



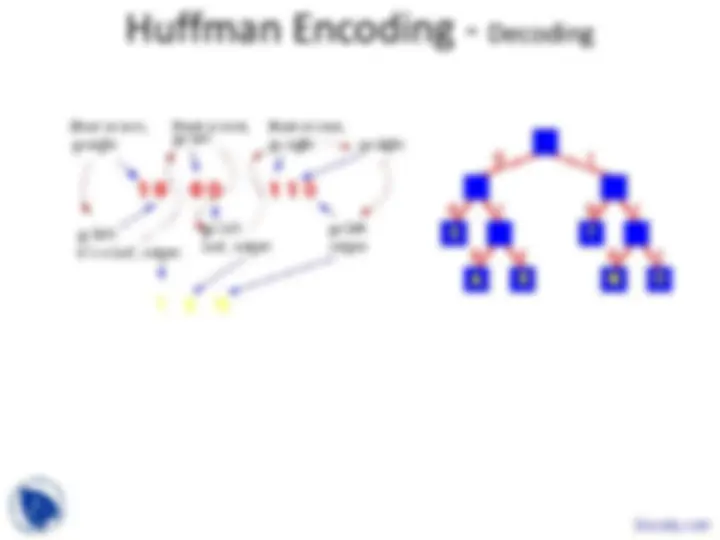
Data Compressor---Huffman
Encoding and Decoding
Docsity.com

























Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Some concept of Data Structures are Abstract, Balance Factor, Complete Binary Tree, Dynamically, Storage, Implementation, Sequential Search, Advanced Data Structures, Graph Coloring Two, Insertion Sort. Main points of this lecture are: Data Compressor, Encoding and