Download Cluster Sampling and more Schemes and Mind Maps Design history in PDF only on Docsity!
Cluster Sampling
- A cluster sample is a probability sample in which each sampling unit is a collection or a group of elements.
- It is useful when:
(i) A list of elements of the population is not available but it is easy to obtain a list of clusters. (ii) The cost of obtaining observations increases as the distance that separates the elements.
- If only a sample of elements is taken from each selected cluster, the method is known as two-stage sampling.
- Often a hierarchy of clusters is used: First some large clusters are selected, next some smaller clusters are drawn within the selected large clusters, and so on until finally elements are selected within the final-stage clusters.
- EXAMPLE: In a survey of students from a city, we first select a sample of schools, then we select a sample of classrooms within the selected schools, and finally we select a sample of students within the selected classes.
- This general method is known as multistage sampling, although it is also sometimes loosely described as cluster sampling.
- Although strata and clusters are both groupings of elements, they serve for entirely different sampling purposes.
- Since strata are all represented in the sample, it is advantageous if they are internally homogeneous in the survey variables.
- As only a sample of clusters are sampled, the ones selected need to represent the ones unselected; this is best done when the clusters are as internally heterogeneous in the survey variables as possible.
- The estimator of the population mean μ is the sample mean ¯y, given by
y ¯ =
∑ni=1 yi ∑ni=1 mi
- The estimator has the form of a ratio estimator , therefore the estimated variance of y¯ is
V ar̂ (¯y) =^ (^ N^ −^ n N nM 2
) ∑ni=1 (yi − ym¯ i) 2 n − 1 where the average cluster size for the population (M ) can be estimated by m¯ if M (the number of elements in the population) is unknown.
- The estimated variance is biased, except if the cluster sizes mi are equal.
Anyway, it is a good estimator of V ar(¯y) if n ≥ 20.
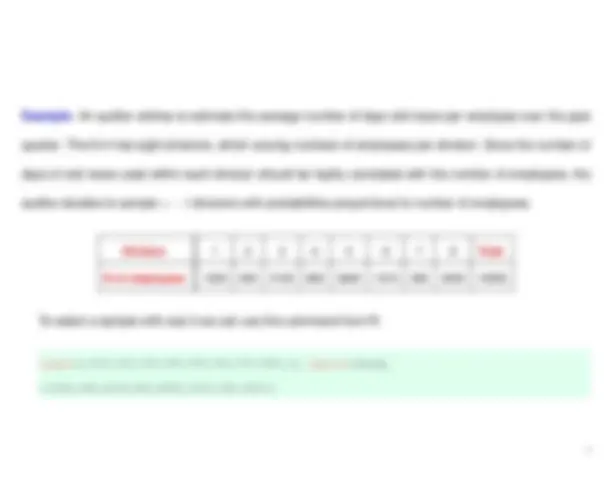
Example : A firm is interested in estimating the average per capita income in a certain city. There is not an available list of resident adults. The city is marked off into rectangular blocks, except for two industrial areas and three parks which contain a few houses. The researchers decide that each of the city blocks will be considered a cluster, the two industrial areas will be considered a cluster and, finally, the three parks will be considered a cluster. The clusters are numbered from 1 to 60 and there is budget for sampling n = 20 clusters and to interview every household within each cluster.
Number of 55 60 63 58 71 78 69 58 52 71 Residents mi 73 64 69 58 63 75 78 51 67 70 Total Income 2210 2390 2430 2380 2760 3110 2780 2370 1990 2810 per cluster yi 2930 2470 2830 2370 2390 2870 3210 2430 2730 2880
mu.hat <- sum(y)/sum(m.vec) s2.c <- sum((y-(mu.hatm.vec))ˆ2)/(n-1) var.mu.hat <- ((N-n)/(Nnmbarˆ2))s2.c
B <- 2*sqrt(var.mu.hat) cbind(mu.hat,s2.c,var.mu.hat,B) }
Example
m <- c(55,60,63,58,71,78,69,58,52,71, 73,64,69,58,63,75,78,51,67,70) y <- c(2210,2390,2430,2380,2760,3110,2780, 2370,1990,2810,2930,2470,2830,2370, 2390,2870,3210,2430,2730,2880)
cluster.mu(60,m.vec=m,y,total=T,M=NA)
- Cluster sampling is an ideal situation to use pps sampling (sampling with probabilities proportional to size), since the number of elements in a cluster mi forms a natural measure of the size of the cluster and it is convenient to sample with probabilities proportional to mi.
