Download Data Mining Additional Discussion and more Cheat Sheet Technology in PDF only on Docsity!
Classifying
Streaming Data
Week 8-
What is Streaming Data?
- (^) Data arriving continuously and rapidly
- (^) Example of Streaming data are :
- (^) Internet of things
- (^) Social Media
Key Challenges :
- (^) High velocity
- (^) Memory constraints
- (^) Concept drift
- (^) Limited access
Challenges in Classifying Streaming Data
- (^) High Velocity : Need for real-time or near-real-time processing.
- (^) Memory Constraints : Cannot store entire datasets.
- (^) Concept Drift : Data distributions change over time.
- (^) Imbalanced Data : Uneven class distributions in streams.
Popular Algorithms
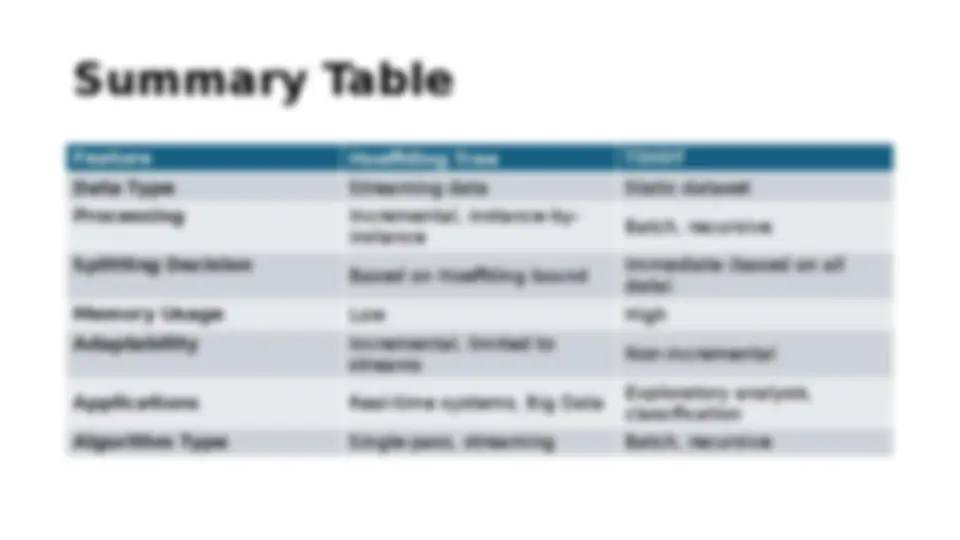
- (^) Hoeffding Tree (H-Tree) : Incremental decision tree with low memory requirements.
- (^) Naïve Bayes :Lightweight probabilistic classifier.
- (^) Stochastic Gradient Descent (SGD) :Efficient for online updates.
- (^) Online Random Forest :Adaptive ensemble of decision trees.
Handling Concept Drift
- (^) Concept Drift
- (^) Defined : Changes in data distribution affecting model performance.
- (^) Strategies :
- (^) Sliding Window: Focus on recent data.
- (^) Weighted Learning: Prioritize newer data.
- (^) Drift Detectors: Detect and adapt to drift (e.g., DDM, EDDM).
Applications
- (^) Fraud Detection :
- (^) Analyzing live transactions for fraud.
- (^) IoT Monitoring :
- (^) Real-time sensor event classification.
- (^) Social Media Analytics :
- (^) Sentiment or trend analysis.
- (^) Traffic Monitoring :
- (^) Predicting congestion or accidents.
Tools for Implementation
- (^) MOA : Massive Online Analysis framework.
- (^) Apache Flink : Distributed processing for streams.
- (^) scikit-multiflow : Python library for streaming data.
- (^) River : Lightweight library for online machine learning.
Hoeffding Tree (H-Tree)
Hoeffding Tree (H-Tree)
- (^) also known as an H-Tree or Very Fast Decision Tree (VFDT)
- (^) a type of decision tree algorithm designed specifically for streaming data.
- (^) It is a machine learning model that can efficiently handle large datasets by incrementally learning from a stream of data, rather than requiring all data to be available at once.
Characteristics of Hoeffding Tree
- (^) Hoeffding Bound :
- (^) The algorithm uses the Hoeffding bound (a statistical measure) to decide when to split a node in the tree.
- (^) The bound provides a guarantee on the minimum number of samples required to make confident decisions about the best attribute to split on.
Characteristics of Hoeffding Tree
- (^) Efficiency :
- (^) Suitable for streaming and large datasets where storing the entire dataset in memory is impractical.
- (^) Works efficiently even when the data arrives at high velocity.
Algorithm Overview (H-Tree)
- (^) Node Splitting :
- (^) Nodes are split based on the best attribute determined using a splitting criterion (e.g., information gain or Gini index).
- (^) Instead of calculating the criterion over the entire dataset, the Hoeffding bound ensures that the decision is statistically sound with a subset of the data.
Algorithm Overview (H-Tree)
- (^) Attributes and Statistics :
- (^) The algorithm maintains sufficient statistics (e.g., counts, sums) at each node to compute splitting criteria.
- (^) Only attributes that meet the Hoeffding bound confidence level are used to split.