


Clustering CS446-Fall 08 1
Final Exam
• Tuesday, December 16th, 8:00-11:00 AM
• Location: This Room
• Projects: End of Thursday, December 18th.
• Additional Lecture: Monday, 12/15 (2:30pm; 3405)































































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Material Type: Exam; Professor: Roth; Class: Machine Learning; Subject: Computer Science; University: University of Illinois - Urbana-Champaign; Term: Unknown 1989;
Typology: Exams
1 / 72

This page cannot be seen from the preview
Don't miss anything!
CS446-Fall 08
th
CS446-Fall 08
How many are there?
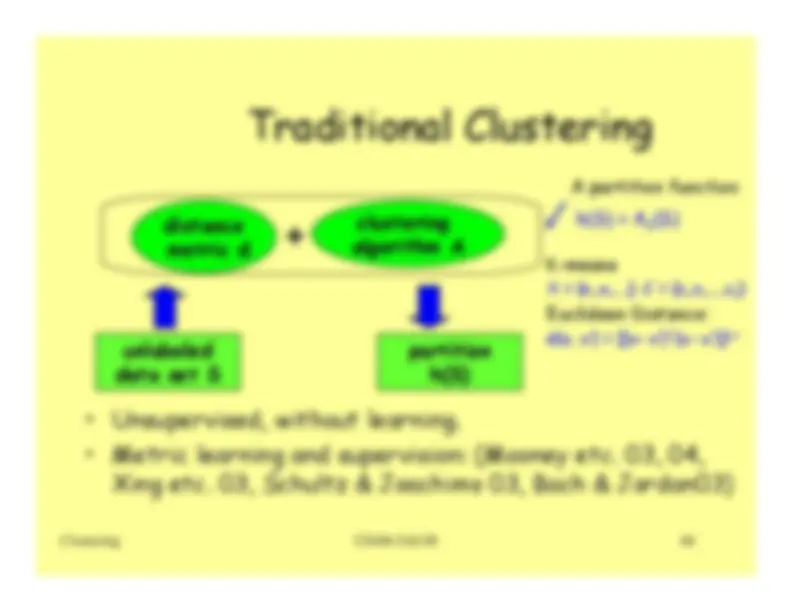
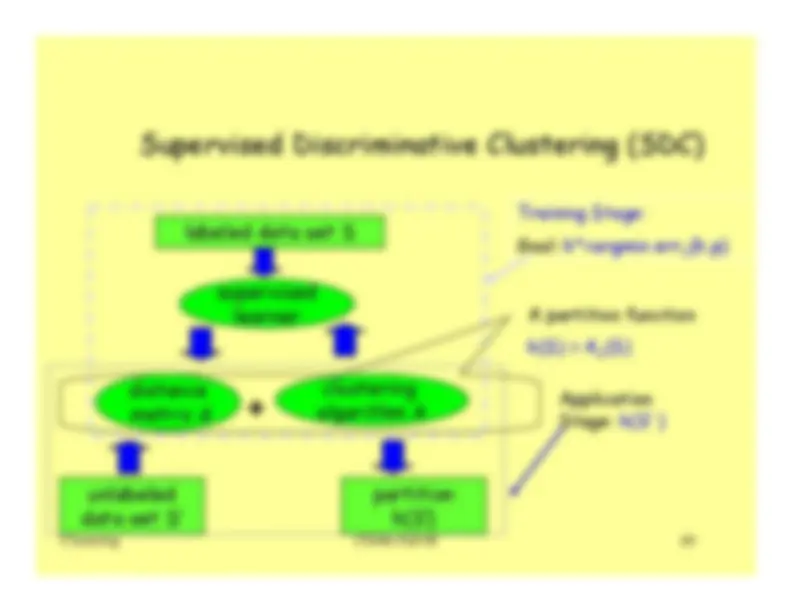
Clustering
CS446-Fall 08
Clustering
Clustering is a mode on unsupervised learning.
Given a collection of data points, the goal is to find structure in the
data: organize that data into sensible groups.
We are after a convenient and valid organization of the data, not after
a rule for separating future data into categories.
Cluster analysis is the formal study of algorithms and methods for
doing that.
Clustering
CS446-Fall 08
Clustering
A cluster is a set of entities which are alike, and entities in different
clusters are not alike.
A cluster is an aggregation of points in the test space such that^ the distance between any two points in the cluster is less than^ the distance between any point in the cluster and any point not in it.
Clusters may be described as connected regions of a multi^ dimensional space containing a relatively high density of points,^ separated from other regions by regions containing a low density^ of points.
CS446-Fall 08
Clustering
CS446-Fall 08
8
Clustering
Clustering is not a Learning Problem. It’s an Optimization Problem.^ Given a set of points and a pairwise
distance, devise an algorithm that
splits the data in such a way that optimizes some natural conditions. Scale-Invariance
.
For any distance function d and any
α
0,
we have f(d) = f(
α
· d)
.
Richness
. Range(f) is equal to the set of all partitions of S.
In other words, suppose we are given the names of the points only (i.e. theindices in
S
) but not the distances between them. Richness requires that for
any
desired partition
Γ
, it should be possible to construct a distance function
d
on
S
for which
f
( d
) =
Γ
Consistency.
Let d and d’
be two distance functions. If f(d) =
Γ
, and
d’
is a
Γ
transformation of
d
, then
f
( d’
) =
Γ
.
In other words, suppose that the clustering
Γ
arises from the distance function
d
.
If we now produce
d’
by reducing distances within the clusters and enlarging
distances between clusters then the same clustering
Γ
should arise from
d’
.
Theorem:
That is no clustering
function that maps a set of points intoa partition of it, that satisfies all threeconditions. [Klienberg, NIPS 2002]
