



NONLINEAR PROGRAMMING
LECTURE 4
CONVERGENCE ANALYSIS OF GRADIENT METHODS
LECTURE OUTLINE
• Gradient Methods - Choice of Stepsize
• Gradient Methods - Convergence Issues
Docsity.com



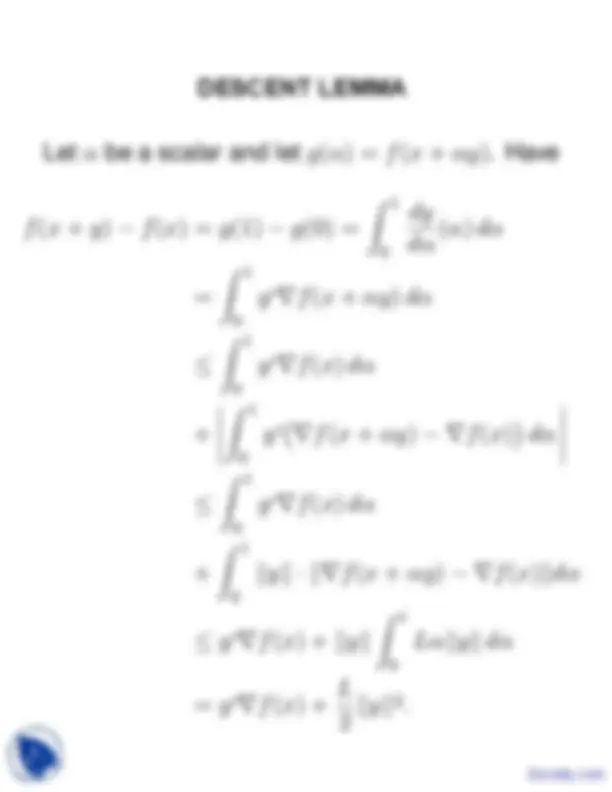


Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
These are the Lecture Slides of Nonlinear Programming which includes Convex Cost, Linear Constraints, Duality Theorem, Linear Programming Duality, Quadratic Programming Duality, Linear Inequality, Constrained Problem, Minimize, Feasible etc.Key important points are: Convergence Analysis of Gradient Methods, Gradient Methods, Choice of Stepsize, Convergence Issues, Minimization Rule, Limited Minimization Rule, Armijo Rule, Constant Stepsize, Diminishing Stepsize, Infinite Travel Condition
Typology: Slides
1 / 9

This page cannot be seen from the preview
Don't miss anything!
f (xk†+ αkdk) = min f (xk†+ αdk).† α≥ 0
σα∇f(xk^ )'dk α∇f(xk^ )'dk
0 α
Set of AcceptableStepsizes
× (^) β ×s s
UnsuccessfulTrials
Stepsize αk^ =^ β^2 s
f(xk^ + αd k^ ) - f(xk^ )
×
Stepsize
Start with s†and continue with βs, β^2 s, ..., until βms†falls within the set of α†with
f (x†k^ ) − f†(x†k†+ αdk^ ) ≥ −σα∇f†(x†k^ )′dk† .†
xk+1^ = xk†− αk(∇f (xk) + ek)
where ek†^ is an uncontrollable error vector
− ek†^ small relative to the gradient; i.e., for all k, ‖ek‖ <†‖∇f (xk)‖
Illustration of the descent ∇f(x property of the direction k (^) ) e k g k
gk†^ = ∇f†(xk^ ) + ek†.
− {ek} is bounded, i.e., for all k, ‖ek‖ ≤ δ,† where δ†is some scalar. − {ek} is proportional to the stepsize, i.e., for all k, ‖ek‖ ≤ qαk†,†where q†is some scalar. − {ek} are independent zero mean random vec- tors
For any subsequence {xk}k∈K that converges to a nonstationary point, the corresponding subse- quence {dk}k∈K is bounded and satisfies
lim sup ∇f (xk)′dk†^ <† 0 .† k→∞, k∈K
0 α
α∇f(xk^ )'dk^ + (1/2)α^2 L||dk^ ||^2
×
α∇f(xk^ )'dk
α = |∇L||df(xk k)'d|||2^ k|
f(xk^ + αd k^ ) - f(xk^ )
The idea of the convergence proof for a constant stepsize. Given xk†^ and the descent direction dk†, the cost differ- ence f†(xk†^ + αdk^ ) − f†(xk^ ) is majorized by α∇f†(xk^ )′dk†^ + 2 α^2 L‖dk^ ‖^2 (based on the Lipschitz assumption; see next slide). Minimization of this function over α†yields the step- size
α†= |∇f†(xk^ )′dk^ | L‖dk^ ‖^2
This stepsize reduces the cost function f† as well.
1
Let α†be a scalar and let g(α) = f (x†+ αy). Have ∫ (^) 1† dg f (x†+ y) − f (x) = g(1) − g(0) = dα†
(α) dα† ∫ 0† 1† = y′∇f (x†+ αy) dα† ∫^ 0† 1† ≤ y′∇f (x) dα† ∣^0 ∫ (^) 1† (^) ( ) ∣^ ∣
‖y‖^2 .†