Decoding, Huffman, Compression, Files and Messages, Wasting, Smallest Number, Arbitrary Piece, Frequency, Short Bit Strings
Typology: Slides
1 / 44

This page cannot be seen from the preview
Don't miss anything!
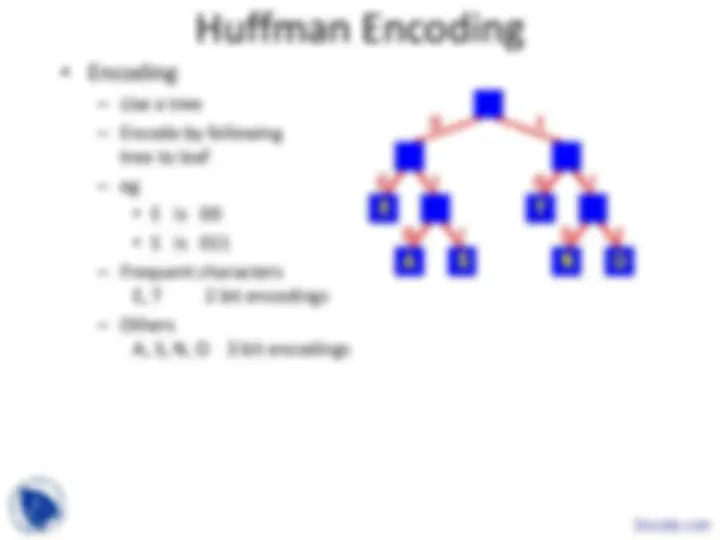
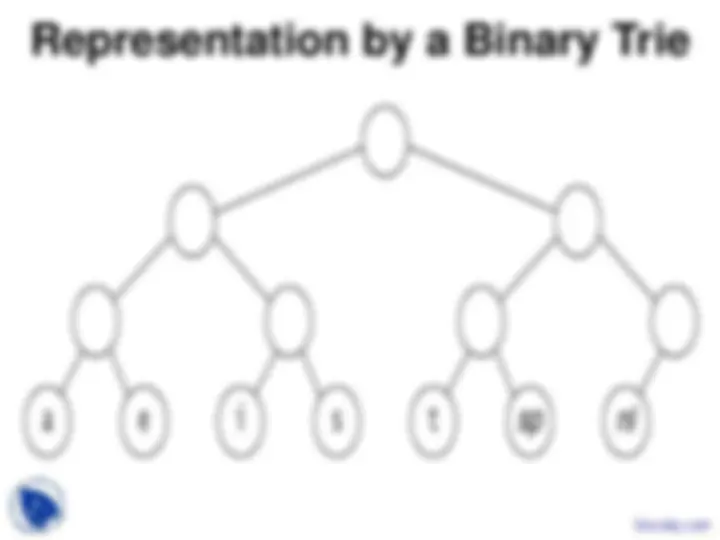
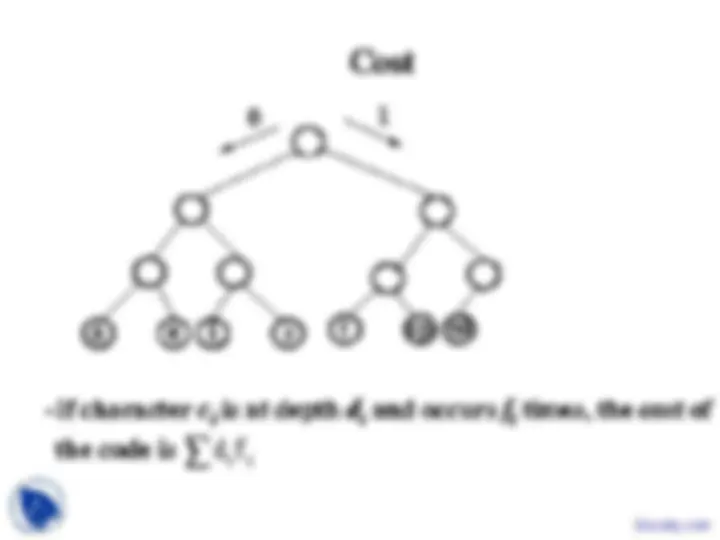
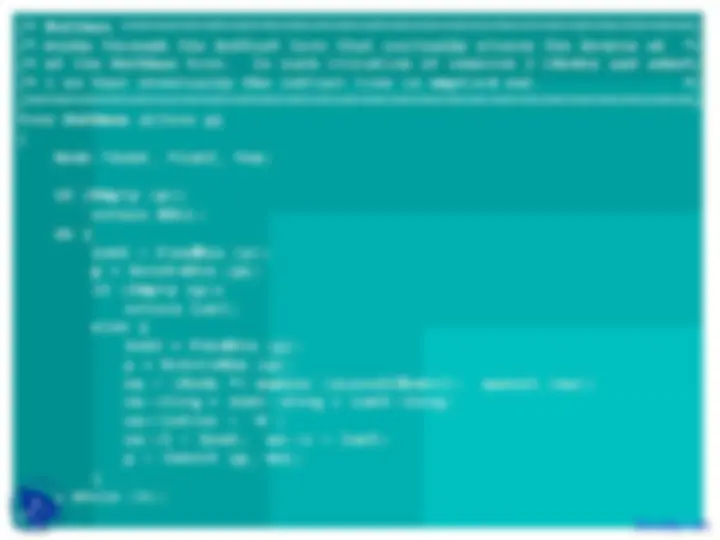
asking which characters should appear in the
left and right subtrees and trying to build the
