Download Understanding Classification vs. Prediction: Applications - Prof. Abdelghani Bellaachia and more Study notes Computer Science in PDF only on Docsity!
Classification and Prediction
9.1. Regress Analysis and Log-Linear Models in Prediction
- Objectives .................................................................................
- Classification vs. Prediction.....................................................
- 2.1. Definitions ........................................................................
- 2.2. Supervised vs. Unsupervised Learning............................
- 2.3. Classification and Prediction Related Issues ...................
- Common Test Corpora .............................................................
- Classification ............................................................................
- Decision Tree Induction .........................................................
- 5.1. Decision Tree Induction Algorithm ...............................
- 5.2. Other Attribute Selection Measures...............................
- 5.3. Extracting Classification Rules from Trees: ..................
- 5.4. Avoid Overfitting in Classification................................
- 5.5. Classification in Large Databases ..................................
- Bayesian Classification ..........................................................
- 6.1. Basics..............................................................................
- 6.2. Naïve Bayesian Classifier ..............................................
- Bayesian Belief Networks......................................................
- 7.1. Definition........................................................................
- Neural Networks: Classification by Backpropagation...........
- 8.1. Neural network Issues ....................................................
- 8.2. Backpropagation Algorithm...........................................
- Prediction................................................................................
- Classification Accuracy: Estimating Error Rates ..............
1. Objectives
- Techniques to classify datasets and provide categorical labels, e.g., sports, technology, kid, etc.
- Example; {credit history, salary}-> credit approval ( Yes/No)
- Models to predict certain future behaviors, e.g., who is going to buy PDAs?
The class labels of training data is unknown
Given a set of measurements, observations, etc. with the aim of establishing the existence of classes or clusters in the data
2.3. Classification and Prediction Related Issues
- (^) Data Preparation Data cleaning o Preprocess data in order to reduce noise and handle missing values Relevance analysis ( feature selection ) o Remove the irrelevant or redundant attributes Data transformation o Generalize and/or normalize data
- Performance Analysis Predictive accuracy: o Ability to classify new or previously unseen data. Speed and scalability o Time to construct the model o Time to use the model Robustness o Model makes correct predictions: Handling noise and missing values Scalability o Efficiency in disk-resident databases Interpretability: o Understanding and insight provided by the model Goodness of rules
o Decision tree size o Compactness of classification rules
3. Common Test Corpora
- Reuters - Collection of newswire stories from 1987 to 1991, labeled with categories.
- TREC-AP newswire stories from 1988 to 1990, labeled with categories.
- OHSUMED Medline articles from 1987 to 1991, MeSH categories assigned.
- UseNet newsgroups.
- WebKB - Web pages gathered from university CS departments.
o Distance based o Partitioning based
- (^) Classification as a two-step process: o (^) Model construction : Build a model for pre-determined classes. o Model usage : Classify unknown data samples o If the accuracy is acceptable, use the model to classify data objects whose class labels are not known
Partitioning Based^ Distance Based
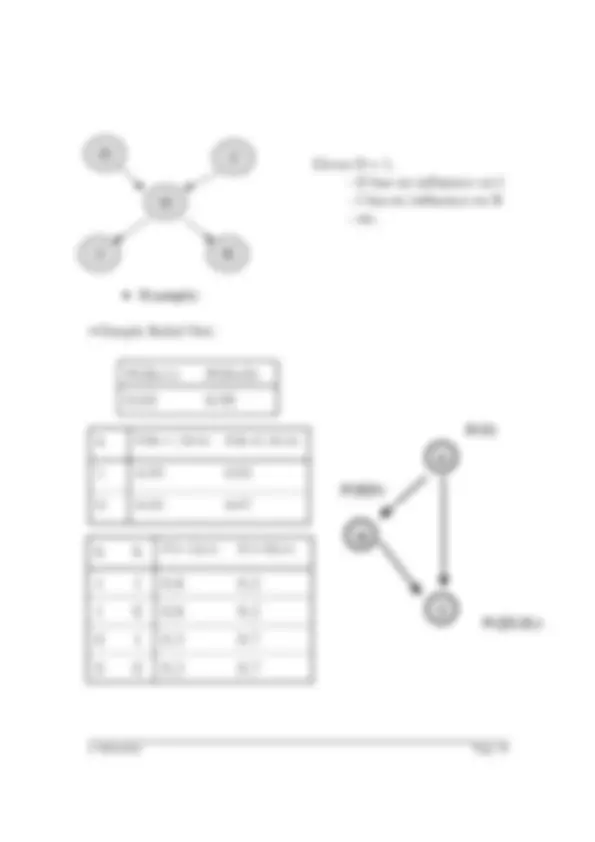
- Model construction : describing a set of predetermined classes o Each data sample is assumed to belong to a predefined class, as determined by the class label attribute o Use a training dataset for model construction. o The model is represented as classification rules, decision trees, or mathematical formula
Training Data
NAME RANK YEARS TENURED Mike Assistant Prof 3 no Mary Assistant Prof 7 yes Bill Professor 2 yes Jim Associate Prof 7 yes Dave Assistant Prof 6 no Anne Associate Prof 3 no
Classification Algorithms
IF rank = ‘professor’ OR years > 6 THEN tenured = ‘yes’
Classifier (Model)
- Neural Networks (NNet) - Learn non-linear mapping from input data samples to categories.
