Download Discrete Random Variables & Probability Distributions: A Comprehensive Guide and more Exercises Statistics in PDF only on Docsity!
1. DISCRETE RANDOM VARIABLES
1.1. Definition of a Discrete Random Variable. A random variable X is said to be discrete if it can assume only a finite or countable infinite number of distinct values. A discrete random variable can be defined on both a countable or uncountable sample space.
1.2. Probability for a discrete random variable. The probability that X takes on the value x, P(X=x), is defined as the sum of the probabilities of all sample points in Ω that are assigned the value x. We may denote P(X=x) by p(x) or pX (x). The expression pX (x) is a function that assigns probabilities to each possible value x; thus it is often called the probability function for the random variable X.
1.3. Probability distribution for a discrete random variable. The probability distribution for a discrete random variable X can be represented by a formula, a table, or a graph, which provides pX (x) = P(X=x) for all x. The probability distribution for a discrete random variable assigns nonzero probabilities to only a countable number of distinct x values. Any value x not explicitly assigned a positive probability is understood to be such that P(X=x) = 0.
The function pX (x)= P(X=x) for each x within the range of X is called the probability distribution of X. It is often called the probability mass function for the discrete random variable X.
1.4. Properties of the probability distribution for a discrete random variable. A function can serve as the probability distribution for a discrete random variable X if and only if it s values, pX (x), satisfy the conditions:
a: pX (x) ≥ 0 for each value within its domain b:
x pX^ (x) = 1^ ,^ where the summation extends over all the values within its domain
1.5. Examples of probability mass functions.
1.5.1. Example 1. Find a formula for the probability distribution of the total number of heads ob- tained in four tosses of a balanced coin.
The sample space, probabilities and the value of the random variable are given in table 1. From the table we can determine the probabilities as
P (X = 0) =
, P (X = 1) =
, P (X = 2) =
, P (X = 3) =
, P (X = 4) =
Notice that the denominators of the five fractions are the same and the numerators of the five fractions are 1, 4, 6, 4, 1. The numbers in the numerators is a set of binomial coefficients.
We can then write the probability mass function as
Date : January 30, 2008. 1
TABLE 1. Probability of a Function of the Number of Heads from Tossing a Coin Four Times.
Table R. Tossing a Coin Four Times Element of sample space Probability Value of random variable X (x) HHHH 1/16 4 HHHT 1/16 3 HHTH 1/16 3 HTHH 1/16 3 THHH 1/16 3 HHTT 1/16 2 HTHT 1/16 2 HTTH 1/16 2 THHT 1/16 2 THTH 1/16 2 TTHH 1/16 2 HTTT 1/16 1 THTT 1/16 1 TTHT 1/16 1 TTTH 1/16 1 TTTT 1/16 0
pX (x) =
x
f or x = 0 , 1 , 2 , 3 , 4 (2)
Note that all the probabilities are positive and that they sum to one.
1.5.2. Example 2. Roll a red die and a green die. Let the random variable be the larger of the two numbers if they are different and the common value if they are the same. There are 36 points in the sample space. In table 2 the outcomes are listed along with the value of the random variable associated with each outcome. The probability that X = 1, P(X=1) = P[(1, 1)] = 1/36. The probability that X = 2, P(X=2) = P[(1, 2), (2,1), (2, 2)] = 3/36. Continuing we obtain
P (X =1) =
, P (X = 2) =
, P (X = 3) =
P (X =4) =
, P (X = 5) =
, P (X = 6) =
We can then write the probability mass function as
pX (x) = P (X = x) =
2 x − 1 36
f or x = 1 , 2 , 3 , 4 , 5 , 6
Note that all the probabilities are positive and that they sum to one.
1.6. Cumulative Distribution Functions.
FX (x) =
0 f or x < 0 1 16 f or^0 ≤^ x <^1 5 16 f or^1 ≤^ x <^2 11 16 f or^2 ≤^ x <^3 15 16 f or^3 ≤^ x <^4 1 f or x ≥ 4
1.6.4. Second example of a cumulative distribution function. Consider a group of N individuals, M of whom are female. Then N-M are male. Now pick n individuals from this population without replacement. Let x be the number of females chosen. There are
(M
x
ways of choosing x females
from the M in the population and
(N − M
n − x
ways of choosing n-x of the N - M males. Therefore,
there are
(M
x
×
(N − M
n − x
ways of choosing x females and n-x males. Because there are
(N
n
ways of choosing n of the N elements in the set, and because we will assume that they all are equally likely the probability of x females in a sample of size n is given by
pX (x) = P (X = x) =
(M
x
) (N − M
n − x
(N
n
) f or x = 0 , 1 , 2 , 3 , · · · , n
and x ≤ M, and n − x ≤ N − M.
For this discrete distribution we compute the cumulative density by adding up the appropriate terms of the probability mass function.
