Download Weka Data Analysis and Predictive Modeling for Information Technology Students and more Lab Reports Data Mining in PDF only on Docsity!
DATA WAREHOUSING AND DATA MINING
LAB (R18A1281)
LAB MANUAL AND RECORD
B.TECH
(III YEAR – II SEM)
DEPARTMENT OF INFORMATION TECHNOLOGY
MALLA REDDY COLLEGE OF ENGINEERING &
TECHNOLOGY
(Autonomous Institution – UGC, Govt. of India)
Recognized under 2(f) and 12 (B) of UGC ACT 1956 Affiliated to JNTUH,Hyderabad, Approved by AICTE - Accredited by NBA & NAAC – ‘A’ Grade - ISO 9001: Certified) Maisammaguda, Dhulapally (Post Via. Hakimpet), Secunderabad – 500100, Telangana State, India
DEPARTMENT OF INFORMATION TECHNOLOGY
Vision
➢ To achieve high quality education in technical education that provides the
skills and attitude to adapt to the global needs of the Information technology sector, through academic and research excellence. Mission
➢ To equip the students with the cognizance for problem solving and to improve
the teaching learning pedagogy by using innovative techniques.
➢ To strengthen the knowledge base of the faculty and students with the
motivation towards possession of effective academic skills and relevant research experience.
➢ To promote the necessary moral and ethical values among the engineers ,for
the betterment of the society.
PROGRAM SPECIFIC OUTCOMES (PSOs) After the completion of the course, B. Tech Information Technology, the graduates will have the following Program Specific Outcomes:
- Fundamentals and critical knowledge of the Computer System:- Able to Understand the working principles of the computer System and its components , Apply the knowledge to build, asses, and analyze the software and hardware aspects of it.
- The comprehensive and Applicative knowledge of Software Development: Comprehensive skills of Programming Languages, Software process models, methodologies, and able to plan, develop, test, analyze, and manage the software and hardware intensive systems in heterogeneous platforms individually or working in teams.
- Applications of Computing Domain & Research: Able to use the professional, managerial, interdisciplinary skill set, and domain specific tools in development processes, identify the research gaps, and provide innovative solutions to them.
PROGRAM OUTCOMES (POs) Engineering Graduates will be able to:
- Engineering knowledge : Apply the knowledge of mathematics, science, engineering fundamentals, and an engineering specialization to the solution of complex engineering problems.
- Problem analysis : Identify, formulate, review research literature, and analyze complex engineering problems reaching substantiated conclusions using first principles of mathematics, natural sciences, and engineering sciences.
- Design / development of solutions : Design solutions for complex engineering problems and design system components or processes that meet the specified needs with appropriate consideration for the public health and safety, and the cultural, societal, and environmental considerations.
- Conduct investigations of complex problems : Use research-based knowledge and research methods including design of experiments, analysis and interpretation of data, and synthesis of the information to provide valid conclusions.
- Modern tool usage : Create, select, and apply appropriate techniques, resources, and modern engineering and IT tools including prediction and modeling to complex engineering activities with an understanding of the limitations.
- The engineer and society : Apply reasoning informed by the contextual knowledge to assess societal, health, safety, legal and cultural issues and the consequent responsibilities relevant to the professional engineering practice.
- Environment and sustainability : Understand the impact of the professional engineering solutions in societal and environmental contexts, and demonstrate the knowledge of, and need for sustainable development.
- Ethics : Apply ethical principles and commit to professional ethics and responsibilities and norms of the engineering practice.
- Individual and team work : Function effectively as an individual, and as a member or leader in diverse teams, and in multidisciplinary settings.
- Communication: Communicate effectively on complex engineering activities with the engineering community and with society at large, such as, being able to comprehend and write effective reports and design documentation, make effective presentations, and give and receive clear instructions.
- Project management and finance : Demonstrate knowledge and understanding of the engineering and management principles and apply these to one’s own work, as a member and leader in a team, to manage projects and in multi disciplinary environments.
- Life- long learning : Recognize the need for, and have the preparation and ability to engage in independent and life-long learning in the broadest context of technological change.
COURSE NAME: DATA WAREHOUSING AND DATA MINING LAB COURSE CODE: R18A COURSE OBJECTIVES:
- Learn how to build a data warehouse and query it (using open source tools like Pentaho Data Integration Tool, Pentaho Business Analytics).
- Learn to perform data mining tasks using a data mining toolkit (such as open source WEKA).
- Understand the data sets and data preprocessing.