CS446-Fall 08
The Clustering Problem
We are given a set of data points
that we would like
to cluster.
Each data point is assumed to be an d-dimensional vector, that we
will write as a column vector: (remember that for two vectors x, y
)
We do not make any statistical assumptions on the given data, nor
on the number of clusters.
m
2
1
x
x ,
x
T
d
2
1
x
x ,
(x
x
i
d
1 i^
i
T
y
x
y
x
CS446-Fall 08
Distance Measures
In studying Clustering techniques we will assume that we are given
a matrix of distances between all pairs of data points.
We can assume that the input to the problem is:
m
4
3
2
1
2 x
3
m x
4 x
x ,
d(x
j
i
CS446-Fall 08
Distance Measures
Examples
:
Euclidean Distance:
Manhattan Distance:
Infinity (Sup) Distance:
Notice that if
is the Euclidean metric,
is not a metric
but can be used as a measure (no triangle inequality)
d
1 i
2 i
i
T
2
y
(x
y)
(x
y)
(x
y)
(x
y)
d(x,
d
1 i^
i
i^
| y x | | y - x |
y)
d(x,
i
i
d i 1
(^2)
y)
d(x,
CS446-Fall 08
14
Distance Measures
Examples
:
Euclidean Distance:
Manhattan Distance:
Infinity (Sup) Distance:
d
1 i
2 i
i
T
2
y
(x
y)
(x
y)
(x
y)
(x
y)
d(x,
d
1 i^
i
i^
| y x | | y - x |
y)
d(x,
i
i
d i 1
1/
2
2
CS446-Fall 08
Distance Measures
The clustering may be sensitive to the similarity measure.
Sometimes this can be avoided by using a distance measure
that is invariant to some of the transformations that are natural to the problem.
Mahalanobis Distance: where
is a symmetric matrix.
y)
(x
y)
(x
y)
d(x,
T
CS446-Fall 08
Distance Measures
The clustering may be sensitive to the similarity measure.
Sometimes this can be avoided by using a distance measure
that is invariant to some of the transformations that are natural to the problem.
Mahalanobis Distance: where
is a symmetric matrix.
Covariance Matrix: Translates all the axes so that they have Mean=0 and Variance=1 (Shift and Scale invariance)
y)
(x
y)
(x
y)
d(x,
T
m x
m
size
of
matrix
data
the
of
average
vector,
column a ,
m
1 i
T
m
1 i^
i
)(x
(x
(^1) m
x
(^1) m
CS446-Fall 08
Distance Measures
Sometime it is useful to define distance^ between a data point x and a set A of points:
and distance between sets of points A, B:
There are many other ways to do it; may depend on the application.
A y
B y A, x
CS446-Fall 08
Basic Algorithms
Given: a set
of data points,
a distance function
and
a threshold T
will represent clusters,
their representative
i index into data points, j index into clusters
m
2
1
x
x ,
x
y)
d(x,
i C
i z
process data point i (where to place it?)
InitializeD o sequentially for all i:
1
1
1
ij^
i^
j
i^
j^
ij^
i^
i^
ij
i
: x
z
C
k
1
Let : D
d(x , z ),
for all j
1, ...k
D
M in D ,
I^
{j | D
D }
For each point i, find its cluster
If D
T
i
i^
I
k^
1
i^
k^
1
x
C
O therw ise :
k
k
1, z
x
C