- In this case, πi = m Mi and the estimator of the population mean μ is
μ ˆpps =^1 n ∑^ n i=1y^ ¯i where y¯i is the mean for the i-th cluster, and the estimated variance of μˆpps is
V ar̂ (ˆμpps) = (^) n(n^1 − 1)∑^ n i=1^ (¯yi^ −^ μˆpps)
2
Assume that the sample elements are divisions 3, 6 and 8 where the total number of sick days are respectively
yi = 4320 y 2 = 4160 y 3 = 5790 In this case, ¯yi = 43202100 = 2. 06 y¯ 2 = 41601910 = 2. 18 y¯ 3 = 57903200 = 1. 81
hence, ˆμpps =^13
∑^3
i=1y^ ¯i^ = 2.^02
- The estimated variance of μˆpps is
V ar̂ (ˆμpps) = (^3 1) · 2 ∑^3 i=1^ (¯yi^ −^ μˆpps)
- And the interval with a 95% of confidence is
- 02 ± 1. 96 · √ 0. 012 ⇒ [1.8053; 2.2347]
Cluster Sampling with Stratification
- Cluster sampling can be combined with stratified sampling, because a population can be divided in L strata and a cluster sample can be selected from each stratum.
- As in the case of ratio estimators we can consider separate estimators and combined estimators.
- Usually the total number of elements in each cluster is not known and we cannot calculate weights. Then, the usual estimators in cluster sampling are the combined estimators.
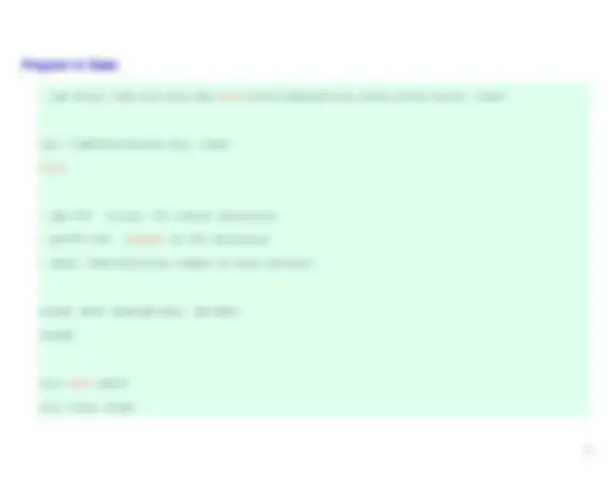
Program in Stata :
- use http://www.ats.ucla.edu/stat/stata/seminars/svy_stata_intro/oscs1, clear
use C:\QM\Eje1Cluster.dta, clear count
- fpc=757^ (total:^757 school^ districts)
- pw=757/189^ (sample^ of^189 districts)
- dnum: Identification^ number^ of^ each district
svyset dnum [pweight=pw], fpc(fpc) svydes
svy: mean api svy: total stype
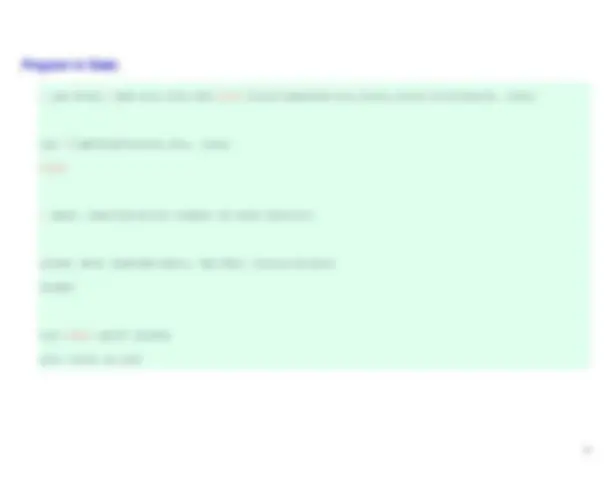
- Compute the average^ proportion^ of^ English language learners
- and students^ eligible^ for^ subsidized school meals for elementary,
- middle, and high^ schools
svy: mean ell meals, over(stype)
- Regression models^ show^ that^ these^ socioeconomic variables
- predict API score^ and^ whether^ the^ school achieved
- its API target
svy: reg api00 ell meals
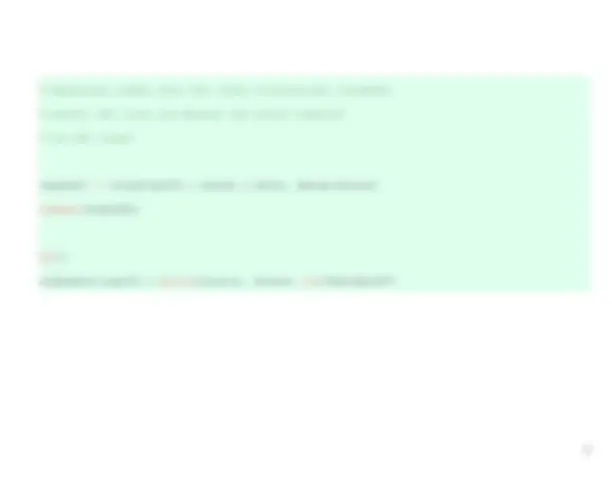
Compute the average proportion of English language learners
and students eligible for subsidized school meals for elementary,
middle, and high schools
svyby(∼ell+meals, ∼stype, design=dclus1, svymean)
