Download Hard Disk Technology: Understanding Disk Tracks, Sectors, and RAID Levels and more Study notes Computer Architecture and Organization in PDF only on Docsity!
Device Subsystems
Magnetic Disk
- (^) A disk is a circular platter constructed of a non-
magnetic material called the substrate (aluminum),
coated with a magnetizable material (iron oxide…
rust)
—Improved surface uniformity
—Reduction in surface defects
- Reduced read/write errors
—greater ability to withstand shock and damage
—Better stiffness
—Better shock/damage resistance
Data organization
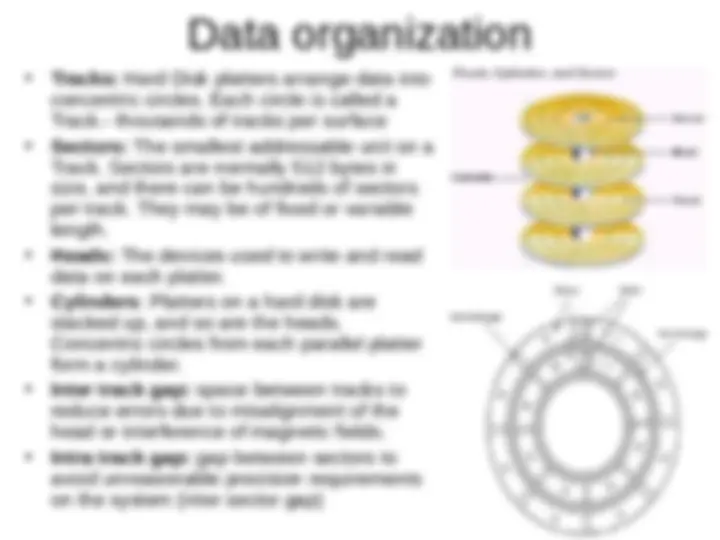
- (^) Tracks: Hard Disk platters arrange data into concentric circles. Each circle is called a Track.- thousands of tracks per surface
- (^) Sectors: The smallest addressable unit on a Track. Sectors are normally 512 bytes in size, and there can be hundreds of sectors per track. They may be of fixed or variable length.
- (^) Heads: The devices used to write and read data on each platter.
- (^) Cylinders : Platters on a hard disk are stacked up, and so are the heads. Concentric circles from each parallel platter form a cylinder.
- (^) Inter track gap: space between tracks to reduce errors due to misalignment of the head or interference of magnetic fields.
- (^) Intra track gap: gap between sectors to avoid unreasonable precision requirements on the system (inter sector gap)
Constant angular velocity (CAV)
- (^) There is a variation in speed of reading a bit near
the center of a disk and a bit on the outside. This
can be avoided by increasing the space between
bits of information recorded in segments of the disk.
- (^) This info can be scanned at the same rate by
rotating the disk at a fixed speed (CAV)
- (^) Advantage:
- (^) individual blocks of data can be directly addressed by track of sector.
