precise tools to measure and analyse results in pure sciences, and it supports mathematical applications by quantifying variations. 7. Problem Solving By comparing variables and identifying patterns, statistics helps individuals find optimal solutions and minimize errors. 8. Theoretical Research Researchers use statistical tools to validate theories by establishing the relevance and significance of observed data and patterns.
1. Decision-Making Tool Statistics provides data-based insights to help individuals, businesses, and governments make informed decisions. 2. Planning and Forecasting It helps in predicting future trends based on historical data—useful in business forecasting, budgeting, and policy planning. 3. Simplifies Complex Data
Through averages, percentages, graphs, and charts, statistics presents large data sets in a clear and understandable form.
4. Essential for Research In scientific and social research, statistics helps in collecting, analysing, and interpreting data to validate hypotheses. 5. Quality Control Industries use statistical methods to maintain and improve product quality through control charts and defect analysis. 6. Aids in Comparison Statistics allows comparison between groups, time periods, or regions, helping identify patterns and differences. 7. Economic and Social Planning Governments use statistics in national planning, population studies, employment policies, and development programs. 8. Risk Management In sectors like insurance, finance, and health, statistics assesses probabilities and helps in managing risk.
1. Deals Only with Aggregates Statistics applies to groups or collections of data, not to individual cases or single observations. 2. Limited to Quantifiable Data It is most effective with numerical data. Qualitative data must be converted into numbers for statistical analysis. 3. Indirect Application to Qualitative Phenomena Qualitative aspects like emotions or opinions need numerical scales or ratings for statistical treatment. 4. Not Always Precisely Accurate Statistical conclusions are based on averages and probabilities, so they may not yield exact results like mathematical formulas.
6. Selection of Statistical Tools: Determine which states (e.g., descriptive statistics inferential statistics) will be used for analysis based on the type of data and objectives. 7. Data Analysis: Analyse the collected data sing appropriate statistical methods. The planning phase ensures that the data analysis is aligned with the research objectives and is carried out accurately. 8. Presentation of Finding: Plan how the results will be parented through reports, charts, or visualisations to effectively commentate the Conclusion and insights. 9. Review and Adjustment: Evaluate the process at various stages, making adjustments as needed. Continuous monitoring ensures that the investigation remains on track and produces reliable results.
Statistical units are the basic entities or elements about which data is collected and analysed in a statistical investigation. They are classified into two main types
1. Investigation Units : The objects, individuals, or phenomena being studied, such as people, households, businesses, or events. 2. Analysis Units: The units on which data is processed or aggregated, Iike averages, totals, or proportions. Statistical units can further be categorized as primary units (directly observed) and secondary units (derived or aggregated from primary data) The choice of statistical unit depends on the study's objectives and determines how data is collected, organized, and interpreted Proper identification of statistical units ensures accurate representation and meaningful analysis in statistical research.
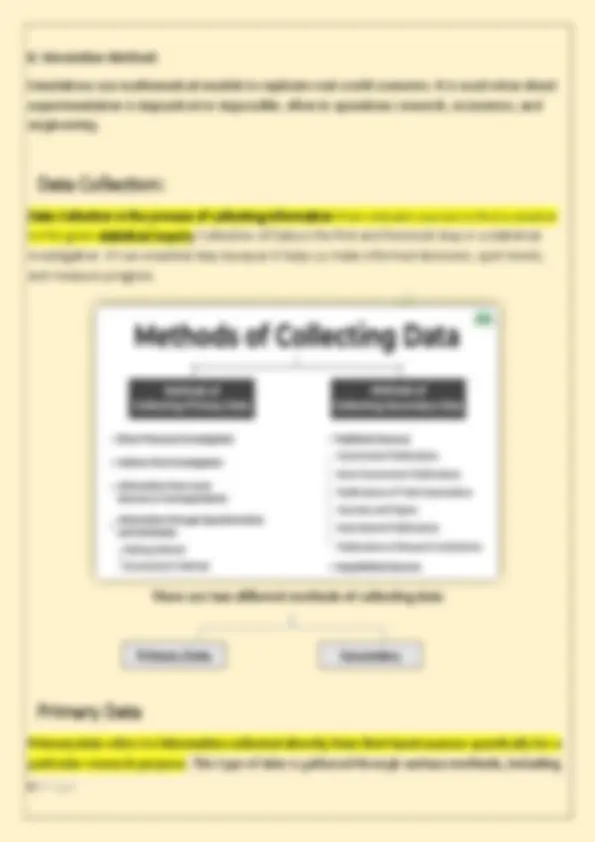
1. Census Method: This method involves collecting data from every unit in the population. It is comprehensive and provides highly accurate results but is time-consuming and costly. It is typically used in national censuses and large-scale studies.
