Download Classical Probability Distribution - Lecture notes | STAT 541 and more Study notes Biostatistics in PDF only on Docsity!
4. Classical Probability Distributions
4.1 Discrete Models
Recall from 3.1, that for a discrete population random variable X , we have
Definition: f ( x ) is a probability distribution function if, for all x ,
f ( x ) ≥ 0 AND all
x
∑^ f^ x = 1.
The resulting cumulative distribution function (cdf) is defined as, for all x ,
F ( x ) = P ( X ≤ x ) = all
i
i x x
f x ≤
and is piecewise constant , increasing from 0 to 1. Therefore, for any two population values a < b , it follows that
P ( a ≤ X ≤ b ) = ∑ f ( ) x
b
a
= F ( b ) – F ( a^ −).
Definition: The mean (or expected value ) of X is given by μ = E [ X ] = all
x
∑^ x^ f x.
Definition: The variance of X is given by either of the two equivalent forms: 2 2 all 2 2 2 2 all
x
x
2
2
E X x )
E X x f x
σ μ μ f x
⎡ ⎤ ⎣ ⎦
⎡ ⎤ ⎣ ⎦
Total Area = 1
… | | | | X
x 1 x 2 x 3 μ x …
f ( x 1)
f ( x 2) f ( x 3)
f ( x ) 0
| | | | X
x 1 x 2 x 3 … x …
F ( x 1)
F ( x 2)
F ( x 3)
Example:
POPULATION = Women diagnosed with breast cancer in Dane County, 1996-
Among other things, this study estimated that the rate of “breast cancer in situ (BCIS),” which is diagnosed almost exclusively via mammogram, is approximately 12-13%. That is, for any individual randomly selected from this population, we have a binary variable
1, with probability 0. BCIS 0, with probability 0.88.
⎧⎪ ⎨ ⎪⎩
In a random sample of breast cancer diagnoses, let
n = 100
X = # BCIS cases (0 ,1,2, …,100).
P X = P X ( = 2 P X ( 20)
Questions:
y How can we model the probability distribution of X , and under what assumptions?
y Probabilities of events , such as ( 0 ), 0), ,
Full article available online at this link.
etc.?
y Mean # BCIS cases =?
y Standard deviation of # BCIS cases =?
Probabilities:
Total Area = 1
First assume the coin is fair ( π = 0.5 ⇒ 1 − π = 0.5 ), i.e., equally likely elementary outcomes H and T on a single trial. In this case, the probability of any event A above can thus be easily calculated via P ( A ) = #( A ) / #( S ).
x P ( X = x ) =
⎜
⎛ ⎠
⎟
x
Now consider the case where the coin is biased (e.g., π = 0.7 ⇒ 1 − π = 0.3 ). Calculating P ( X = x ) for x = 0, 1, 2, 3, 4, 5 means summing P (all its outcomes).
Example: P ( X = 3) =
outcome via independence of H, T
P ( H H H T T ) = (0.7)(0.7)(0.7)(0.3)(0.3) = (0.7)^3 (0.3)^2
P ( H H T H T ) = (0.7)(0.7)(0.3)(0.7)(0.3) = (0.7)^3 (0.3)^2
P ( H H T T H ) = (0.7)(0.7)(0.3)(0.3)(0.7) = (0.7)^3 (0.3)^2
P ( H T H H T ) = (0.7)(0.3)(0.7)(0.7)(0.3) = (0.7)^3 (0.3)^2
P ( H T H T H ) = (0.7)(0.3)(0.7)(0.3)(0.7) = (0.7)^3 (0.3)^2
P ( H T T H H ) = (0.7)(0.3)(0.3)(0.7)(0.7) = (0.7)^3 (0.3)^2
P ( T H H H T ) = (0.3)(0.7)(0.7)(0.7)(0.3) = (0.7)^3 (0.3)^2
P ( T H H T H ) = (0.3)(0.7)(0.7)(0.3)(0.7) = (0.7)^3 (0.3)^2
P ( T H T H H ) = (0.3)(0.7)(0.3)(0.7)(0.7) = (0.7)^3 (0.3)^2
P ( T T H H H ) = (0.3)(0.3)(0.7)(0.7)(0.7) = (0.7)^3 (0.3)^2
via disjoint outcomes,
⎝
⎜
⎛ ⎠
⎟
Hence, we similarly have…
Total Area = 1
x
⎝
⎜
⎛ ⎠
⎟
⎝ ⎜
⎛ ⎠ ⎟
⎝
⎜ ⎛ ⎠
⎟
⎝
⎜ ⎛ ⎠
⎟
⎝ ⎜
⎛ ⎠ ⎟
⎝ ⎜
⎛ ⎠ ⎟
P ( X = x ) =
⎝
⎜
⎛ ⎠
⎟
x
(0.7) x^ (0.3)^5 −^ x
Example: Suppose that a certain medical procedure is known to have a 70% successful recovery rate (assuming independence). In a random sample of n = 5 patients, the probability that three or fewer patients will recover is:
Method 1 : P ( X ≤ 3) = P ( X = 0) + P ( X = 1) + P ( X = 2) + P ( X = 3) = 0.00243 + 0.02835 + 0.13230 + 0.30870 = 0.