- (^) The head can be moved to a specific address faster
- (^) Disadvantage: the amount of data that can be
stored on the long outer tracks is the same as on
the short inner tracks.=> density is reduced
Disk Track Format
- (^) ID – to locate a particular sector
- (^) Synch – delimits the beginning of the field
- (^) Track – identifies a track on the surface
- (^) Head – identifies a head
- (^) ID and data fields have error detecting codes (CRC)
characteristics
- (^) Head motion
- (^) Fixed: one read/write head per track (rare)
- Movable: only one read – write head per surface
- (^) Disk portability
- (^) Removable: can be removed and replaced with the other
- (^) Non-removable: permanently mounted in the disk drive (ex: hard disk)
- (^) Sides:
- Single sided: magnetizable coating applied on one side
- (^) Double sided: (usually) two sides coated
- (^) Platters:
- Multiple patters: disk drives accommodate multiple platters vertically a fraction of an inch apart
- (^) Single patter
- (^) Head mechanism
- (^) Contact (floppy): head comes into contact during the operation
- (^) Fixed gap
- (^) Flying (winchester)
Disk performance parameters
• Seek time: on a movable head, time it takes
to position the head at the track
• Rotational delay/latency: the time it takes for
the beginning of the sector to reach the head
• Access time: seek time + latency
- (^) Time it takes to get into position to read or write
• Transfer time: time required to transfer data
T = b/r*N, where b is the number of bytes to
be transferred, r is the rotation speed and N
is the number of bytes on a track
Average access time Ta = Ts + 1/2r + b/rN,
where Ts is average seek time
RAID (redundant array of independent disks)
- (^) Redundant array of inexpensive disks
- (^) Multiple disk database design
- (^) Not a hierarchy
- (^) 7 levels (6 levels in common use)
- (^) Set of physical disk drives viewed by the OS as a
single logical drive
- (^) Data are distributed across the physical drives of
an array
- (^) Redundant disk capacity is used to store parity
information => data recoverability
- (^) Improve access time and improve reliability
Data Mapping for RAID Level 0
- (^) This software may execute either in the disk sub system or in a host computer
RAID Level 1
- (^) Redundancy achieved through duplicating all data.
- (^) Data stripping is similar to RAID level 0.
- (^) Each logic strip is mapped to two physical disks.
- (^) Read request can be serviced from either of available 2 disks, which ever involves the minimum seek time and rotational latency
- (^) Write request requires both disks to be updated – but this can be done in parallel. (Slower write dictates overall speed).
- (^) Recover from failure is simple! (data may still be accessed from the second drive
- (^) Disadvantage:
- (^) Cost
- (^) requires twice the disk space
- (^) Configuration is limited, so used only for system software and other highly critical files.
- (^) Improvement occurs if the application can split each read request so that both disk members participate
RAID Level 2
- (^) Utilizes parallel access techniques - All disks participate in the execution of every I/O request.
- (^) Spindles of individual drives are synchronized so that each disk head is in the same position on each disk at any given time.
- (^) Data striping – very small strips (single byte or word).
- (^) Error correcting code is calculated across corresponding bits on each disk, and the code bits are stored in corresponding bit positions on multiple parity disks.
- (^) For Hamming Code – number of parity (redundant) disks is proportionate to the log of the number of data disks.
- (^) On a single read, all disks are simultaneously accessed. The requested data and the associated error correcting code are delivered to the array controller. Array controller can detect and fix single bit errors.
- (^) For write – all disks must be accessed.
- (^) Good choice – only for an environment in which many errors occur – therefore not used much (given high reliability if individual disks and disk drives).
RAID Level 3
Similar to RAID 2 – parallel access with data distributed in small strips. Requires only a single redundant disk because it uses a single parity bit for the set of individual bits in the same position on all of the data disks. If drives X0-X3 contain data, and X4 contains parity bits. X4(i) = X3(i) X2(i) X1(i) X0(i) Redundancy – in the case of disk failure, the data can be reconstructed. If drive X1 fails – it can be reconstructed as: X1(i) = X4(i) X3(i) X2(i) X0(i) Performance – can achieve high transfer rates, but only one I/O request can be executed at one time. (Better for large data transfers in non transaction- oriented environments).
RAID Level 5
- (^) Same as RAID 4 – but parity strips are distributed across all disks.
- (^) Typical allocation uses round-robin.
- (^) For an n-disk array, the parity strip is on a different disk for the first n strips and the pattern then repeats.
- (^) Avoids potential bottleneck found in RAID 4.
RAID Level 6
- (^) Two different parity calculations are carried out and stored in separate blocks on different disks. - (^) Example: XOR and an independent data check algorithm => makes it possible to regenerate data even if two disks containing user data fail.
- (^) No. of disks required = N + 2 (where N = number of disks required for data).
- (^) Provides HIGH data availability.
- (^) Incurs substantial write penalty as each write affects two parity blocks.