2. Sample Survey Method: Instead of surveying the entire population, a representative sample is selected. This method is more practical quicker, and cost-effective. Sampling techniques include random sampling, stratified sampling, and cluster sampling, ensuring that the sample accurately represents the population. 3. Observational Method: In this method, data is collected by observing subjects in their natural environment without interference. It is commonly used in fields like sociology, psychology, and market research. Observational studies can be participant based or non-participant-based. 4. Experimental Method This involves conducting experiments where conditions are controlled to test hypotheses. It is commonly used in scientific research to determine cause-and-effect relationships. Experimental designs include controlled trials, lab experiments, and field experiments. 5. Survey Method: Surveys involve collecting data through questionnaires, interviews, or online forms. They are widely used in market research, social sciences, and public opinion polling. Surveys can be conducted face-to-face, over the phone, or digitally. 6. Case Study Method: A detailed analysis is conducted on a specific instance or case, often to explore unique or complex phenomena. The method is qualitative and typically used in social sciences, business, and psychology. 7. Secondary Data Analysis: This method involves analysing existing data collected by other organizations, such as government reports, industry studies, or historical records. It is cost-effective and time-saving but may be Limited by the quality of the original data.
surveys, interviews, experiments, observations, and focus groups. One of the main advantages of primary data is that it provides current, relevant, and specific information tailored to the researcher's needs, offering a high level of accuracy and control over data quality. Methods of Collecting Primary Data There are a number of methods of collecting primary data, some of the common methods are as follows:
1. Interviews: Collect data through direct, one-on-one conversations with individuals. The investigator asks questions either directly from the source or from its indirect links. 1. Direct Personal Investigation: T he method of direct personal investigation involves collecting data personally from the source of origin. In simple words, the investigator makes direct contact with the person from whom he/she wants to obtain information. For example, direct contact with the household women to obtain information about their daily routine and schedule. 2. Indirect Oral Investigation: In the indirect oral investigation method of collecting primary data, the investigator does not make direct contact with the person from whom he/she needs information, instead they collect the data orally from some other person who has the necessary required information. For example, collecting data of employees from their superiors or managers. - Advantage: Provides real-time, natural data; no reliance on self-reported information. - Disadvantage: Observer bias; limited to what can be seen; may influence subjects' behaviour. - Suitable Use Case: Behavioural studies, user experience research. 2. Questionnaires: Collect data by asking people a set of questions, either online, on paper, or face-to-face. In this method the investigator prepares a questionnaire to collect Information through Questionnaires and Schedules, while keeping in mind the motive of the study,. The investigator can collect data through the questionnaire in two ways: 1. Mailing Method: This method involves mailing the questionnaires to the informants for the collection of data. The investigator attaches a letter with the questionnaire in the mail to define the purpose of the study or research.
used by different informants. Some examples of semi-government bodies are Metropolitan Councils, Municipalities, etc.
After collecting data (from surveys, interviews, forms, etc.), it may contain errors, incomplete responses, or inconsistent entries. Before using this data for analysis, it must be cleaned and corrected. This process is called Data Editing. Data Editing is the process of reviewing, checking, and correcting collected data to ensure that it is accurate, complete, consistent, and ready for analysis. It is an important step in data processing, just like coding, classification, and tabulation. Objectives of Data Editing
Classification means grouping of related facts into different classes. The method of arranging data into homogeneous classes according to the common features present in the data is known as classification. Classification of data is a function very similar to that of sorting letters in a post office. categories based on common characteristics, to make it easier to understand, analyse, and interpret.
There are several types of frequency distributions that are commonly used to summarize and analyze data. The choice of a specific type depends on the nature of the data and the objectives of the analysis. Here are a few types of frequency distributions:
Example: Marks Range Relative Frequency Cumulative Relative Frequency 0 – 10 0.15 0. 11 – 20 0.25 0. 21 – 30 0.40 0. 31 – 40 0.20 1.
Statistical Series refers to a collection of data arranged in a specific order to show the frequency, variation, and distribution of a particular phenomenon. These series are used in various research studies to represent the data in a structured and organized manner, making it easier to interpret and analyse. For example, let’s say you want to study the consumption pattern of a specific product in a particular region. You can collect the data related to the product’s sales, customer feedback, market trends, etc., and arrange them in a chronological or geographical order to form a Statistical Series. This series will help you understand the pattern of consumption, the peak season, customer preference, etc. A statistical series is a more general term for any ordered presentation of statistical data. It can be based on values, time, location, etc.
There are mainly two types of Statistical Series: Time Series: Time series is a type of Statistical Series where data is collected over time at regular intervals. This type of series is used to represent the trend, seasonality, and cyclical variations in a phenomenon. The data collected in a time series can be represented using various charts and graphs such as line charts, bar graphs, histograms, etc. Cross-sectional Series: Cross-sectional series is a type of Statistical Series where data is collected at a particular point in time. This type of series is used to represent the variations and differences between the
characteristics of different groups or entities. The data collected in a cross-sectional series can be represented using various charts and graphs such as pie charts, stacked bar charts, etc.
Statistical Series plays a crucial role in research studies as they help in:
In conclusion, Statistical Series is a valuable tool in research studies that can help researchers represent and analyse data in an efficient and structured manner. ✓ A frequency distribution is a type of statistical series. ✓ All frequency distributions are statistical series, but not all statistical series are frequency distributions.