tree from the top down.
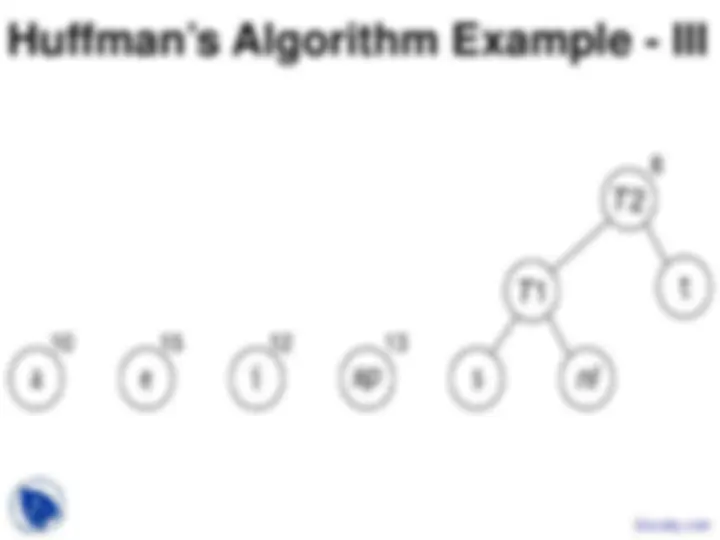
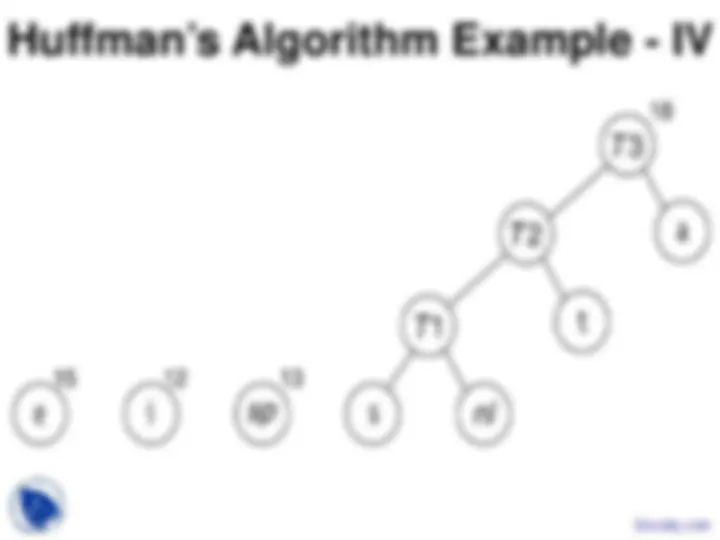
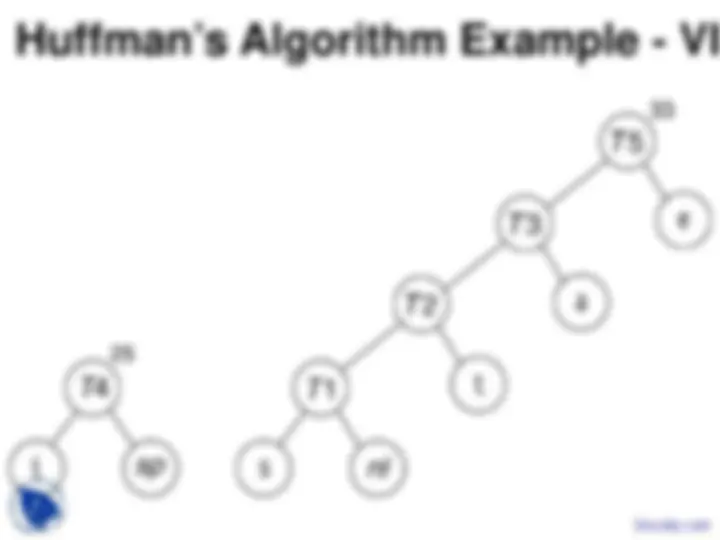
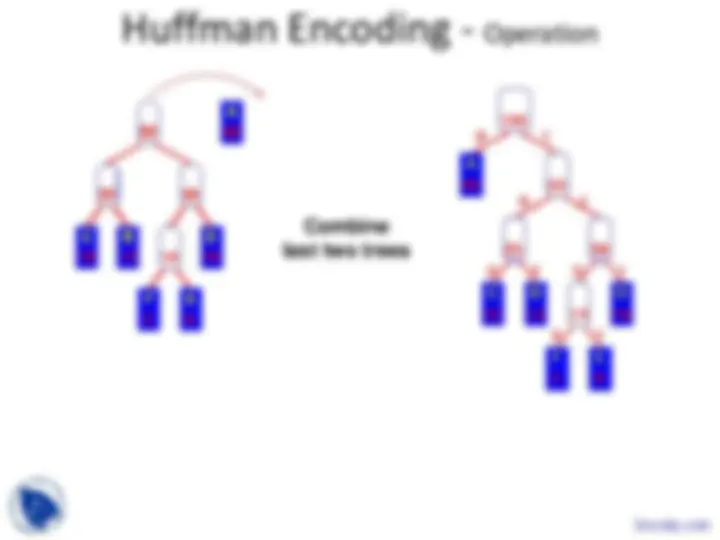
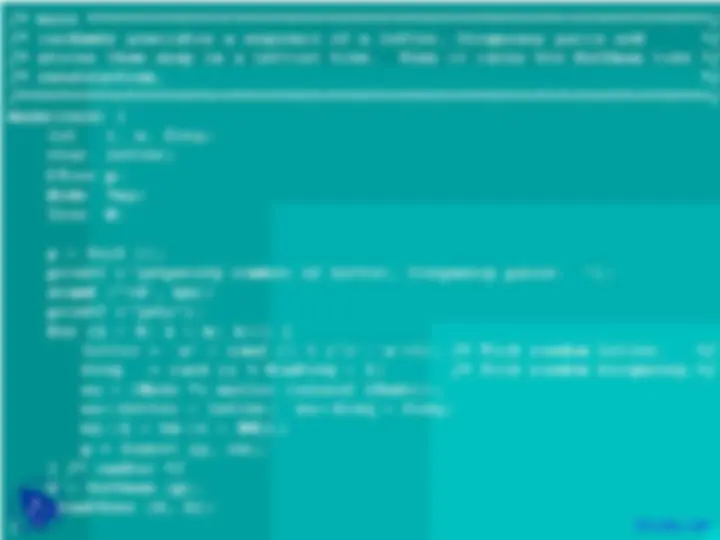
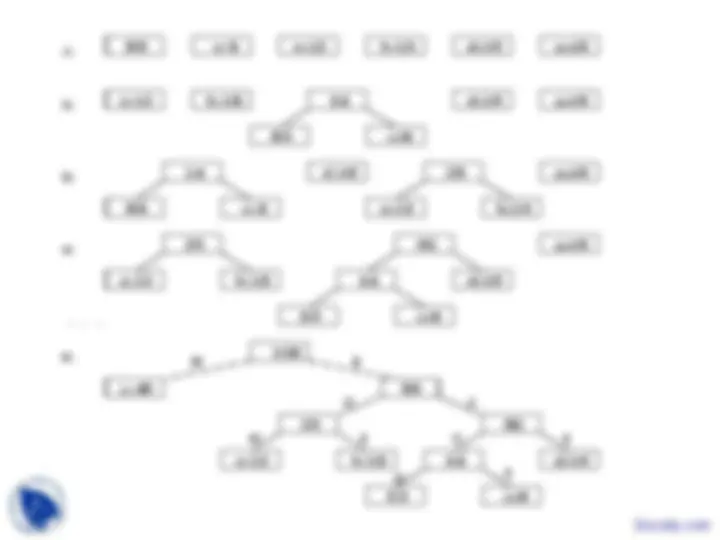
n sub-trees and starts by combining the two
least weight nodes into a tree which is
assigned the sum of the two leaf node weights
as the weight for its root node.