Download Cunning Plan - Programming Languages - Slides | CS 4610 and more Study notes Programming Languages in PDF only on Docsity!
Lexical Analysis Lexical Analysis
Finite Automata Finite Automata
(Part 1 of 2) (Part 1 of 2)
Cool Demo?
Cunning Plan
- Informal Sketch of Lexical Analysis
- LA identifies tokens from input string
- (^) lexer : (char list) → (token list)
- Issues in Lexical Analysis
- Specifying Lexers
- Regular Expressions
- Examples
Fold Batter Lightly ...
- fold_left f a [1;...;n] == f (... (f (f a 1) 2)) n
- fold_left (fun a e -> e :: a) [] [1;2;3]
- fold_left (fun a e -> a @ [e]) [] [1;2;3]
- fold_right f [1;...;n] b == f 1 (f 2 (... (f n b)))
- fold_right (fun a e -> e :: a) [1;2;3] []
- fold_right (fun e a -> a @ [e]) [1;2;3] []
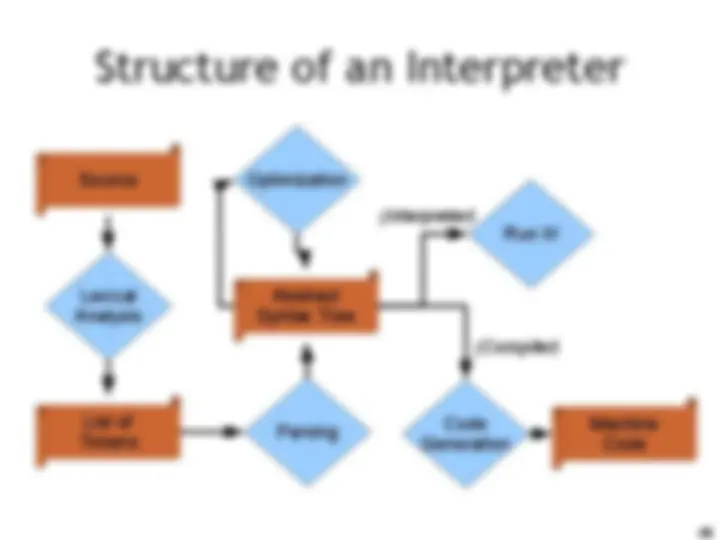
Structure of an Interpreter Source Lexical Analysis List of Tokens Abstract Syntax Tree Parsing Optimization Run It! Code Generation Machine Code (Interpreter) (Compiler)
What's a Token?
- Output of lexical analysis is a list of tokens
- A token is a syntactic category
- In English:
- noun, verb, adjective, ...
- In a programming language:
- Identifier, Integer, Keyword, Whitespace, ...
- Parser relies on token distinctions:
- e.g., identifiers are treated differently than keywords
Tokens
- Tokens correspond to sets of strings.
- (^) Identifier : strings of letters or digits, starting
with a letter
- Integer : a non-empty string of digits
- Keyword : “else” or “if” or “begin” or ...
- Whitespace : a non-empty sequence of blanks,
newlines, and/or tabs
- OpenPar : a left-parenthesis
Example
- Recall:
- if (i == j)\n\tz = 0;\nelse\n\tz = 1;
- Token-lexeme pairs returned by the lexer:
- <Keyword, “if”>
- <Whitespace, “ ”>
- <OpenPar, “(”>
- <Identifier, “i”>
- <Whitespace, “ ”>
- <Relation, “==”>
- <Whitespace, “ ”>
- ...
Lexical Analyzer: Implementation
- The lexer usually discards “uninteresting”
tokens that don't contribute to parsing.
- Examples: Whitespace, Comments
- Exception: which language cares about whitespace?
- Question: What happens if we remove all
whitespace and comments prior to lexing?
Still Needed
- A way to describe the lexemes of each token
- Recall: lexeme = “the substring corresponding to the token”
- A way to resolve ambiguities
- Is if two variables i and f?
- Is == two equal signs = =?
Languages
- Definition. Let Σ be a set of characters. A language over Σ is a set of strings of characters drawn from Σ. Σ is called the alphabet.
Notation
- Languages are sets of strings
- (^) We need some notation for specifying which
sets we want
- that is, which strings are in the set
- For lexical analysis we care about regular
languages , which can be described using
regular expressions.
Regular Expressions
- Each regular expression is a notation for a
regular language (a set of words)
- You'll see the exact notation in minute!
- If A is a regular expression then we write L(A)
to refer to the language denoted by A
Compound Regular Expressions
- Union
- (^) L(A | B) = { s | s ∈ L(A) or s ∈ L(B) }
- Examples:
- L('if' | 'then' | 'else') = { “if”, “then”, “else” }
- L('0'|'1'|'2'|'3'|'4'|'5'|'6'|'7'|'8'|'9') = what?
- Fun Example:
- L( ('0'|'1') ('0'|'1') ) = {“00”,”01”,”10”,”11”}
Starz!
- So far we have only finite languages
- Iteration: A*
- (^) L(A*) = {“”} ∪ L(A) ∪ L(AA) ∪ L(AAA) ...
- Examples:
- L('0'*) = {“”, “0”, “00”, “000”, “0000”, ... }
- L('1''0'*) = {“1”, “10”, “100”, “1000”, ...}
- Empty: ε