Download Computer Networks Unit 3
Data link layer and more Study notes Computer Networks in PDF only on Docsity!
UNIT-
Data link layer: Error Detection and Correction, Framing, flow and error control,
Protocols - Noiseless channels (Simplest, Stop and Wait) and Noisy channels (Stop and
Wait and Piggy Backing). Multiple Access Protocols. Random Access-ALOHA, CSMA.
Wired LANs-IEEE standards, wireless LANs-Bluetooth, Cellular Telephony
Data Link Layer :- Error Detection and Correction Data can be corrupted during transmission. Some applications require that errors be detected and corrected whenever bits flow from one point to another, interference can change the shape of the signal. Types of Errors Whenever bits flow from one point to another, they are subject to unpredictable changes because of interference. This interference can change the shape of the signal.
Single-Bit Error The term single-bit error means that only 1 bit of a given data unit (such as a byte, character, or packet) is changed from 1 to 0 or from 0 to 1.
Burst Error The term burst error means that 2 or more bits in the data unit have changed from 1 to 0 or from 0 to 1. A burst error means that 2 or more bits in the data unit have changed. The length of the burst is measured from the first corrupted bit to the last corrupted bit. Some bits in between may not have been corrupted.
Redundancy The central concept in detecting or correcting errors is redundancy. To be able to detect or correct errors, we need to send some extra bits with our data. These redundant bits are added by the sender and removed by the receiver. Their presence allows the receiver to detect or correct corrupted bits.
Coding Redundancy is achieved through various coding schemes. Coding schemes divided into two
broad categories: block coding and convolution coding(complex).
The idea of coding- The structure of encoder and decoder
BLOCK CODING
In block coding, we divide our message into blocks, each of k bits, called datawords. We add r redundant bits to each block to make the length n = k + r. The resulting n-bit blocks are called codewords. The block coding process is one-to-one; the same dataword is always encoded as the same codeword. This means that we have 2n - 2k codewords that are not used. We call these codewords invalid or illegal. Datawords and codewords in block coding
Example :- The 4B/5B block coding discussed in Chapter 4 is a good example of this type of coding. In this coding scheme, k =4 and n =5. As we saw, we have 2k =16 datawords and 2n =32 codewords. We saw that 16 out of 32 codewords are used for message transfer and the rest are either used for other purposes or unused.
Error Correction
There are two main methods of error correction
Forward Error Correction :- It is the process in which the receiver tries to guess the message by using redundant bits. This is possible, if the number of errors is small. Backward Error Correction (Retransmission) When the receiver detects an error in the data received, it requests back the sender to retransmit the data unit. It is a technique in which the receiver detects the occurrence of an error and asks the sender to resend the message. Resending is repeated until a message arrives that the receiver believes is error-free.
In a set of words, the minimum Hamming distance is the smallest Hamming distance between all possible pairs. We use dmin to define the minimum Hamming distance in a coding scheme. To find this value, we find the Hamming distances between all words and select the smallest one. E.g:-
The dmin in this case is 2. E:g:-
The dmin in this case is 3. When a codeword is corrupted during transmission, the Hamming distance between the sent and received codewords is the number of bits affected by the error. In other words, the Hamming distance between the received codeword and the sent codeword is the number of bits that are corrupted during transmission. E.g:- if the codeword 00000 is sent and 01101 is received, 3 bits are in error and the Hamming distance between the two is d(OOOOO, 01101) =3. To guarantee the detection of up to s errors in all cases, the minimum Hamming distance in a block code must be dmin = S + 1. To guarantee correction of up to t errors in all cases, the minimum Hamming distance in a block code must be dmin == 2t + 1.
Error Detection If the following two conditions are met, the receiver can detect a change in the original codeword.
- The receiver has (or can find) a list of valid codewords.
- The original codeword has changed to an invalid one.
The sender creates codewords out of datawords by using a generator that applies the rules and procedures of encoding .Each codeword sent to the receiver may change during transmission. If the received codeword is the same as one of the valid codewords, the word is accepted; the corresponding dataword is extracted for use. If the received codeword is not valid, it is discarded. However, if the codeword is corrupted during transmission but the received word still matches a valid codeword, the error remains undetected. This type of coding can detect only single errors. Two or more errors may remain undetected. Process of error detection in block coding
Assume the sender encodes the dataword 01 as 011 and sends it to the receiver. Consider the following cases:
The receiver receives 011. It is a valid codeword. The receiver extracts the dataword 01 from it.