F (0) = p(0) F (1) = p(0) + p(1) F (2) = p(0) + p(1) + p(2) F (3) = p(0) + p(1) + p(2) + px(3) .. . F (n) = p(0) + p(1) + p(2) + p(3) + · · · + p(n)
Consider a population with four individuals, three of whom are female, denoted respectively by A, B, C, D where A is a male and the others are females. Then consider drawing two from this population. Based on equation 4 there should be
2
= 6 elements in the sample space. The sample space is given by
TABLE 3. Drawing Two Individuals from a Population of Four where Order Does Not Matter (no replacement)
Element of sample space Probability Value of random variable X AB 1/6 1 AC 1/6 1 AD 1/6 1 BC 1/6 2 BD 1/6 2 CD 1/6 2
We can see that the probability of 2 females is 12. We can also obtain this using the formula as follows.
p(2) = P (X = 2) =
2
0
2
Similarly
p(1) = P (X = 1) =
1
1
2
We cannot use the formula to compute P(0) because (2 - 0) 6 ≤ (4 - 3). P(0) is then equal to 0. We can then compute the cumulative distribution function as
F (0) = p(0) = 0
F (1) = p(0) + p(1) =
F (2) = p(0) + p(1) + p(2) = 1
1.7. Expected value.
1.7.1. Definition of expected value. Let X be a discrete random variable with probability function pX (x). Then the expected value of X, E(X), is defined to be
E(X) =
x
x pX (x) (9)
if it exists. The expected value exists if ∑
x
| x | pX (x) < ∞ (10)
The expected value is kind of a weighted average. It is also sometimes referred to as the popu- lation mean of the random variable and denoted μX.
1.7.2. First example computing an expected value. Toss a die that has six sides. Observe the number that comes up. The probability mass or frequency function is given by
pX (x) = P (X = x) =
1 6 f or x^ =^1 ,^2 ,^3 ,^4 ,^5 ,^6 0 otherwise
We compute the expected value as
E(X) =
x ǫ X
x pX (x)
∑^6
i = 1
i
for all i = 1, 2,... m. Here p∗(gi) is the probability that the experiment results in a value for the function f of the initial random variable of gi. Using the definition of expected value in equation we obtain
E[g(X)] =
∑^ m
i = 1
gi p∗(gi). (18)
Now substitute in to obtain
E[g(X)] =
∑^ m
i = 1
gi p∗(gi).
∑^ m
i = 1
gi
∀ xj ∋ g ( xj ) = gi
p ( xj )
∑^ m
i = 1
∀ xj ∋ g ( xj ) = gi
gi p ( xj )
∑^ n
j = 1
g (xj ) p( xj ).
1.9. Properties of mathematical expectation.
1.9.1. Constants.
Theorem 2. Let X be a discrete random variable with probability function p X (x) and c be a constant. Then E(c) = c.
Proof. Consider the function g(X) = c. Then by theorem 1
E[c] ≡
x
c pX (x) = c
x
pX (x) (20)
But by property 1.4b, we have
∑
x
pX (x) = 1
and hence
E (c) = c · (1) = c. (21)
�
1.9.2. Constants multiplied by functions of random variables.
Theorem 3. Let X be a discrete random variable with probability function p X (x), g(X) be a function of X, and let c be a constant. Then
E [ c g ( X ) ] ≡ c E [ (g ( X ) ] (22)
Proof. By theorem 1 we have
E[c g(X)] ≡
x
c g(x) pX (x)
= c
x
g(x) pX (x)
= c E[g(X)]
1.9.3. Sums of functions of random variables.
Theorem 4. Let X be a discrete random variable with probability function p X (x), g 1 (X), g 2 (X), g 3 (X), · · · , gk(X) be k functions of X. Then
E [g 1 (X) + g 2 (X) + g 3 (X) + · · · + gk(X)] ≡ E[g 1 (X)] + E[g 2 (X)] + · · · + E[gk(X)] (24)
Proof for the case of k = 2. By theorem 1 we have we have
E [g 1 (X) + g 2 (X) ] ≡
x
[g 1 (x) + g 2 (x) ] pX (x)
x
g 1 (x) pX (x) +
x
g 2 (x) pX (x)
= E [g 1 (X) ] + E [ g 2 (X)] ,
1.10. Variance of a random variable.
1.10.1. Definition of variance. The variance of a random variable X is defined to be the expected value of (X − μ)^2. That is
V (X) = E
[
( X − μ )^2
]
The standard deviation of X is the positive square root of V(X).