Method 2 : P ( X ≤ 3) = 1 − [ P ( X = 4) + P ( X = 5) ] = 1 − [0.36015 + 0.16807 ] = 1 – 0.52822 = 0.
Example: The mean number of patients expected to recover is:
μ = E [ X ] = 0 (0.00243) + 1 (0.02835) + 2 (0.13230) + 3 (0.30870) + 4 (0.36015) + 5 (0.16807) = 3.5 patients
This makes perfect sense for n = 5 patients with a π = 0.7 recovery probability, i.e., their product. In the probability histogram above, the “balance point” fulcrum indicates the mean value of 3.5.
Comments :
¾ The assumption of independence of the trials is absolutely critical! If not satisfied – i.e., if the “success” probability of one trial influences that of another – then the Binomial Distribution model can fail miserably. (Example: X = “number of children in a particular school infected with the flu”) The investigator must decide whether or not independence is appropriate, which is often problematic. If violated, then the correlation structure between the trials may have to be considered in the model.
¾ As in the preceding example, if the sample size n is very large, then the computation
of ⎝
⎜ ⎛ ⎠
⎟ n ⎞ x for^ x^ = 0, 1, 2, …,^ n , can be intensive and impractical.^ An approximation to the Binomial Distribution exists, when n is large and π is small, via the Poisson Distribution (coming up…).
¾ Note that the standard deviation σ = n π (1 − π) depends on the value of π. (Later…)
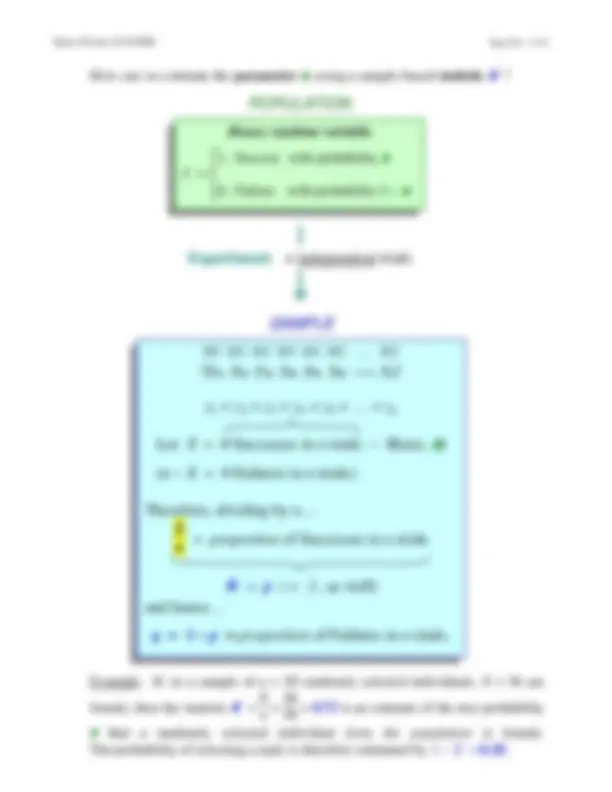
How can we estimate the parameter π, using a sample-based statistic πˆ?
Example: If, in a sample of n = 50 randomly selected individuals, X = 36 are
female, then the statistic πˆ =
X
n =
50 =^ 0.72^ is an estimate of the true probability
π that a randomly selected individual from the population is female.
The probability of selecting a male is therefore estimated by 1 − πˆ = 0..