The codeword is corrupted during transmission, and 111 is received (the leftmost bit is corrupted).This is not a valid codeword and is discarded.
The codeword is corrupted during transmission, and 000 is received (the right two bits are corrupted). This is a valid codeword. The receiver incorrectly extracts the dataword 00. Two corrupted bits have made the error undetectable. Some popular techniques for error detection are:
Simple Parity check
Checksum
Cyclic redundancy check(CRC)
LINEAR BLOCK CODES
Almost all block codes used today belong to a subset called linear block codes. A linear block code is a code in which the exclusive OR (XOR-addition modulo-2) of two valid codewords creates another valid codeword. The above defined code word table(Table 1) is a linear block code because the result of XORing any code words, with any other code words is a valid code word. E.g:- the XORing of the second and third codewords creates the fourth one. The minimum Hamming distance is the number of Is in the nonzero valid codeword with the smallest number of Is. In the TABLE 1 the numbers of Is in the nonzero codewords are 3, 3, and 4. So in this code we have dmin =3.
Two types of linear block codes are
1. Simple Parity-Check Code It the most familiar error-detecting code is the simple parity-check code. In this code, a k- bit dataword is changed to an n-bit codeword where n = k + 1. The extra bit, called the parity bit, is selected to make the total number of Is in the codeword even. A simple parity-check code is a single-bit error-detectingcode in which n = k + 1 with dmin =2.
A copy of a 4-bit dataword is fed into the generator that creates three parity checks ro, rl and r2 as shown below: r 0 = a 2 + a 1 + a 0 r 1 = a 2 + a 1 + a 3 r 2 = a 3 + a 0 + a 1
The checker in the decoder creates a 3-bit syndrome (s2s1s0) in which each bit is the parity check for 4 out of the 7 bits in the received codeword: s 0 =b 2 +b 1 +b 0 +q 0 s 1 =b 3 +b 2 +b 1 +q 1 s 2 =b 1 +b 0 +b 3 +q 2 The equations used by the checker are the same as those used by the generator with the parity- check bits. The 3-bit syndrome creates eight different bit patterns (000 to 111) that can represent eight different conditions.
The marked 4 cases not concerned because there is either no error or an error in the parity bit. if qo is in error, So is the only bit affected; the syndrome, therefore, is 001. It can correct a single error or detect a double error its dmin =3. E:g:-
- The dataword 0100 becomes the codeword 0100011. The codeword 01 00011 is received. The syndrome is 000 (no error), the final dataword is 0100.
- The dataword 0111 becomes the codeword 0111001. The codeword 0011001 is received. The syndrome is 011. According to Table 10.5, b 2 is in error. After flipping b 2 (changing the 1 to 0), the final dataword is 0111.
- The dataword 1101 becomes the codeword 1101000. The codeword 0001000 is received (two errors). The syndrome is 101, which means that bo is in error. After flipping b 0 , we get 0000, the wrong dataword. This shows that our code cannot correct two errors.
CYCLIC CODES
Cyclic codes are special linear block codes with one extra property. In a cyclic code, if a codeword is cyclically shifted (rotated), the result is another codeword. For example, if 1011000 is a codeword and we cyclically left-shift, then 0110001 is also a codeword. In this case, if we call the bits in the first word ao to a6' and the bits in the second word bo to b 6 ,
Cyclic Redundancy Check
The cyclic redundancy check (CRC) is a error detecting code that is used in networks such as LANs and WANs.
In the encoder, the dataword has k bits (4 here); the codeword has n bits (7 here). The size of the dataword is augmented by adding n - k (3 here) Os to the right-hand side of the word. The n-bit result is fed into the generator. The generator uses a divisor of size n - k + I ( here), predefined and agreed upon. The generator divides the augmented dataword by the divisor (modulo-2 division). The quotient of the division is discarded; the remainder (r2rl ro) is appended to the dataword to create the codeword. The decoder receives the possibly corrupted codeword. A copy of all n bits is fed to the checker which is a replica of the generator. The remainder produced by the checker is a syndrome of n - k (3 here) bits, which is fed to the decision logic analyzer. If the syndrome bits are all as, the 4 leftmost bits of the codeword are accepted as the dataword (interpreted as no error); otherwise, the 4 bits are discarded (error).