1.10.2. Example 1. Consider a random variable with the following probability distribution.
TABLE 5. Probability Distribution for X
x pX (x) 0 1/ 1 1/ 2 3/ 3 1/
E(X) =
x ǫ X
x pX (x)
∑^6
i = 1
i
We compute the variance by then computing the E(X^2 ) as follows
E(X^2 ) =
x ǫ X
x^2 pX (x)
∑^6
i = 1
i^2
We can then compute the variance using the formula Var(X) = E(X 2 ) - E 2 (X) and the fact the E(X) = 21/6 from equation 33.
V ar(X) = E (X^2 ) − E^2 (X)
2. THE ”DISTRIBUTION” OF RANDOM VARIABLES IN GENERAL
2.1. Cumulative distribution function. The cumulative distribution function (cdf) of a random variable X, denoted by FX (·), is defined to be the function with domain the real line and range the interval [0,1], which satisfies FX (x) = PX [X ≤ x] = P [ { ω : X(ω) ≤ x } ] for every real number x. F has the following properties:
FX (−∞) = lim x→ −∞ FX (x) = 0, FX (+∞) = lim x→ +∞ FX (x) = 1, (36a)
FX (a) ≤ FX (b) f or a < b, nondecreasing f unction of x, (36b)
lim 0 <h→ 0 FX (x + h) = FX (x), continuous f rom the right, (36c)
2.2. Example of a cumulative distribution function. Consider the following function
FX (x) =
1 + e−x^
Check condition 36a as follows.
lim x→ −∞ FX (x) = lim x→ −∞
1 + e−x^
= lim x→ ∞
1 + ex^
lim x→ ∞ FX (x) = lim x→ ∞
1 + e−x^
To check condition 36b differentiate the cdf as follows
d FX ( x ) dx
d
1 1 + e−x
dx
=
e−x ( 1 + e−x^ )^2
Condition 36c is satisfied because FX (x) is a continuous function.
2.3. Discrete and continuous random variables.
2.3.1. Discrete random variable. A random variable X will be said to be discrete if the range of X is countable, that is if it can assume only a finite or countably infinite number of values. Alternatively, a random variable is discrete if FX (x) is a step function of x.
2.3.2. Continuous random variable. A random variable X is continuous if FX (x) is a continuous func- tion of x.
2.4. Frequency (probability mass) function of a discrete random variable.
2.4.1. Definition of a frequency (discrete density) function. If X is a discrete random variable with the distinct values, x 1 , x 2 , · · · , xn, · · · , then the function denoted by p(·) and defined by
pX (x) =
P [X = xj ] x = xj , j = 1, 2 , ... , n, ... 0 x 6 = xj
is defined to be the frequency, discrete density, or probability mass function of X. We will often write fX (x) for pX (x) to denote frequency as compared to probability. A discrete probability distribution on R k^ is a probability measure P such that
FIGURE 1. Frequency Function for Tossing a Die
1 2 3 4 5 6 7 8 9
x
^1 6
^1 3
^1 2
^2 3
^5 6
1
f H x L
2.5.1. Alternative definition of continuous random variable. In section 2.3.2, we defined a random vari- able to be continuous if FX (x) is a continuous function of x. We also say that a random variable X is continuous if there exists a function f(·) such that
FX (x) =
∫ (^) x
−∞
f (u) du (46)
for every real number x. The integral in equation 46 is a Riemann integral evaluated from -∞ to a real number x.
2.5.2. Definition of a probability density frequency function (pdf). The probability density function, fX (x), of a continuous random variable X is the function f (·) that satisfies
FX (x) =
∫ (^) x
−∞
fX (u) du (47)
2.5.3. Properties of continuous density functions.
fX (x) ≥ 0 ∀x (48a) ∫ (^) ∞
−∞
fX (x) dx = 1, (48b)
Analogous to equation 42, we can write in the continuous case
P (X ǫ A) =
A
fX (x) dx (49)
where the integral is interpreted in the sense of Lebesgue.
Theorem 6. For a density function f X (x) defined over the set of all real numbers the following holds
P (a ≤ X ≤ b) =
∫ (^) b
a
fX (x) dx (50)
for any real constants a and b with a ≤ b. Also note that for a continuous random variable X the following are equivalent
P (a ≤ X ≤ b) = P (a ≤ X < b) = P (a < X ≤ b) = P (a < X < b) (51) Note that we can obtain the various probabilities by integrating the area under the density func- tion as seen in figure 2.
FIGURE 2. Area under the Density Function as Probability
f H x L
2.5.4. Example 1 of a continuous density function. Consider the following function
fX (x) =
k · e −^3 x^ f or x > 0 0 elsewhere
First we must find the value of k that makes this a valid density function. Given the condition in equation 48b we must have that
∫ (^) ∞
−∞
fX (x) dx =
0
k · e −^3 x^ dx = 1 (53)
FIGURE 3. Graph of Density Function x e−x
x
fHxL
This is represented by the area between the lines in figure 4. We can also find the distribution function in this case.