- Demonstrate the working of algorithms for data mining tasks such association rule mining, classification, clustering and regression.
- Exercise the data mining techniques with varied input values for different parameters.
- To obtain Practical Experience Working with all real data sets. COURSE OUTCOMES:
- Ability to add mining algorithms as a component to the existing tools
- Demonstrate the classification, clustering and etc. in large data sets.
- Ability to apply mining techniques for realistic data. MAPPING OF COURSE OUTCOMES WITH PROGRAM OUTCOMES: COURSE OUTCOMES PO1^ PO2^ PO3^ PO4^ PO5^ PO6^ PO7^ PO8^ P09^ PO10^ PO
- Ability to add mining algorithms as a component to the exiting tools.
- Ability to apply mining techniques for realistic data.
DATAWARE HOUSE TOOLS
Cloudera Teradata Oracle TabLeau OPEN SOURCE DATA MINING TOOLS WEKA Orange KNIME R-Programming
Information Technology Page 1 Experiment 1: Installation of WEKA Tool Aim: A. Investigation the Application interfaces of the Weka tool. Introduction: Introduction Weka (pronounced to rhyme with Mecca) is a workbench that contains a collection of visualization tools and algorithms for data analysis and predictive modeling, together with graphical user interfaces for easy access to these functions. The original non-Java version of Weka was a Tcl/Tk front-end to (mostly third-party) modeling algorithms implemented in other programming languages, plus data preprocessing utilities in C, and Make file-based system for running machine learning experiments. This original version was primarily designed as a tool for analyzing data from agricultural domains, but the more recent fully Java-based version (Weka 3), for which development started in 1997, is now used in many different application areas, in particular for educational purposes and research. Advantages of Weka include: ▪ Free availability under the GNU General Public License. ▪ Portability, since it is fully implemented in the Java programming