CHECKSUM
The checksum is used in the Internet by several protocols although not at the data link layer. The checksum is based on the concept of redundancy. Suppose our data is a list of five 4-bit numbers that we want to send to a destination. In addition to sending these numbers, we send the sum of the numbers. E.g:- if the set of numbers is (7, 11, 12, 0, 6), we send (7, 11, 12,0,6,36), where 36 is the sum of the original numbers. The receiver adds the five numbers and compares the result with the sum. If the two are the same, the receiver assumes no error, accepts the five numbers, and discards the sum. Otherwise, there is an error somewhere and the data are not accepted. To make the job of the receiver easier if we send the negative (complement) of the sum, called the checksum. In this case, we send (7, 11, 12,0,6, -36). The receiver can add all the numbers received (including the checksum). If the result is 0, it assumes no error; otherwise, there is an error. One major drawback.of this is all of our data can be written as a 4-bit word (they are less than 15) except for the checksum. One solution is to use one's complement arithmetic. E:g:- To represent the number 21 in one's complement arithmetic using only four bits. The number 21 in binary is 10101 (it needs five bits). We can wrap the leftmost bit and add it to the four rightmost bits. We have (0101 + 1) = 0110 or 6. We can represent the number -6 in one's complement arithmetic using only four bits. The negative or complement of a number is found by inverting all bits. Positive 6 is 0110; negative 6 is 100I. If we consider only unsigned numbers, this is 9. In other words, the complement of 6 is 9.
The Internet has been using a 16-bit checksum. The sender calculates the checksum by following these steps. Sender site:
- The message is divided into 16-bit words.
- The value of the checksum word is set to O.
- All words including the checksum are added ushtg one's complement addition.
- The sum is complemented and becomes the checksum.
- The checksum is sent with the data. The receiver uses the following steps for error detection. Receiver site:
- The message (including checksum) is divided into 16-bit words.
- All words are added using one's complement addition.
- The sum is complemented and becomes the new checksum.
- If the value of checksum is 0, the message is accepted; otherwise, it is rejected.
FRAMING The physical layer provides bit synchronization to ensure that the sender and receiver use the same bit durations and timing. The data link layer, needs to pack bits into frames, so that each frame is distinguishable from another. Framing in the data link layer separates a message from one source to a destination, or from other messages to other destinations, by adding a sender address and a destination address. When a message is divided into smaller frames, a single-bit error affects only that small frame. Frames can be divided in to two types. Frames can be of fixed or variable size 1) Fixed-Size Framing In this there is no need for defining the boundaries of the frames; the size itself can be used as a delimiter. An example of this type of framing is the ATM wide-area network, which uses frames of fixed size called cells. 2)Variable-Size Framing It used in local area networks. In variable-size framing, we need a way to define the end of the frame and the beginning of the next. Two approaches were used for this purpose: a character-oriented approach and a bit-oriented approach.
Character-Oriented Protocols In a character-oriented protocol, data to be carried are 8-bit characters from a coding system such as ASCII. The header, which normally carries the source and destination addresses and other control information, and the trailer, which carries error detection or error correction redundant bits, are also multiples of 8 bits. To separate one frame from the next, an 8-bit (I- byte) flag is added at the beginning and the end of a frame. The flag, composed of protocol- dependent special characters, signals the start or end of a frame. A frame in a character-oriented protocol
FLOW AND ERROR CONTROL
The most important responsibilities of the data link layer are flow control and error control.
Collectively, these functions are known as data link control.
Flow control refers to a set of procedures used to restrict the amount of data that the sender
can send before waiting for acknowledgment.
Error control is both error detection and error correction. It allows the receiver to
inform the sender of any frames lost or damaged in transmission and coordinates the
retransmission of those frames by the sender. Any time an error is detected in an exchange,
specified frames are retransmitted. This process is called automatic repeat request (ARQ).
Error control in the data link layer is based on automatic repeat request, which is the
retransmission of data.
NOISELESS CHANNELS
Let us first assume we have an ideal channel in which no frames are lost, duplicated, or
corrupted. Two protocols for this type of channel. The first is a protocol that does not use flow
control; the second is the one that does. Of course, neither has error control because we have
assumed that the channel is a perfect noiseless channel.
Simplest Protocol
It is one that has no flow or error control. There is no need for flow control in this scheme.
