


Data Mining
CS57300 / STAT 59800-024
Purdue University
February 5, 2009
1
Predictive modeling: representation
2



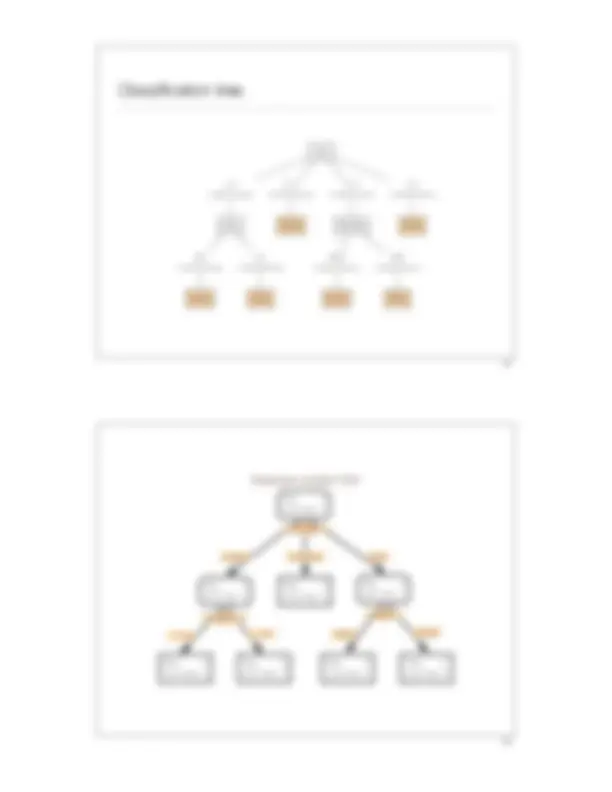



Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
This document from purdue university, cs57300 / stat 59800-024, discusses predictive modeling in data mining. The components of data mining, including task specification, data representation, knowledge representation, learning technique, and inference technique. It also differentiates between descriptive and predictive modeling and provides examples of predictive modeling approaches such as classification and regression. The document also touches upon knowledge representation and modeling approaches.
Typology: Study notes
1 / 12

This page cannot be seen from the preview
Don't miss anything!
Purdue University February 5, 2009 1
13
15
19
Y
21