FX (x) =
∫ (^) x
0
t · e −^ t^ d t (61)
Make the u dv substitution as before to obtain
FX (x) = − t e−^ t^ |x 0 −
∫ (^) x
0
− e −^ t^ d t
= − t e−^ t^ |x 0 − e−^ t|x 0
= e−^ t^ (− 1 − t)|x 0
= e−^ x^ (− 1 − x) − e−^0 ( − 1 − 0)
= e−^ x^ (− 1 − x) + 1
= 1 − e−^ x^ (1 + x)
The distribution function is shown in figure 5.
Now consider the probability that (1 ≤ X ≤ 2)
FIGURE 4. P (1 ≤ X ≤ 2)
x
fHxL
P (1 ≤ X ≤ 2) = F (2) − F (1)
= 1 − e−^2 (1 + 2) − 1 + e−^1 (1 + 1)
= 2 e−^1 − 3 e−^2
= 0. 73575 − 0. 406
= 0. 32975
We can see this as the difference in the values of FX (x) at 1 and at 2 in figure 6
2.5.6. Example 3 of a continuous density function. Consider the normal density function given by
f ( x : μ, σ ) =
2 π σ^2
· e
− 1 2 (^ x − μ σ )
2 (64)
where μ and σ are parameters of the function. The shape and location of the density function depends on the parameters μ and σ. In figure 7 the diagram the density is drawn for μ = 0, and σ = 1 and σ = 2.
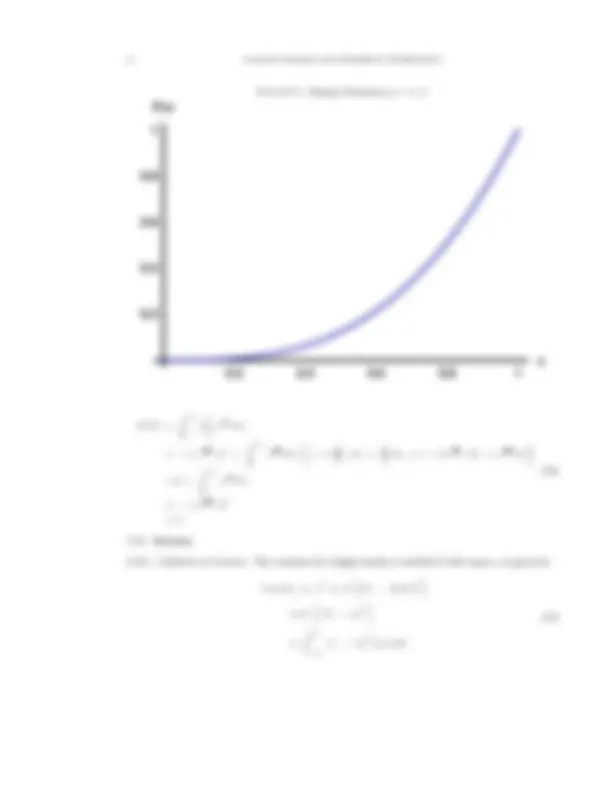
2.5.7. Example 4 of a continuous density function. Consider a random variable with density function given by
fX (x) =
(p + 1)xp^0 ≤ x ≤ 1 0 otherwise
FIGURE 6. P (1 ≤ X ≤ 2) using the Distribution Function
x
fHxL
The expectation of a random variable can also be defined using the Riemann-Stieltjes integral where F is a monotonically increasing function of X. Specifically
E(X) =
−∞
x dF (x) =
−∞
x dF (68)
2.7. Properties of expectation.
2.7.1. Constants.
E[a] ≡
−∞
a fX (x)dx
≡ a
−∞
fX (x)dx
≡ a
2.7.2. Constants multiplied by a random variable.
E[a X] ≡
−∞
a x fX (x)dx
≡ a
−∞
x fX (x)dx
≡ a E[X]
FIGURE 7. Normal Density Function
x
f H x L
2.7.3. Constants multiplied by a function of a random variable.
E[a g(X)] ≡
−∞
a g(x) fX (x)dx
≡ a
−∞
g(x) fX (x)dx
≡ a E[g(X)]
2.7.4. Sums of expected values. Let X be a continuous random variable with density function fX (x) and let g 1 (X), g 2 (X), g 3 (X), · · · , gk(X) be k functions of X. Also let c 1 , c 2 , c 3 , · · · ck be k constants. Then
E [c 1 g 1 (X) + c 2 g 2 (X) + · · · + ck gk(X) ] ≡ E [c 1 g 1 (X)] + E [c 2 g 2 (X)] + · · · + E [ck gk(X)] (72)
2.8. Example 1. Consider the density function
fX (x) =
(p + 1)xp^0 ≤ x ≤ 1 0 otherwise
where p is greater than -1. We can compute the E(X) as follows.