POPULATION
Binary random variable
1, Success with probability π Y = 0, Failure with probability 1 − π
Experiment: n independent trials
SAMPLE
0/1 0/1 0/1 0/1 0/1 0/1 … 0/ ( y 1 , y 2 , y 3 , y 4 , y 5 , y 6 , …, yn )
y 1 + y 2 + y 3 + y 4 + y 5 + … + yn
Let X = # Successes in n trials ~ Bin( n , π )
( n − X = # Failures in n trials).
Therefore, dividing by n … X n = proportion of Successes in n trials
πˆ = p ( = y , as well) and hence…
q = 1 − p = proportion of Failures in n trials.
Example ( see above ): Again suppose that a certain spontaneous medical condition E affects 1% (i.e., α = 0.01 ) of the population. Let X = “number of affected individuals in a random sample of T = 300.” As before, the mean number of expected occurrences of E in the sample is μ = α T = (0.01)(300) = 3 cases. Hence X ~ Poisson(3), and the probability that any number x = 0, 1, 2, … of individuals are affected is given by:
P ( X = x ) =
e −^3 3 x x! which is a much easier formula to work with than the previous one. This fact is sometimes referred to as the Poisson approximation to the Binomial Distribution , when T (respectively, n ) is large, and α (respectively, π) is small. Note that in this example, the variance is also σ 2 = 3, so that the
standard deviation is σ = 3 = 1.732, very close to the exact Binomial value.
Area = 1^ Area = 1
x
Binomial
P ( X = x ) = ⎝
⎜
⎛ ⎠
⎟
x (0.01)
x (^) (0.99) 300 − x
Poisson
P ( X = x ) =
e −^3 3 x x! 0 0.04904^ 0. 1 0.14861^ 0. 2 0.22441^ 0. 3 0.22517^ 0. 4 0.16888^ 0. 5 0.10099^ 0. 6 0.05015^ 0. 7 0.02128^ 0. 8 0.00787^ 0. 9 0.00258^ 0. 10 0.00076^ 0. etc. (^) → 0 → 0
Why is the Poisson Distribution a good approximation to the
Binomial Distribution, for large n and small π?
( Rule of Thumb: n ≥ 20 and π ≤ 0.05; excellent if n ≥ 100 and π ≤ 0.1.)
Let f Bin( x ) = ⎝
⎜ ⎛ ⎠
⎟ n ⎞ x^ π^
x (^) (1 − π) n − x (^) and f Poisson( x )^ =^
e^ −λ^ λ x x! , where^ λ^ =^ n^ π.
We wish to show formally that, for fixed λ, and x = 0, 1, 2, …, we have:
lim f Bin( x ) = f Poisson( x ).
Siméon Poisson (1781 - 1840)
n → ∞ π → 0
Proof: By elementary algebra, it follows that…
f Bin( x ) = ⎝
⎜ ⎛ ⎠
⎟ n ⎞ x^ π^
x (^) (1 − π) n − x
n! x! ( n − x )! π x^ (1 − π) n^ (1 − π) −^ x
x! n^ ( n^ −^ 1) ( n^ −^ 2) ... ( n^ −^ x^ + 1)^ π^
x ⎝
⎜
⎛ ⎠
⎟
⎞ 1 −
λ n
n (1 − π) −^ x
x!
n ( n − 1) ( n − 2) ... ( n − x + 1) n x^ n
x π x ⎝
⎜
⎛ ⎠
⎟
⎞ 1 −
λ n
n (1 − π) −^ x
x!
n n (^) ⎝ ⎜
⎛ ⎠
⎟ n − 1 ⎞ n (^) ⎝ ⎜
⎛ ⎠
⎟ n − 2 ⎞ n …^ ⎝ ⎜
⎛ ⎠
⎟ n − x + 1⎞ n ( n^ π)
x ⎝
⎜
⎛ ⎠
⎟
⎞ 1 −
λ n
n (1 − π) −^ x
x! (^1) ⎝ ⎜
⎛ ⎠
⎟
⎞ 1 −
n (^) ⎝ ⎜
⎛ ⎠
⎟
⎞ 1 −
n …^ ⎝ ⎜
⎛ ⎠
⎟
⎞ 1 −
x − 1 n^ λ^
x ⎝
⎜
⎛ ⎠
⎟
⎞ 1 −
λ n
n (1 − π) −^ x
As n → ∞, ↓ ↓ ↓ ↓ ↓ π → 0, 1 x! 1(1)(1) … (1) = 1^ λ^
x (^) e −λ 1 − x (^) = 1
e^ −λ^ λ x x! =^ f Poisson( x ).^ QED