language and thus runs on almost any modern computing platform ▪ A comprehensive collection of data preprocessing and modeling techniques ▪ Ease of use due to its graphical user interfaces Description: Open the program. Once the program has been loaded on the user‟s machine it is opened by navigating to the programs start option and that will depend on the user‟s operating system. Figure 1.1 is an example of the initial opening screen on a computer. There are four options available on this initial screen:
Information Technology Page 2 Fig: 1.1 Weka GUI
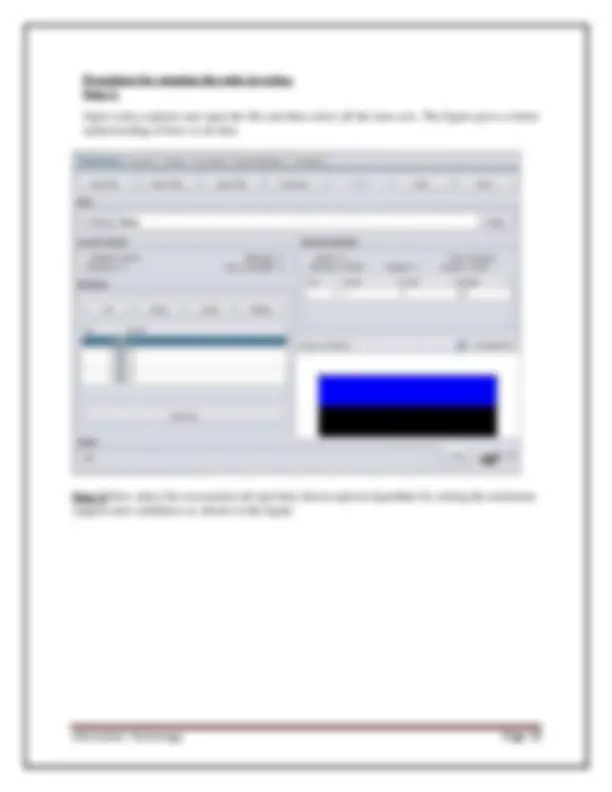
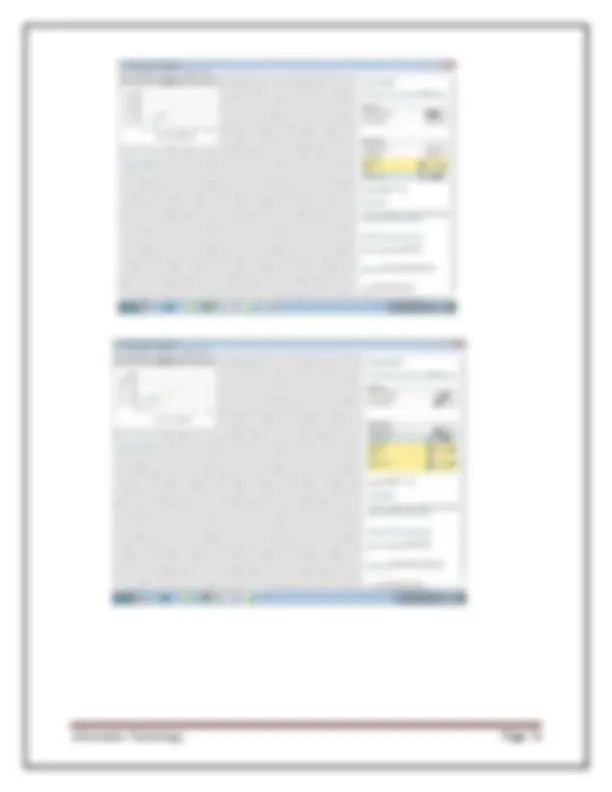
1. Explorer - the graphical interface used to conduct experimentation on raw data After clicking the Explorer button the weka explorer interface appears. Fig: 1.2 Pre-processor
Information Technology Page 4 Inside the weka explorer window there are six tabs:
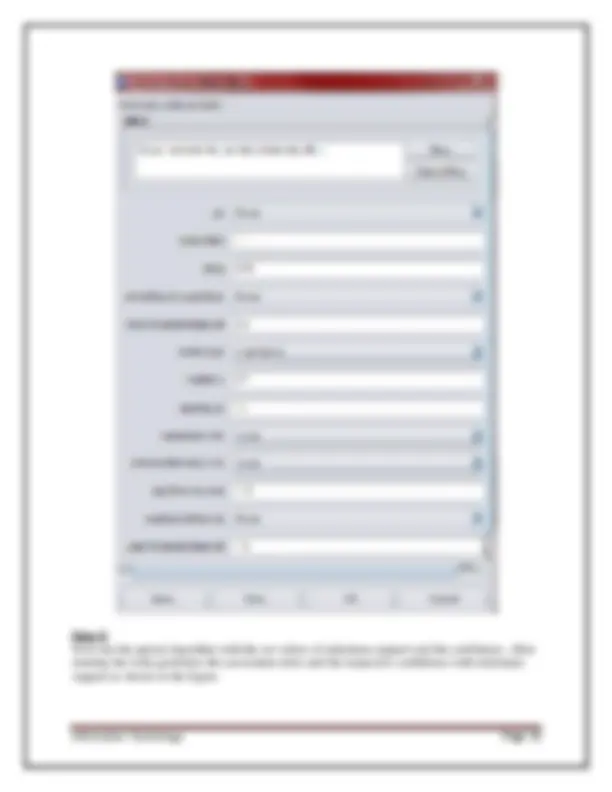
1. Preprocess- used to choose the data file to be used by the application. Open File - allows for the user to select files residing on the local machine or recorded medium Open URL - provides a mechanism to locate a file or data source from a different location specified by the user Open Database - allows the user to retrieve files or data from a database source provided by user 2. Classify- used to test and train different learning schemes on the preprocessed data file under experimentation Fig: 1.3 choosing Zero set from classify Again there are several options to be selected inside of the classify tab. Test option gives the user the choice of using four different test mode scenarios on the data set.
- Use training set
- Supplied training set
- Cross validation
- Split percentage 3. Cluster- used to apply different tools that identify clusters within the data file. The Cluster tab opens the process that is used to identify commonalties or clusters of occurrences within the data set and produce information for the user to analyze.
