



Data Mining & Machine Learning
CS37300
Purdue University
August 23, 2022
Bruno Ribeiro


















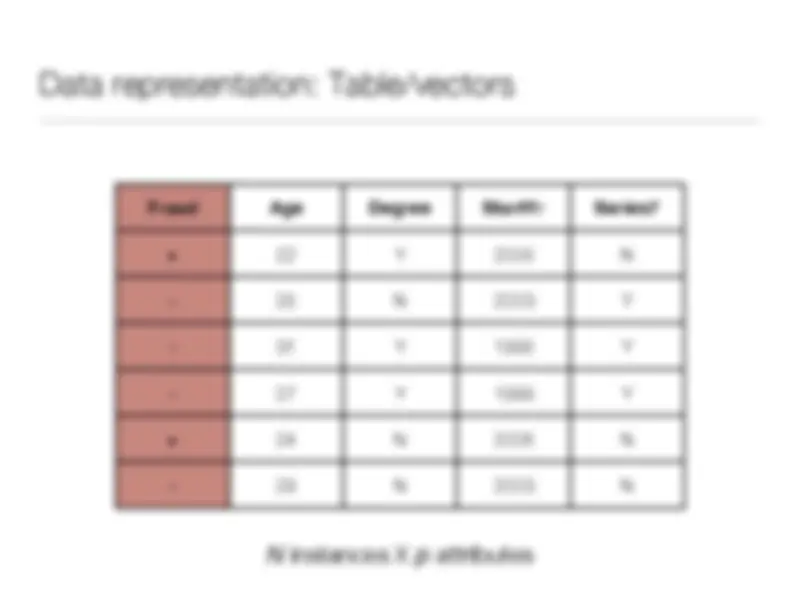
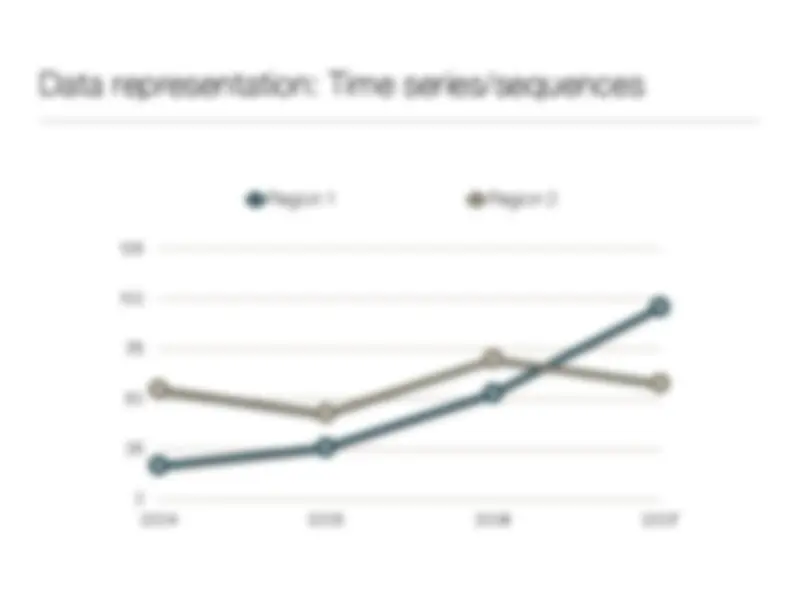
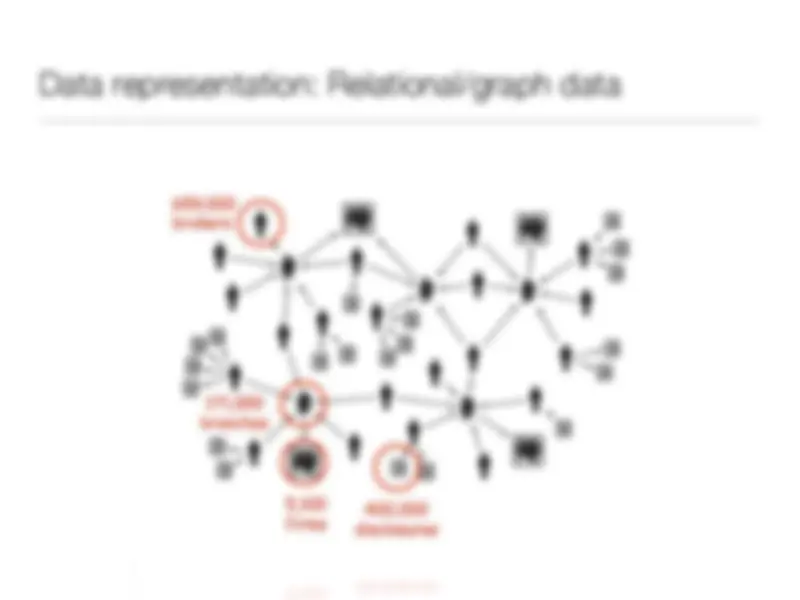



















Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
An overview of the CS37300 course on Data Mining & Machine Learning at Purdue University. It includes information on the syllabus, textbooks, workload, exams, computing resources, and Python resources. The document also explains the machine learning process, elements of data mining & machine learning algorithms, and provides an example of survival bias. It is a useful resource for students interested in data mining, data science, and machine learning.
Typology: Lecture notes
1 / 55

