Download Understanding Virtual Memory and Paging: A Deep Dive into Memory Management - Prof. Willia and more Exams Computer Science in PDF only on Docsity!
Computer Architecture and
Performance:
Virtual Memory
William Gropp
Virtual Memory
• So far, we’ve assumed that the
process is addressing “memory”
• In most systems, (user) processes
use “virtual” addresses
♦ Gives the process the illusion that it
directly addresses all real memory
♦ Gives the process the illusion that
there is more real memory than is
really available
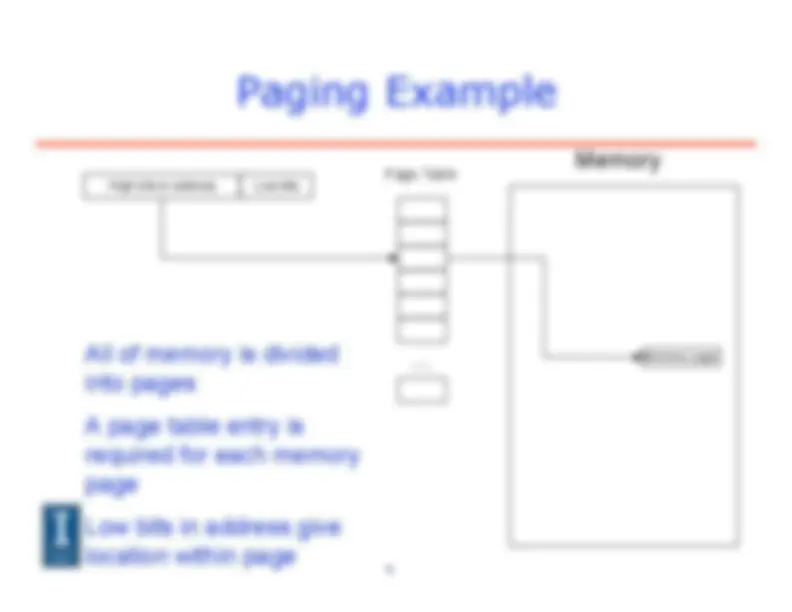
Paging Example
High bits in address Low bits … Page Table Memory All of memory is divided^ Memory page into pages A page table entry is required for each memory page Low bits in address give location within page
Implementing Paging
- Virtual memory introduces some costs because the virtual address must be translated to a physical address
- Consider this case: ♦ Let each page contain 4k bytes - A common size ♦ Address uses lower 12 bits to represent location in the page ♦ Upper bits give page number - For a 32-bit address space (4GB of memory), use the top 20 bits
- For each page number, there is a corresponding location ♦ Either in physical (real) memory ♦ On “backing store” (in the swap file on disk)
Paging Example With Cache
High bits in address Low bits … Page Table (^) Memory Memory page Look for this index in cache If found If not found, lookup and replace entry in cache
Translation Lookaside Buffer
(TLB)
- The page mapping cache is called a
Translation Lookaside Buffer (TLB)
♦ Lookup is not easy when it has to be very fast ♦ As a result, TLBs are often small but fast enough to return physical address quickly
- What happens on a page miss (entry is
not in the TLB)?
♦ Fetch entry from memory (the whole page table isn’t big relative to main (DRAM) memory
TLB Revisited
- When an page location is not found in the TLB, first find the entry in the page table ♦ Requires a memory read - latencies of 20 to 100s of cycles.
- Determine if the page is stored in the main memory (resident) or has been moved to slower disk storage ♦ If resident, replace a TLB entry with the location of this page and return the physical address ♦ If not resident, transfer control to the operating system to handle a page fault - A page fault has latencies in milliseconds (time to find and read data from disk)
Impact on Algorithms
- Large cost if data outside of TLB set is accessed frequently
- Consider the transpose example with a 2048 x 2048 matrix and a TLB with 64 entries
- Each entry an 8-byte double precision value
Transpose with 4K pages:
• Each column of the matrix requires
4 pages
♦ A page is mapped for stores every
512 rows
♦ A page is mapped for loads on every
column:
- Use only a single entry from a page before going to the next one
- Process 2k-1 pages before returning to a previous page
- Every load incurs a TLB miss
Transpose with 64k pages
• 4 columns per page
♦ It takes 512 pages to cover one row
of the matrix
♦ But get 4 values out of each page
- Every fourth load incurs a TLB miss
Observations
- Note that the TLB and the L1/L2/L3 cache have different behavior ♦ For example, consider 512 separate cache lines of 128 bytes each ♦ Only 64K bytes of storage ♦ But if they are in 512 different pages, each reference may incure a TLB miss, even though data fits within cache!
- If a page is located in secondary media, performance may be orders of magnitude lower ♦ Drop in performance is severe and sudden
- Large pages can give modest (several loads satisfied from each page) or large improvements in performance (no extra TLB misses)
Discussion Questions
- Architecture Issues ♦ TLB is often very small ♦ Even regular accesses (as in the strided accesses in transpose) can cause problems - Can hardware effectively predict pages and preload a guess at the next TLB entry? - Can alternative approaches be used? − If there was more or different information from the program, would other architectural solutions be practical?
- Programming Model Issues ♦ Optimizing the transpose code appears simple - Blocking for cache and TLB is straightforward - Why don’t compilers (usually) generate good code for this case?
Double Buffering and Asynchronous I/O
- Out of core algorithms replied on double buffering. Pseudo code looks like this:
- Load A with data Initiated nonblocking load of B with data to be used later while (not done) { work on data in A initiate nonblocking load of A with data to be used later wait for load of B to complete swap pointers to A and B }
- These algorithms can address problems with TLB misses, even to secondary storage
- But they are hard to implement in practice. Why?
Challenges in Implementing
Out of Core Algorithms
- Most programming models provide no support for asynchronous operations ♦ It is nearly impossible to robustly use nonblocking operations in Fortran because of the language design - Compiler may “optimize” around calls to library routines that implement nonblocking or asynchronous operations
- A key part of the algorithm is performing work while the “other” buffer is filled with data ♦ How much work? ♦ Does the work (computation) overlap (take place at the same time) with filling the buffer (communication)? - Programming models and hardware may support the operation without making it efficient