Regression models show that these socioeconomic variables
predict API score and whether the school achieved
its API target
regmodel <- svyglm(api00 ∼ ell + meals, design=dclus1) summary(regmodel)
Observations :
- With cluster sampling, the smaller the size of the clusters the better is. When there is a hierarchy of clusters, the smallest ones will generally be the preferred choice.
- For example, in a High School example, the students could be grouped by grade levels or classes; here grade levels are too large to serve as clusters for sampling purposes, and classes are the obvious choice.
- The problem with cluster sampling is that, because clusters usually comprise existing groupings that were formed for other purposes, the lowest level of clustering still often yields clusters that are too large to be used efficiently in cluster sampling.
- The solution to this problem is to divide the clusters into sub-clusters for sampling purposes; essentially this is what is done in multistage sampling.
- In two-stage cluster sampling, the sample of elements is obtained as a result of two stages of sampling.
- The population elements are first grouped into disjoint subpopulations, called primary sampling units ( PSU ). Then, in a first-stage sampling, a sample of PSU is drawn.
- In the second-stage sampling units ( SSU ) may be clusters of elements, for each PSU in the first-stage sample.
- A sample of SSU is drawn (second-stage sampling) from each PSU in the first-stage sample. When the SSU are clusters, every element in the selected SSU is surveyed.
Example of cluster sampling
The Swedish Board of Education take annual surveys in Sweden to measure drug use among youngster students. Data on drug use is collected through anonymous questionnaires from every student in a sample of ninth-grade classes. The sampling frame consists of a list of all ninth-grade classes.
Example of two-stage cluster sampling, with schools as PSU and with classes as SSU : (i) A sample of schools is drawn from a frame containing all the schools in the country. (ii) From every selected school, a sample of ninth-grade classes is drawn and all students in the selected classes are surveyed.