This page cannot be seen from the preview
Don't miss anything!
CS3 7300
Purdue University
August 2 3 , 20 22
Bruno Ribeiro
our website
assignments in python
science, and machine learning
Brightspace: https://purdue.brightspace.com/d2l/home/ 599255
average)
automatically counted as a zero grade (i.e., discarded from the average).
Additional extensions (beyond one missed homework) will be granted if
the documented emergency persists for 2+ homeworks.
reasons since, if an emergency happens, the student will have two zero
grades and one of them will count towards the average.
https://www.cs.purdue.edu/homes/ribeirob/courses/Fall2022/howto/cluster-how-to.html
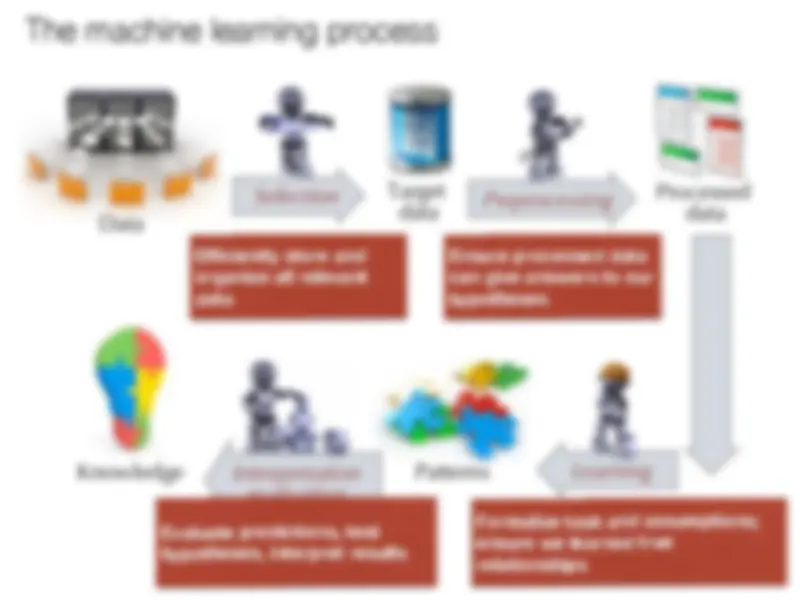
Processed
data
Target
data
Data
Selection
Preprocessing
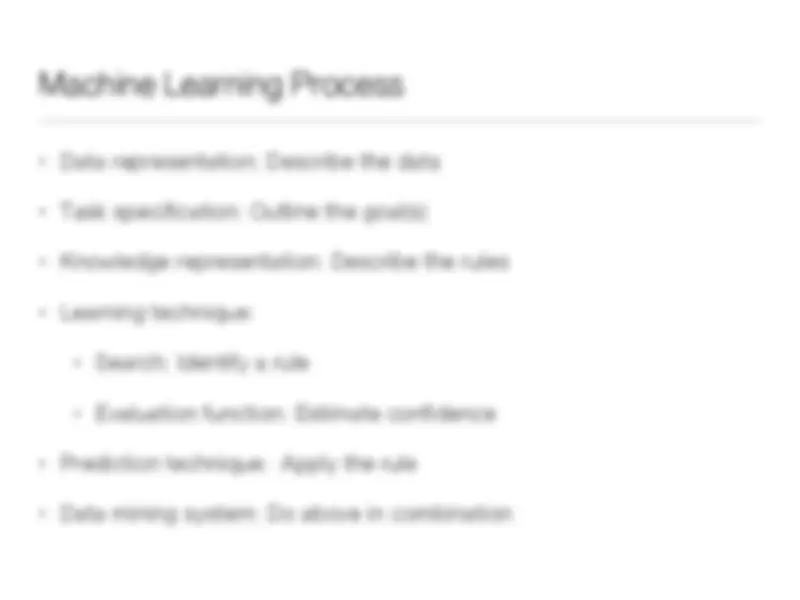
Learning Patterns Interpretation
evaluation
Knowledge
knowledge
changes
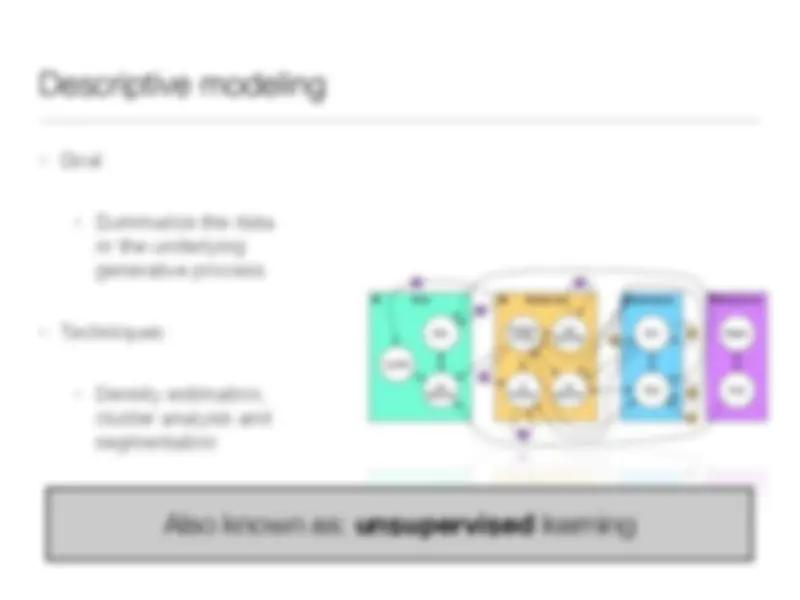
probabilistic dependence