



Regression Analysis
Module 5: Other Regression Models and Case Studies
Outline of Lessons
1. Regularized Regression
2. Case Study: ER Volume
3. Case Study: Customer Churn



























Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Churn Rate Regression Analysis
Typology: Exercises
1 / 35

This page cannot be seen from the preview
Don't miss anything!
Outline of Lessons
Nicoleta Serban
Gamze Tokol-Goldsman
Dave Goldsman
H. Milton Stewart School of Industrial and Systems Engineering
5.1 Regularized Regression
Not all biased models are better.
We need a way to find “good” biased models!
0
penalty
0
𝑗
≠ 0 } ⇒ Minimizing Q means searching through all submodels
1
penalty (LASSO Regression)
1
= σ 𝑗= 1
𝑝
𝑗
| ⇒ Minimizing Q forces many 𝛽 𝑗
s to be zeros
2
penalty (Ridge Regression)
2
= σ 𝑗= 1
𝑝
𝑗
2
⇒ Minimizing Q accounts for multicollinearity
1
𝑝
𝑖= 1
𝑛
𝑖
0
1
𝑖
𝑝
𝑖𝑝
2
𝑝
0
penalty
1
penalty
2
penalty
1
𝑝
1
𝑝
), both of length 𝑝.
Vector 𝒖 is sparse, because it contains mostly zeros.
norm, we have | 𝒖 | 1
= σ 𝑖= 1
𝑝
𝑖
| = 1 and | 𝒗 | 1
= σ 𝑖= 1
𝑝
𝑖
norm, we have | 𝒖 | 2
= σ 𝑖= 1
𝑝
𝑖
2
= 1 and | 𝒗 | 2
= σ 𝑖= 1
𝑝
𝑖
2
= 1.
penalty rewards the sparsity of 𝒖; the 𝑳 2
penalty makes no distinction.
𝜷)
𝜷 = (𝑿
𝑇 𝑿 + λ𝐈)
− 1 𝑿
𝑇 𝒀
𝐈 is the identity matrix
𝜷 → 0 (high bias, low variance)
መ 𝛽 𝑗
to equal 0
𝑆𝑆𝐸 λ
(𝜷) =
𝑖= 1
𝑛
𝑦 𝑖
− (𝛽 0
𝑥 𝑖
𝑥 𝑖𝑝
)
2
𝑗= 1
𝑝
𝛽 𝑗
2
ℓ ( b ) is the log-likelihood function
መ 𝛽 𝑗
to equal 0
𝑆𝑆𝐸 λ
(𝜷) =
𝑖= 1
𝑛
𝑦 𝑖
− (𝛽 0
𝑥 𝑖
𝑥 𝑖𝑝
)
2
𝑗= 1
𝑝
|𝛽 𝑗
|
𝑆𝑆𝐸 λ
(𝜷) = −ℓ(𝛽 0
, ⋯ , 𝛽 𝑝
) + λ
𝑗= 1
𝑝
|𝛽 𝑗
|
1𝑝
1
𝑛 , ⋯ ,
𝑛𝑝
𝑛
into two sets.
መ 𝛽 0
,
መ 𝛽 1
, ⋯ ,
መ 𝛽 𝑝
The process can be repeated for multiple ls.
K-fold cross-validation (KCV)
, ⋯ , λ B
, and for k = 1 to K
k-th fold
error) for that λ for all folds
➔ Select λ penalty providing minimum overall error
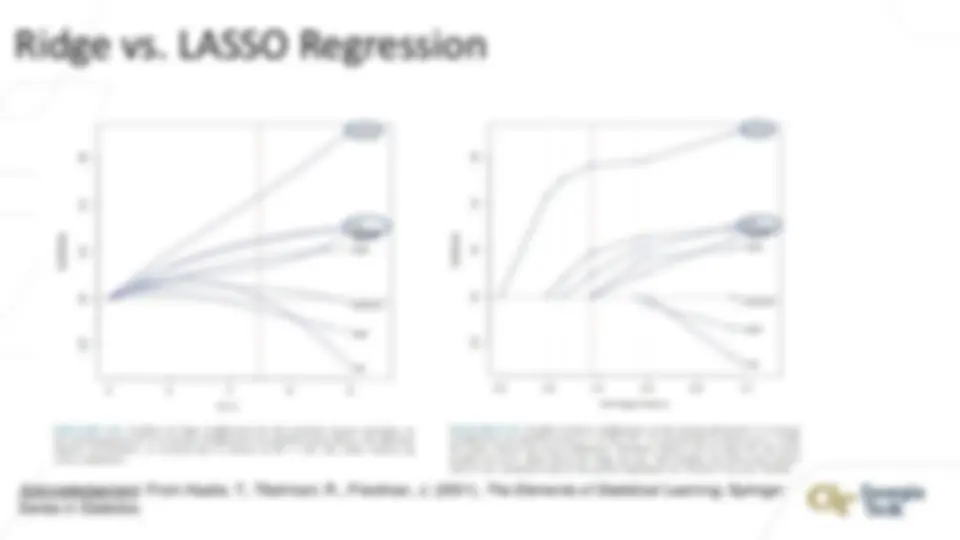
LASSO: Limitations
1
penalty generates a sparse model
2
penalty
regularization path
𝑖= 1
𝑛
𝑖
0
1
𝑖
𝑝
𝑖𝑝
2
𝑗= 1
𝑝
𝑗
| + λ 2
𝑗= 1
𝑝
𝑗
2
Reference: Hui Zou and Trevor Hastie. "Regularization and variable selection via the elastic net."
Journal of the Royal Statistical Society: Series B 67.2 (2005): 301-320.
library(MASS)
## Scale the predicting variables and the response variable
ltakers = log(takers)
predictors = cbind(ltakers, rank, income, years, public, expend)
predictors = scale(predictors)
sat.scaled = scale(sat)
## Apply ridge regression for a range of penalty constants
lambda = seq(0, 10, by=0.25)
out = lm.ridge(sat.scaled~predictors, lambda=lambda)
round(out$GCV, 5)
which(out$GCV == min(out$GCV))
10
round(out$coef[,10], 4)
predictorsltakers predictorsrank predictorsincome predictorsyears predictorspublic
predictorsexpend
The ridge regression outputs estimates for
each lambda in the considered range (not
shown)
The lambda is selected to minimize the
(generalized) CV score
plot(lambda, out$coef[1,], type = "l", col=1, lwd=3,
xlab = "Lambda", ylab = "Coefficients",
main = "Plot of Regression Coefficients vs. Lambda
Penalty Ridge Regression",
ylim = c(min(out$coef), max(out$coef)))
for(i in 2:6)
points(lambda, out$coef[i,], type = "l", col=i, lwd=3)
abline(h = 0, lty = 2, lwd = 3)
abline(v = 2.25, lty = 2, lwd=3)