- Support Vector Machines (SVMs).
5. Decision Tree Induction
- Example: Training Dataset [Quinlan’s ID3]
age income student credit_rating buys_computer
<=30 high no fair no <=30 high no excellent no 31…40 high no fair yes
40 medium no fair yes
40 low yes fair yes 40 low yes excellent no
31…40 low yes excellent yes <=30 medium no fair no <=30 low yes fair yes
40 medium yes fair yes <=30 medium yes excellent yes 31…40 medium no excellent yes 31…40 high yes fair yes 40 medium no excellent no
5.1. Decision Tree Induction Algorithm
- Basic algorithm (a greedy algorithm) o Tree is constructed in a top-down recursive divide-and- conquer manner o At start, all the training examples are at the root o Attributes are categorical (if continuous-valued, they are discretized in advance) o Samples are partitioned recursively based on selected attributes o (^) Test attributes are selected on the basis of a heuristic or statistical measure (e.g., information gain) o Conditions for stopping partitioning All samples for a given node belong to the same class There are no remaining attributes for further partitioning – majority voting is employed for classifying the leaf There are no samples left
- Attribute Selection Measure: Information gain
o Select the attribute with the highest information gain o S contains si tuples of class Ci for i = {1, …, m} o Entropy of the set of tuples: It measures how informative is a node.
=
m
i
i i m (^) s
s s
s I s s s 1
( 1 , 2 ,..., ) log 2
o Entropy after choosing attribute A with values {a1,a2,…,av}
=
v
j
j mj
j mjI s s s
s s E A 1
1
( )^1 ... ( ,..., )
o Information gained by branching on attribute A
Gain ( A )= I ( s 1 , s 2 ,..., sm )− E ( A )
- Information Gain Computation
o Class P: buys_computer = “yes” p: number of samples
o Class N: buys_computer = “no” n: number of samples
o The expected information:
I(p, n) = I(9, 5) =0.
o Compute the entropy for age :
age pi ni I(pi, ni) <=30 2 3 0. 30…40 4 0 0
40 3 2 0.
- Recursively apply the same process to each subset.
income student credit_rating class
high no fair no high no excellent no low yes fair yes medium no fair no medium yes excellent yes
income student credit_rating class medium no fair yes low yes fair yes low yes excellent no medium yes fair yes medium no excellent no
income student credit_rating class high no fair yes low yes excellent yes medium no excellent yes high yes fair yes
Age?
All yes. It is a leaf.
5.3. Extracting Classification Rules from Trees:
- Represent the knowledge in the form of IF-THEN rules
- One rule is created for each path from the root to a leaf
- Each attribute-value pair along a path forms a conjunction
- The leaf node holds the class prediction
- Rules are easier for humans to understand
- Example o IF age = “<=30” AND student = “ no ” THEN buys_computer = “ no ” o IF age = “<=30” AND student = “ yes ” THEN buys_computer = “ yes ” o IF age = “31…40” THEN buys_computer = “ yes ” o IF age = “>40” AND credit_rating = “ excellent ” THEN buys_computer = “ yes ” o IF age = “<=30” AND credit_rating = “ fair ” THEN buys_computer = “ no ”
5.4. Avoid Overfitting in Classification
- Overfitting: An induced tree may overfit the training data o Too many branches, some may reflect anomalies due to noise or outliers o Poor accuracy for unseen samples
- Two approaches to avoid overfitting o Prepruning: Halt tree construction early—do not split a node if this would result in the goodness measure falling below a threshold Difficult to choose an appropriate threshold o Postpruning: Remove branches from a “fully grown” tree—get a sequence of progressively pruned trees
Use a set of data different from the training data to decide which is the “best pruned tree”
5.5. Classification in Large Databases
- Classification—a classical problem extensively studied by statisticians and machine learning researchers
- Scalability: Classifying data sets with millions of examples and hundreds of attributes with reasonable speed
- (^) Why decision tree induction in data mining? o Relatively faster learning speed (than other classification methods) o Convertible to simple and easy to understand classification rules o Can use SQL queries for accessing databases o Comparable classification accuracy with other methods