Information Technology Page 5
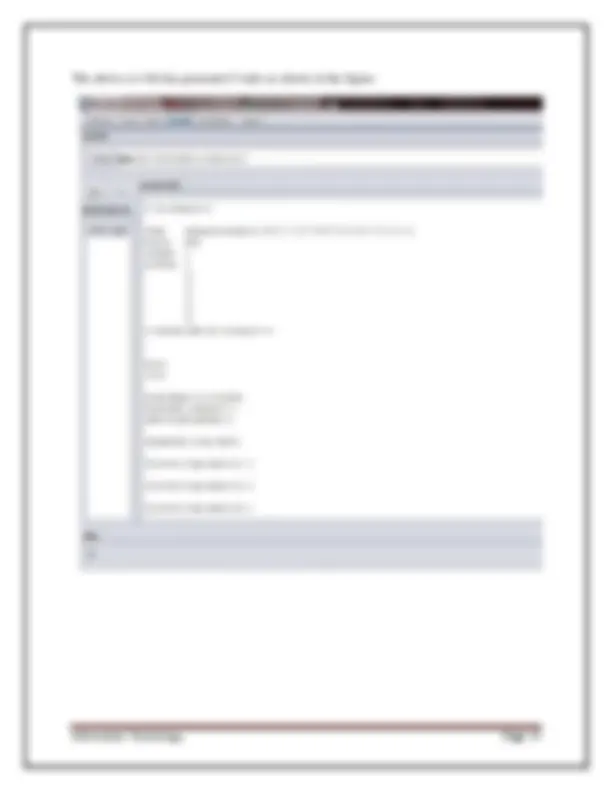
4. Association- used to apply different rules to the data file that identify association within the data. The associate tab opens a window to select the options for associations within the dataset.
Information Technology Page 7
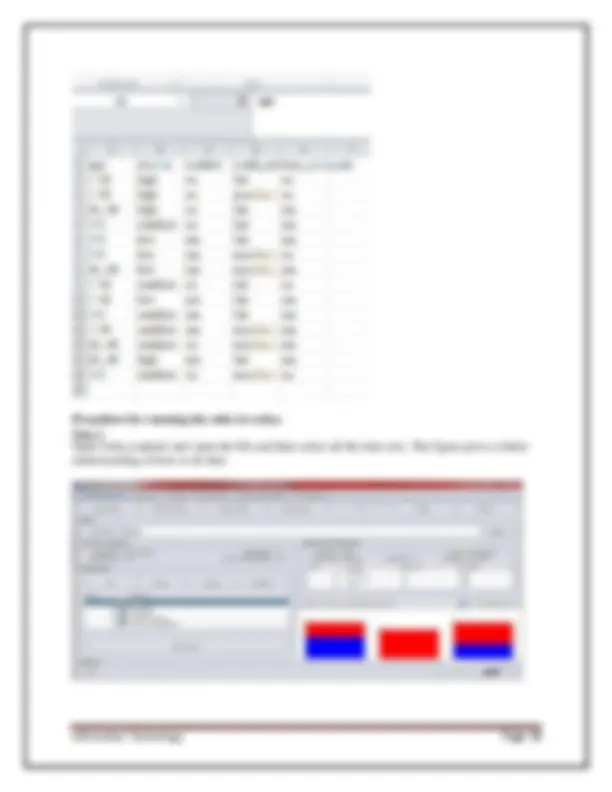
3. Knowledge Flow - basically the same functionality as Explorer with drag and drop functionality. The advantage of this option is that it supports incremental learning from previous results 4. Simple CLI - provides users without a graphic interface option the ability to execute commands from a terminal window. b. Explore the default datasets in weka tool. Click the “ Open file… ” button to open a data set and double click on the “ data ” directory. Weka provides a number of small common machine learning datasets that you can use to practiceon. Select the “ iris.arff ” file to load the Iris dataset. Fig: 1.7 Different Data Sets in weka References: [1] Witten, I.H. and Frank, E. (2005) Data Mining: Practical machine learning tools and techniques. 2nd edition Morgan Kaufmann, San Francisco. [2] Ross Quinlan (1993). C4.5: Programs for Machine Learning, Morgan Kaufmann Publishers, San Mateo, CA. [3] CVS–http://weka.sourceforge.net/wiki/index.php/CVS [4] Weka Doc–http://weka.sourceforge.net/wekadoc/ Exercise: 1. Normalize the data using min-max normalization
Information Technology Page 8 Record Notes
- Information Technology Page
- Information Technology Page
- Information Technology Page
Information Technology Page 11 Experiment 2.Creating new ARFF file Aim: Creating a new ARFF file An ARFF (Attribute-Relation File Format) file is an ASCII text file that describes a list of instances sharing a set of attributes. ARFF files were developed by the Machine Learning Project at the Department of Computer Science of The University of Waikato for use with the Weka machine learning software in WEKA, each data entry is an instance of the java class weka.core. Instance, and each instance consists of a For loading datasets in WEKA, WEKA can load ARFF files. Attribute Relation File Format has two sections:
- The Header section defines relation (dataset) name, attribute name, and type.
- The Data section lists the data instances. The figure above is from the textbook that shows an ARFF file for the weather data. Lines beginning with a % sign are comments. And there are three basic keywords: