Download Data Preprocessing - Data Warehousing - Lecture Slide and more Slides Data Warehousing in PDF only on Docsity!
Data Preprocessing
Chapter 3: Data Preprocessing
Why preprocess the data?
Data cleaning
Data integration and transformation
Data reduction
Discretization and concept hierarchy generation
Summary
Multi-Dimensional Measure of Data
Quality
A well-accepted multidimensional view:
- Accuracy
- Completeness
- Consistency
- Timeliness
- Believability
- Value added
- Interpretability
- Accessibility
Broad categories:
- intrinsic, contextual, representational, and accessibility.
Major Tasks in Data Preprocessing
Data cleaning
- Fill in missing values, smooth noisy data, identify or remove outliers, and resolve inconsistencies
Data integration
- Integration of multiple databases, data cubes, or files
Data transformation
- Normalization and aggregation
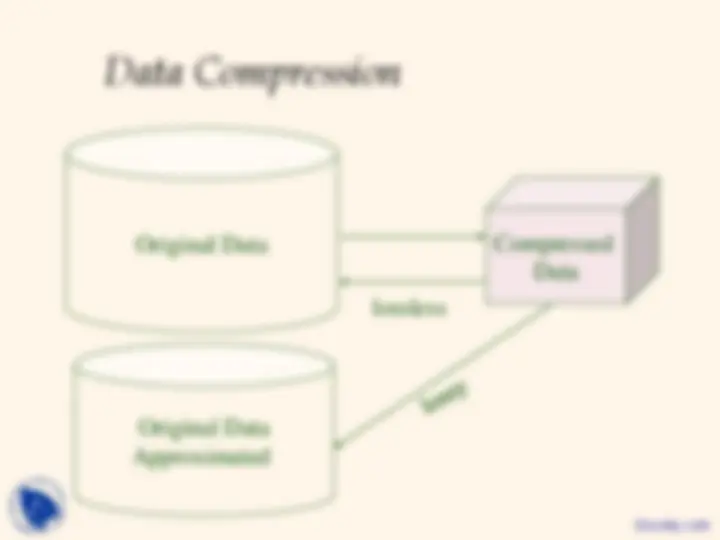
Data reduction
- Obtains reduced representation in volume but produces the same or similar analytical results
Data discretization
- Part of data reduction but with particular importance, especially for numerical data
Data Cleaning
Data cleaning tasks
- Fill in missing values
- Identify outliers and smooth out noisy data
- Correct inconsistent data
Missing Data
Data is not always available
- E.g., many tuples have no recorded value for several attributes, such as customer income in sales data
Missing data may be due to
- equipment malfunction
- inconsistent with other recorded data and thus deleted
- data not entered due to misunderstanding
- certain data may not be considered important at the time of entry
- not register history or changes of the data
Missing data may need to be inferred.
How to Handle Missing
Data?
Ignore the tuple: usually done when class label is missing (assuming
the tasks in classification—not effective when the percentage of
missing values per attribute varies considerably.
Fill in the missing value manually: tedious + infeasible?
Use a global constant to fill in the missing value: e.g., ―unknown‖, a
new class?!
Use the attribute mean to fill in the missing value
Use the attribute mean for all samples belonging to the same class to
fill in the missing value: smarter
Use the most probable value to fill in the missing value: inference-
based such as Bayesian formula or decision tree
Noisy Data
Noise: random error or variance in a measured variable
Incorrect attribute values may be due to
- faulty data collection instruments
- data entry problems
- data transmission problems
- technology limitation
- inconsistency in naming convention
Other data problems which requires data cleaning
- duplicate records
- incomplete data
- inconsistent data
How to Handle Noisy Data?
Binning method:
- first sort data and partition into (equi-depth) bins
- then one can smooth by bin means, smooth by bin
median, smooth by bin boundaries, etc.
Clustering
- detect and remove outliers
Combined computer and human inspection
- detect suspicious values and check by human
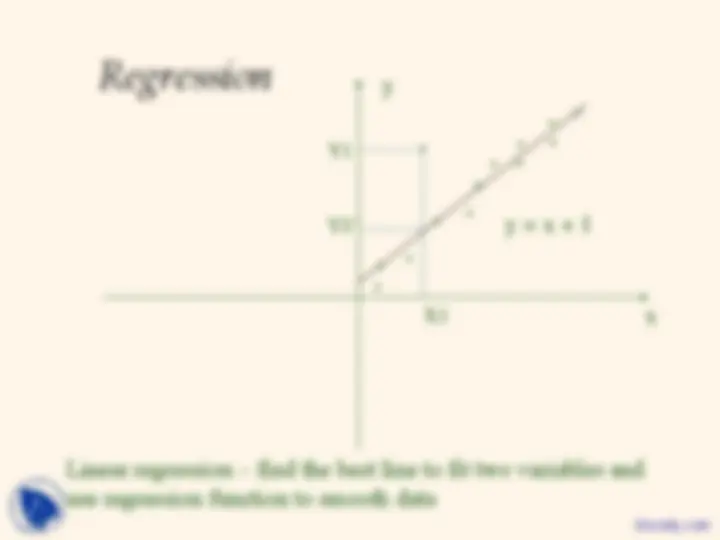
Regression
- smooth by fitting the data into regression functions
Simple Discretization Methods: Binning
Equal-width (distance) partitioning:
- It divides the range into N intervals of equal size:
uniform grid
- if A and B are the lowest and highest values of the
attribute, the width of intervals will be: W = ( B - A )/ N.
- The most straightforward
- But outliers may dominate presentation
- Skewed data is not handled well.
Equal-depth (frequency) partitioning:
- It divides the range into N intervals, each containing
approximately same number of samples
- Good data scaling
- Managing categorical attributes can be tricky.
Binning Methods for Data
Smoothing (continued)
Sorted data for price (in dollars): 4, 8, 9, 15, 21, 21, 24, 25, 26, 28, 29, 34
Partition into (equi-depth) bins:
- Bin 1: 4, 8, 9, 15
- Bin 2: 21, 21, 24, 25
- Bin 3: 26, 28, 29, 34
- Bin 1: 9, 9, 9, 9
- Bin 2: 23, 23, 23, 23
- Bin 3: 29, 29, 29, 29
- Smoothing by bin boundaries:
- Bin 1: 4, 4, 4, 15
- Bin 2: 21, 21, 25, 25
- Bin 3: 26, 26, 26, 34
Cluster Analysis
Allows detection and removal of outliers
Data Integration
Data integration:
- combines data from multiple sources into a coherent store
Schema integration
- integrate metadata from different sources
- Entity identification problem: identify real world entities from multiple data sources, e.g., A.cust-id B.cust-#
Detecting and resolving data value conflicts
- for the same real world entity, attribute values from different sources are different
- possible reasons: different representations, different scales, e.g., metric vs. British units
Handling Redundant
Data in Data Integration
Redundant data occur often when integration of multiple
databases
- The same attribute may have different names in different databases
- One attribute may be a ―derived‖ attribute in another table, e.g., annual revenue
Redundant data may be able to be detected by
correlational analysis
Careful integration of the data from multiple sources
may help reduce/avoid redundancies and
inconsistencies and improve mining speed and quality