



INSTRUCTION-LEVEL PARALLEL
PROCESSORS
Chapter No. 4




























Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Instruction-level parallelism (ilp) in processors, including its principles, pipelined and superscalar operation, data and control dependencies, and instruction scheduling. It covers topics such as raw, war, waw, and loop-carried dependencies, as well as the impact of control dependence and resource dependency on ilp processors.
Typology: Study notes
1 / 45

This page cannot be seen from the preview
Don't miss anything!
Instruction-level parallelism (ILP) (^) Basic blocks (^) Sequences of instruction that appear between branches (^) Usually no more than 5 or 6 instructions! (^) Loops (^) for ( i=0; i<N; i++) (^) x[i] = x[i] + s; (^) We can only realize ILP by finding sequences of independent instructions (^) Dependent instructions must be separated by a sufficient amount of time
Principle Operation of ILP- Processors
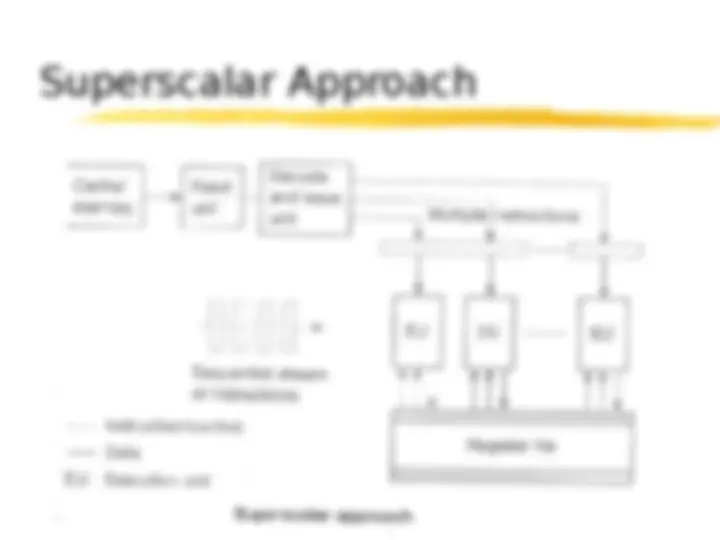
(^) A number of functional units are employed in sequence to perform a single computation. (^) Each functional unit represent a certain stage of computation. (^) Pipeline allows overlapped execution of instructions. (^) It increases the overall processor’s throughput.
(^) Abbreviation of VLIW is Very Large Instruction Word. (^) VLIW architecture receives multi-operation instructions, i.e. with multiple fields for the control of EUs. (^) Basic structure of superscalar processors and VLIW is same (^) multiple EUs, each capable of parallel execution on data fetched from a register file.