The data link layer at the sender site gets data from its network layer, makes a frame out of the
data, and sends it. The data link layer at the receiver site receives a frame from its physical
layer, extracts data from the frame, and delivers the data to its network layer. The data link
layers of the sender and receiver provide transmission services for their network layers. The
data link layers use the services provided by their physical layers (such as signaling,
multiplexing, and so on) for the physical transmission of bits.
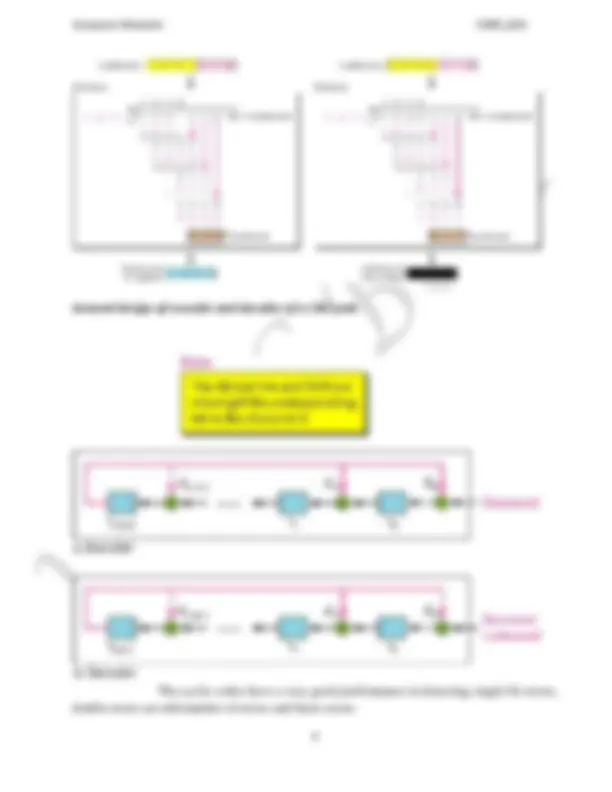
The flow diagram The design of the simplest protocol with no flow or error control
Sender-site algorithm for the simplest protocol
Sender-site algorithm for Stop-and-Wait Protocol
Receiver-site algorithm for Stop-and-Wait Protocol
A simple canSend variable that can either be true or false. When a frame is sent, the variable
is set to false to indicate that a new network request cannot be sent until canSend is true. When
an ACK is received, canSend is set to true to allow the sending of the next frame.
Flow diagram.
NOISY CHANNELS
Stop-and-Wait Automatic Repeat Request Stop-and-Wait Automatic Repeat Request (Stop-and-Wait ARQ), adds a simple error control
mechanism to the Stop-and-Wait Protocol. Let us see how this protocol detects and corrects
errors. To detect and correct corrupted frames, we need to add redundancy bits to our data
frame. When the frame arrives at the receiver site, it is checked and if it is corrupted, it is
silently discarded. The detection of errors in this protocol is manifested by the silence of the
receiver. Lost frames are more difficult to handle than corrupted ones.
Error correction in Stop-and-Wait ARQ is done by keeping a copy of the sent frame and
retransmitting of the frame when the timer expires. Since an ACK frame can also be corrupted
and lost, it too needs redundancy bits and a sequence number. The ACK frame for this protocol
has a sequence number field. In this protocol, the sender simply discards a corrupted ACK
frame or ignores an out-of-order one.
Receiver-site algorithm for Stop-and-Wait ARQ Protocol
Error correction in Stop-and-Wait ARQ is done by keeping a copy of the sent frame and
retransmitting of the frame when the timer expires. In Stop-and-Wait ARQ~ we use sequence
numbers to number the frames. The sequence numbers are based on modul0-2 arithmetic. In
Stop-and-WaitARQ~the acknowledgment number always announces in modul0-2 arithmetic
the sequence number ofthe next frame expected.
Go-Back-N Automatic Repeat Request
To improve the efficiency of transmission (filling the pipe), multiple frames must be in
transition while waiting for acknowledgment. In other words, we need to let more than one
frame be outstanding to keep the channel busy while the sender is waiting for
acknowledgment. The first is called Go-Back-N Automatic Repeat Request. In this protocol
we can send several frames before receiving acknowledgments; we keep a copy of these
frames until the acknowledgments arrive. In this protocol , the sliding window is an abstract
concept that defines the range of sequence numbers that is the concern of the sender and
receiver. I.e, the sender and receiver need to deal with only part of the possible sequence
numbers. The range which is the concern of the sender is called the send sliding window; the
range that is the concern of the receiver is called the receive sliding window.