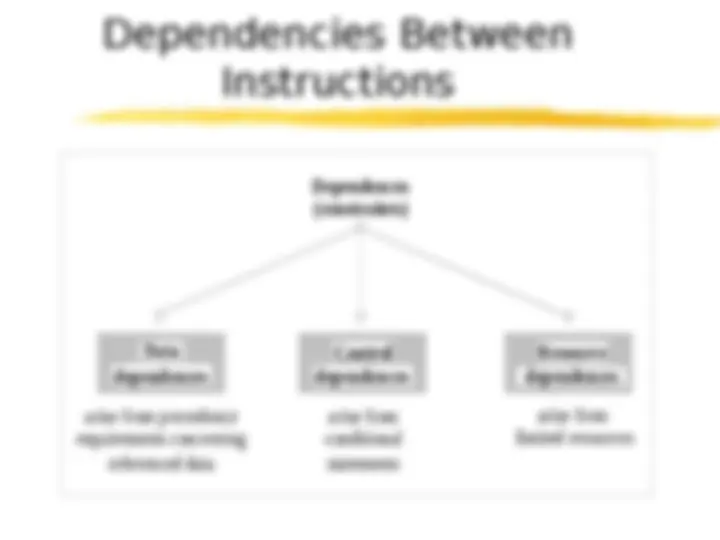
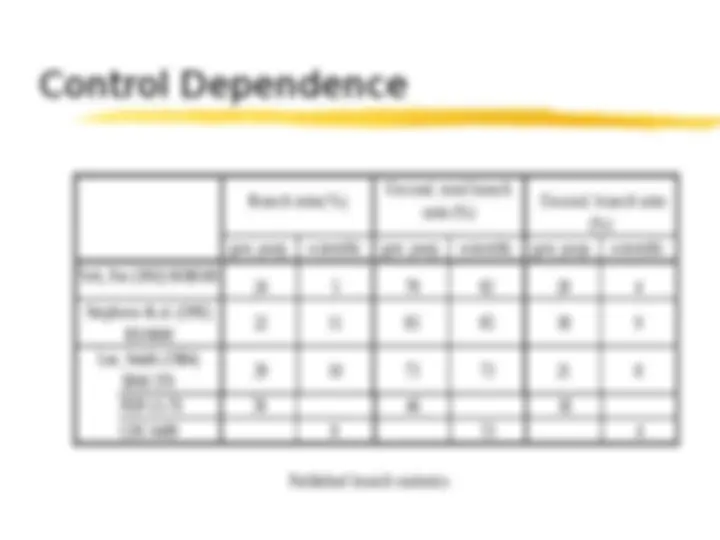
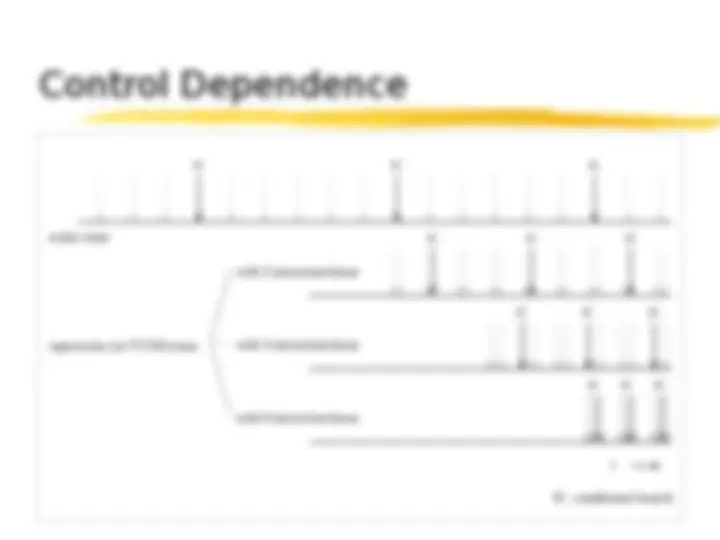
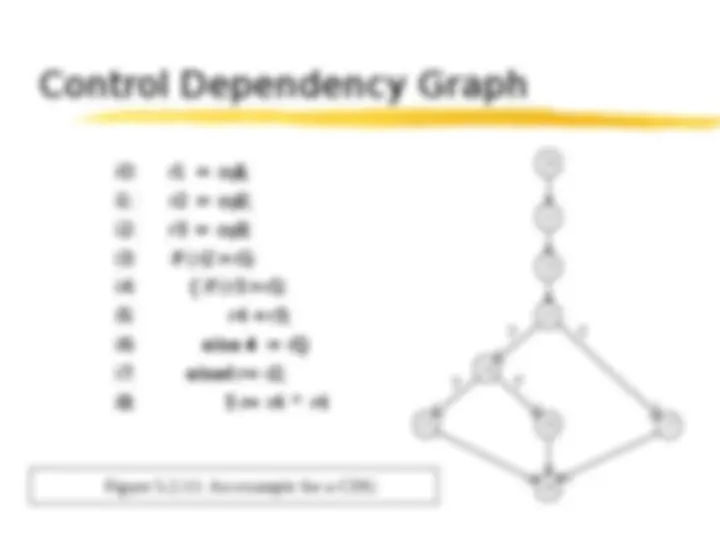
dependences Data arise from precedence Control requirements concerning referenced data arise from conditional statements Resource arise from limited resources dependences Dependences (constraints) dependences
Data Dependency (^) Data can be differentiated according to the data involved and according to their type. (^) The data involved in dependency may be from register or from memory (^) the type of data dependency may be either in a straight-line code or in a loop.
Data Dependency
(^) Read After Write (RAW) (^) i1: load r1, a; i2: add r2, r1, r1; (^) Assume a pipeline of Fetch/Decode/Execute/Mem/Writeback
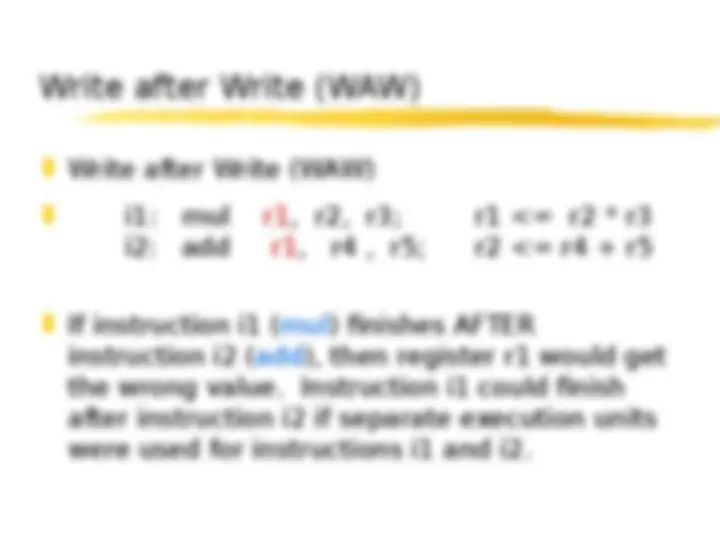
Name Dependencies (^) A “ name dependenc e” occurs when 2 instructions use the same register or memory location (a nam e) but there is no flow of data between the 2 instructions (^) There are 2 types: (^) Antidependencies: Occur when an instruction j writes a register or memory location that instruction i reads – and i is executed first (^) Corresponds to a WAR hazard (^) Output dependencies: Occur when instruction i and instruction j write the same register or memory location (^) Protected against by checking for WAW hazards